Course
Why ML Strategy

F1 score
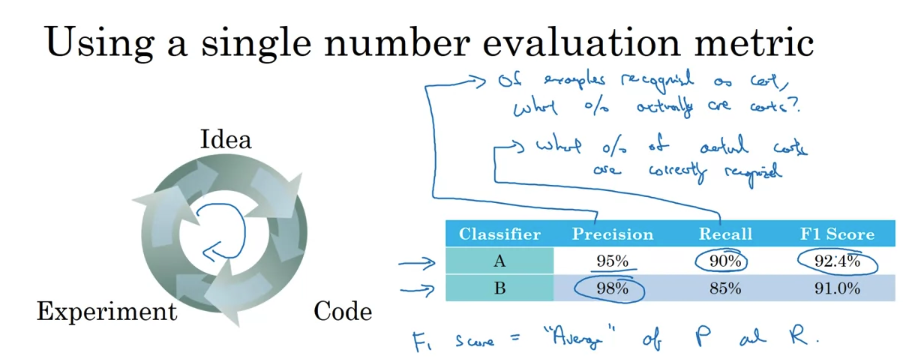
- Classifier A is 90% recall: That of all of the images in, say, your dev sets that really are cats, classifier A accurately pulled out 90% of them.
- It turns out that there’s often a tradeoff between precision and recall, and you care about both. → When the classifier says something is a cat, there’s a high chance it really is a cat. But of all the images that are cats, you also want it to pull a large fraction of them as cats. (분류기가 고양이라고 말하면 그게 실제로 고양이일 확률이 높기를 원합니다. 그러나 고양이 이미지 중에서도 많은 이미지를 고양이로 분류할 수 있기를 원합니다.)
- So it might be reasonable to try to evaluate the classifiers in terms of its precision and its recall. The problem with using precision recall as your evaluation metric is that if classifier A does better on recall, which it does here, the classifier B does better on precision, then you’re not sure which classifier is better.
- F1 score: In the machine learning literature, the standard way to combine precision and recall.
- The details of F1 score aren’t too important, but informally, you can think of this as the average of precision, P, and recall, R. Formally, the F1 score is defined by this formula, it’s 2/ 1/P + 1/R.
- In mathematics, this function is called the harmonic mean of precision P and recall R. But less formally, you can think of this as some way that averages precision and recall.
- To summarize, if there are multiple things you care about by say there’s one as the optimizing metric that you want to do as well as possible on and one or more as satisficing metrics were you’ll be satisfice. So long as it does better than some threshold you can now have an almost automatic way of quickly looking at multiple core size and picking the, quote, best one.
Avoidale bias
- In machine learning, avoidable bias is the difference between the training error and the Bayes error. The Bayes error is the theoretical minimum error rate that is possible for a given machine learning model. Avoidable bias is the error that is due to the machine learning model, rather than the data that it is trained on.
- There are a number of factors that can contribute to avoidable bias, including:
- The choice of machine learning algorithm
- The size and quality of the training data
- The way that the model is trained
- There are a number of things that can be done to reduce avoidable bias, including:
- Choosing a machine learning algorithm that is appropriate for the task at hand
- Using a large and high-quality training dataset
- Using a variety of techniques to train the model, such as cross-validation and regularization
- It is important to note that it is not always possible to eliminate avoidable bias entirely. However, by taking steps to reduce avoidable bias, it is possible to improve the accuracy and fairness of machine learning models.
- Here are some examples of avoidable bias in machine learning:
- A model that is trained on a dataset that is biased towards men may be more likely to predict that a job applicant is a man, even if the applicant’s qualifications are equal to those of a woman.
- A model that is trained on a dataset that is biased towards white people may be more likely to predict that a criminal is white, even if the crime rate is equal for all races.
- A model that is trained on a dataset that is biased towards wealthy people may be more likely to predict that a person is wealthy, even if the person’s income is equal to that of a person from a lower socioeconomic status.
- Avoidable bias can have a significant impact on the fairness and accuracy of machine learning models. It is important to be aware of the potential for avoidable bias and to take steps to reduce it.

- what you want is to maybe keep improving your training performance until you get down to Bayes error but you don’t actually want to do better than Bayes error.
- You can’t actually do better than Bayes error unless you’re overfitting. And this, the difference between your training area and the dev error, there’s a measure still of the variance problem of your algorithm.
- The term avoidable bias acknowledges that there’s some bias or some minimum level of error that you just cannot get below which is that if Bayes error is 7.5%, you don’t actually want to get below that level of error. So rather than saying that if you’re training error is 8%, then the 8% is a measure of bias in this example, you’re saying that the avoidable bias is maybe 0.5% or 0.5% is a measure of the avoidable bias whereas 2% is a measure of the variance and so there’s much more room in reducing this 2% than in reducing this 0.5%.
Relationship between human level performance, bayes error and variance

- If you’re trying to understand bias and variance where you have an estimate of human-level error for a task that humans can do quite well, you can use human-level error as a proxy or as a approximation for Bayes error.
- so the difference between your estimate of Bayes error tells you how much avoidable bias is a problem, how much avoidable bias there is. And the difference between training error and dev error, that tells you how much variance is a problem, whether your algorithm’s able to generalize from the training set to the dev set. And the big difference between our discussion here and what we saw in an earlier course was that instead of comparing training error to 0%.
- And just calling that the estimate of the bias. In contrast, in this video we have a more nuanced analysis in which there is no particular expectation that you should get 0% error. Because sometimes Bayes error is non zero and sometimes it’s just not possible for anything to do better than a certain threshold of error.
- Human-level performance is a measure of how well humans can perform a task. Bayes error is the lowest possible error that a machine learning model can achieve on a task, given the amount of data that is available. Variance is a measure of how much the model’s performance varies on different datasets
- The relationship between human-level performance, Bayes error, and variance can be understood in the following way:
- Human-level performance is a lower bound on Bayes error. This is because humans have access to all of the information that is available to the machine learning model, and they are able to use their knowledge and experience to make better decisions.
- Variance is a measure of how much the model’s performance is affected by noise in the data. The more noise there is in the data, the higher the variance will be.
- As the model’s variance increases, the gap between its performance and human-level performance will also increase. This is because the model will be more likely to make mistakes on data that is not representative of the training data.
- In general, the goal of machine learning is to develop models that have low bias and low variance. Low bias means that the model is not making systematic errors, and low variance means that the model’s performance is not affected by noise in the data.
- There are a number of techniques that can be used to reduce bias and variance in machine learning models. These techniques include:
- Data augmentation: This involves creating new data points by modifying existing data points. This can help to reduce the amount of noise in the data.
- Regularization: This involves adding a penalty to the loss function that is being minimized. This can help to reduce the model’s complexity and make it more robust to noise in the data.
- Ensembling: This involves combining the predictions of multiple models. This can help to reduce the variance of the model’s predictions.
Structured data in ML

- All four of these examples are actually learning from structured data, where you might have a database of what ads users have clicked on, database of products you’ve bought before, databases of how long it takes to get from A to B, database of previous loan applications and their outcomes.
- These are not natural perception problems, so these are not computer vision, or speech recognition, or natural language processing tasks.
- Humans tend to be very good in natural perception task. So it is possible, but it’s just a bit harder for computers to surpass human-level performance on natural perception tasks.
- Finally, all of these are problems where there are teams that have access to huge amounts of data. So for example, the best systems for all four of these applications have probably looked at far more data of that application than any human could possibly look at. And so, that’s also made it relatively easy for a computer to surpass human-level performance.
Reducing bias and variance
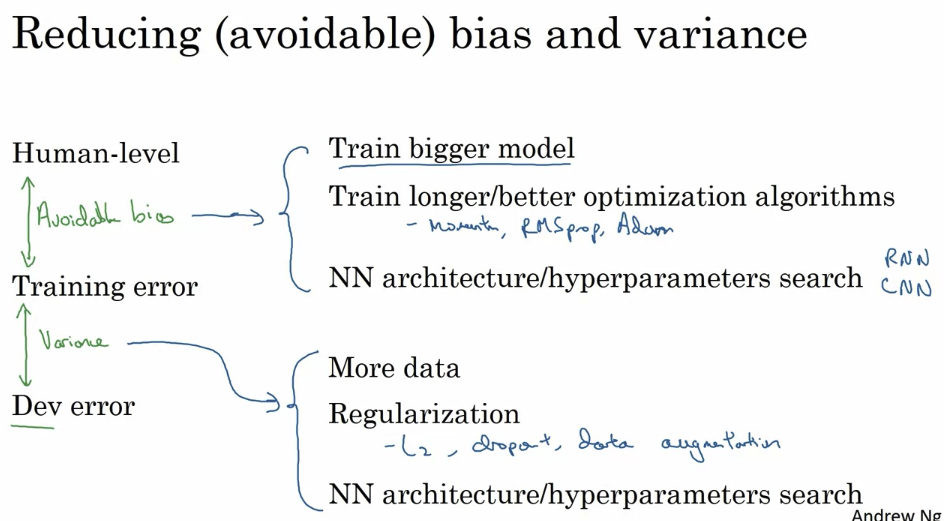
- The process we’ve seen in the last several videos, if you want to improve the performance of your machine learning system, I would recommend looking at the difference between your training error and your proxy for Bayes error and just gives you a sense of the avoidable bias. In other words, just how much better do you think you should be trying to do on your training set.
- Then look at the difference between your dev error and your training error as an estimate of how much of a variance problem you have. In other words, how much harder you should be working to make your performance generalized from the training set to the dev set that it wasn’t trained on explicitly.
How to build ML Strategy
- Carrying Out Error Analysis: you should find a set of mislabeled examples, either in your dev set, or in your development set. And look at the mislabeled examples for false positives and false negatives. And just count up the number of errors that fall into various different categories.

what I would recommend you do, if you’re starting on building a brand new machine learning application, is to build your first system quickly and then iterate. What I mean by that is I recommend that you first quickly set up a dev/test set and metric. So this is really deciding where to place your target. And if you get it wrong, you can always move it later, but just set up a target somewhere.
Then I recommend you build an initial machine learning system quickly. Find the training set, train it and see. Start to see and understand how well you’re doing against your dev/test set and your valuation metric. When you build your initial system, you will then be able to use bias/variance analysis which we talked about earlier as well as error analysis which we talked about just in the last several videos, to prioritize the next steps.
Transfer Learning
- If you retrain all the parameters in the neural network, then this initial phase of training on image recognition is sometimes called pre-training, because you’re using image recognitions data to pre-initialize or really pre-train the weights of the neural network. And then if you are updating all the weights afterwards, then training on the radiology data sometimes that’s called fine tuning.
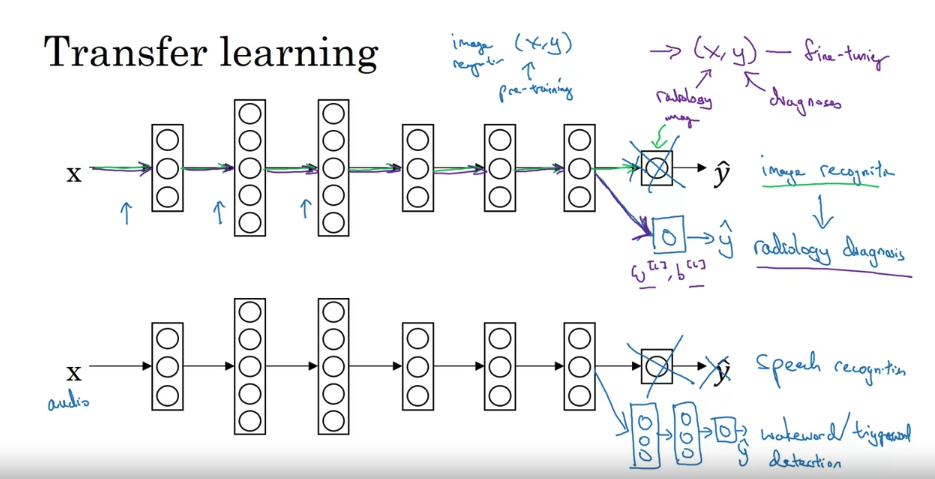
- speech recognition model to wake word/trigger word detection model
- you’ve trained a speech recognition system to output your transcripts. And let’s say that you now want to build a “wake words” or a “trigger words” detection system. So, recall that a wake word or the trigger word are the words we say in order to wake up speech control devices in our houses such as saying “Alexa” to wake up an Amazon Echo or “OK Google” to wake up a Google device or “hey Siri” to wake up an Apple device or saying “Ni hao baidu” to wake up a baidu device.
- In order to do this, you might take out the last layer of the neural network again and create a new output node. But sometimes another thing you could do is actually create not just a single new output, but actually create several new layers to your neural network to try to predict the labels Y for your wake word detection problem. Then again, depending on how much data you have, you might just retrain the new layers of the network or maybe you could retrain even more layers of this neural network.
- When does transfer learning make sense?
- Transfer learning makes sense when you have a lot of data for the problem you’re transferring from and usually relatively less data for the problem you’re transferring to.
- For speech recognition, maybe you’ve trained the speech recognition system on 10000 hours of data. So, you’ve learned a lot about what human voices sounds like from that 10000 hours of data, which really is a lot. But for your trigger word detection, maybe you have only one hour of data. So, that’s not a lot of data to fit a lot of parameters. So in this case, a lot of what you learn about what human voices sound like, what are components of human speech and so on, that can be really helpful for building a good wake word detector, even though you have a relatively small dataset or at least a much smaller dataset for the wake word detection task. So in both of these cases, you’re transferring from a problem with a lot of data to a problem with relatively little data.

- Transfer learning has been most useful if you’re trying to do well on some Task B, usually a problem where you have relatively little data. So for example, in radiology, you know it’s difficult to get that many x-ray scans to build a good radiology diagnosis system. In that case, you might find a related but different task, such as image recognition, where you can get maybe a million images and learn a lot of load-over features from that, so that you can then try to do well on Task B on your radiology task despite not having that much data for it.
Multi task Learning
- In multi-task learning, you start off simultaneously, trying to have one neural network do several things at the same time. And then each of these task helps hopefully all of the other task.
- when does multi-task learning make sense?
One is if your training on a set of tasks that could benefit from having shared low-level features. So for the autonomous driving example, it makes sense that recognizing traffic lights and cars and pedestrians, those should have similar features that could also help you recognize stop signs, because these are all features of roads.
Second, this is less of a hard and fast rule, so this isn’t always true. But what I see from a lot of successful multi-task learning settings is that the amount of data you have for each task is quite similar.
When you recall from transfer learning, you learn from some task A and transfer it to some task B. So if you have a million examples for task A then and 1,000 examples for task B, then all the knowledge you learned from that million examples could really help augment the much smaller data set you have for task B.
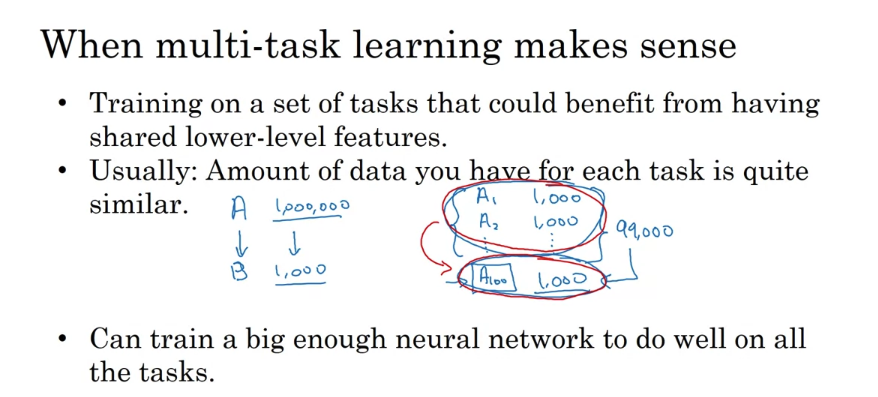
In multi-task learning you usually have a lot more tasks than just two. So maybe you have, previously we had 4 tasks but let’s say you have 100 tasks. And you’re going to do multi-task learning to try to recognize 100 different types of objects at the same time. So what you may find is that you may have 1,000 examples per task and so if you focus on the performance of just one task, let’s focus on the performance on the 100th task, you can call A100. If you are trying to do this final task in isolation, you would have had just a thousand examples to train this one task, this one of the 100 tasks that by training on these 99 other tasks. These in aggregate have 99,000 training examples which could be a big boost, could give a lot of knowledge to argument this otherwise, relatively small 1,000 example training set that you have for task A100. And symmetrically every one of the other 99 tasks can provide some data or provide some knowledge that help every one of the other tasks in this list of 100 tasks.
So the second bullet isn’t a hard and fast rule but what I tend to look at is if you focus on any one task, for that to get a big boost for multi-task learning, the other tasks in aggregate need to have quite a lot more data than for that one task. And so one way to satisfy that is if a lot of tasks like we have in this example on the right, and if the amount of data you have in each task is quite similar. But the key really is that if you already have 1,000 examples for 1 task, then for all of the other tasks you better have a lot more than 1,000 examples if those other other task are meant to help you do better on this final task. And finally multi-task learning tends to make more sense when you can train a big enough neural network to do well on all the tasks.
- The alternative to multi-task learning would be to train a separate neural network for each task. Rather than training one neural network for pedestrian, car, stop sign, and traffic light detection, you could have trained one neural network for pedestrian detection, one neural network for car detection, one neural network for stop sign detection, and one neural network for traffic light detection.
- So what a researcher, Rich Carona, found many years ago was that the only times multi-task learning hurts performance compared to training separate neural networks is if your neural network isn’t big enough. But if you can train a big enough neural network, then multi-task learning certainly should not or should very rarely hurt performance. And hopefully it will actually help performance compared to if you were training neural networks to do these different tasks in isolation.
End to end deep learning
- Briefly, there have been some data processing systems, or learning systems that require multiple stages of processing. And what end-to-end deep learning does, is it can take all those multiple stages, and replace it usually with just a single neural network.
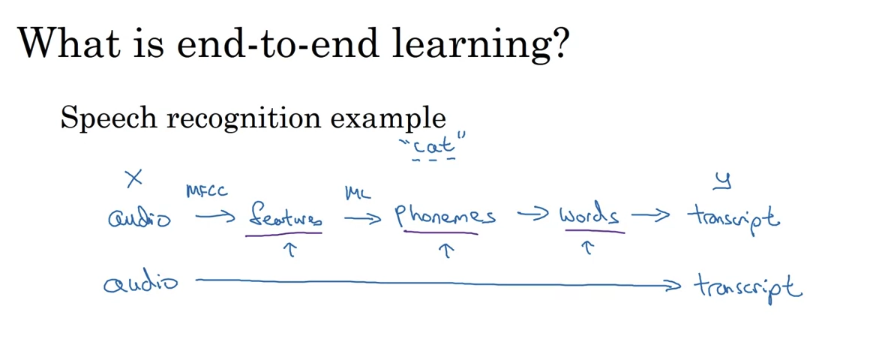
- One of the challenges of end-to-end deep learning is that you might need a lot of data before it works well. For example, if you’re training on 3,000 hours of data to build a speech recognition system, then the traditional pipeline, the full traditional pipeline works really well. It’s only when you have a very large data set, you know one could say 10,000 hours of data, anything going up to maybe 100,000 hours of data that the end-to end-approach then suddenly starts to work really well.
- When you have a smaller data set, the more traditional pipeline approach actually works just as well. Often works even better. And you need a large data set before the end-to-end approach really shines. And if you have a medium amount of data, then there are also intermediate approaches where maybe you input audio and bypass the features and just learn to output the phonemes of the neural network, and then at some other stages as well.
