Journal/Conference : Science Direct
Year(published year): 2023
Author: Javier de Lope, Manuel Graña
Subject: Speech Emtion Recognition, Speech feature extraction
Summary
- This paper provides an overview of recent and classical approaches to speech emotion recognition (SER) using machine learning and deep learning techniques.
- SER is an active area of research that involves recognizing emotional states from speech signals, which can have applications in fields such as human-computer interaction, psychology, and healthcare.
- Classical machine learning approaches for SER include support vector machines (SVMs), k-nearest neighbors (kNN), decision trees, Gaussian mixture models (GMMs), among others. These approaches typically involve extracting features from speech signals using techniques such as Mel Frequency Cepstral Coefficients (MFCCs) or prosodic features like pitch or energy.
- Recent deep learning approaches for SER include convolutional neural networks (CNNs), recurrent neural networks (RNNs), long short-term memory (LSTM) networks, among others. These approaches usually encompass both the feature extraction and classification phases and have shown promising results in some datasets.
- Transfer learning is a technique used in DL that involves reusing a pre-trained neural network model on a new task or dataset. In SER, transfer learning has been applied to CNNs and RNNs to leverage pre-trained models on related tasks and reduce the amount of training data required.
Dataset
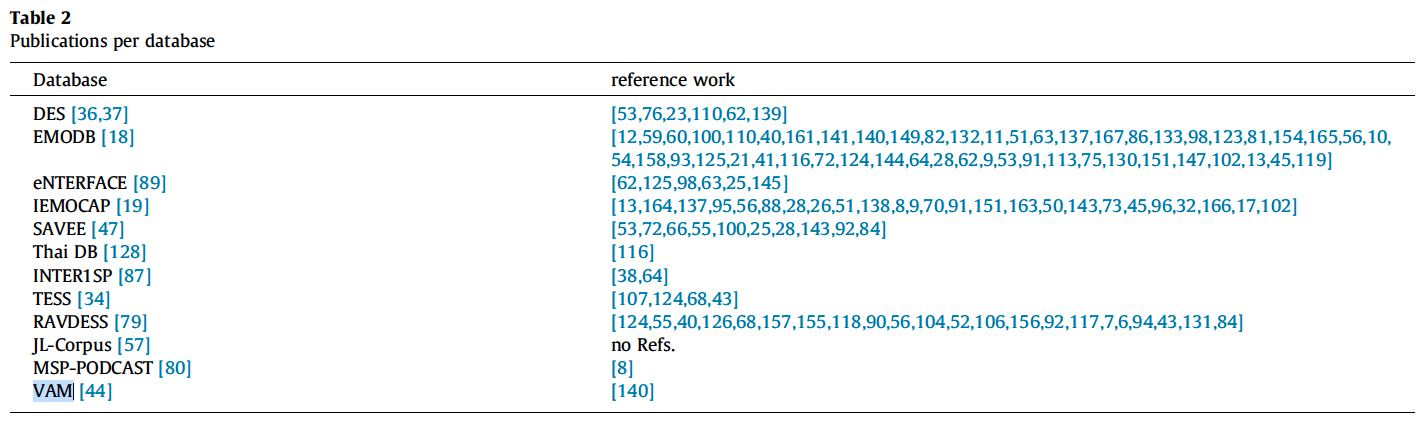
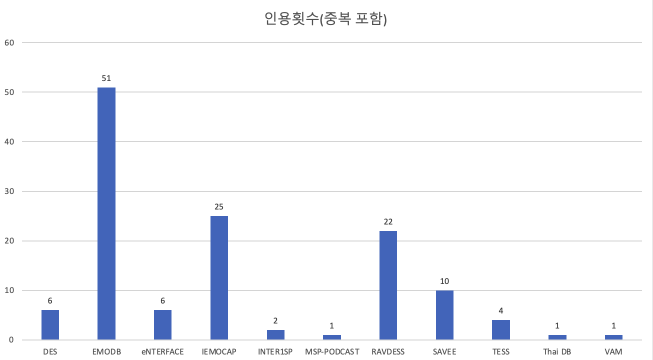
- 12개 데이터 셋, 2004년~2022년도에 발행된 93개의 논문
- Table1에는 VAM이 빠져잇어 11개의 데이터 셋만 비교함
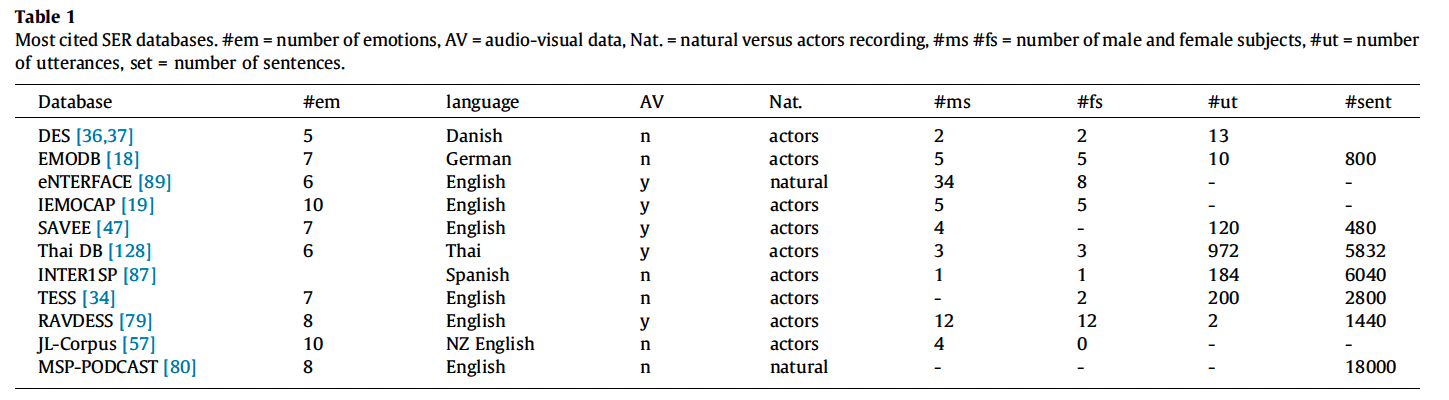
- DES
- 덴마크어 emotion Database
- 4명의 전문 배우(여성 2명, 남성 2명)의 녹음
- 30분 분량의 연설로 구성
- 2개의 독립된 단어 (예, 아니오), 9개의 짧은 구문(4개 질문, 5개 평서문), 두개의 구절로 구성
- 중립, 놀람, 행복, 슬픔, 분노 총 5개의 감정
- EMODB
- 독일어 emotion Database
- 10명의 배우(여성 5명, 남성 5명)
- 1487초(평균 2.77초)
- 짧은 문장 5개, 긴 문장 5개
- 일부 감정 표현에는 동일한 발화자가 기록한 두가지 버전이 있음
- 약 800개의 문장 제공(중복 포함), 535개 발화(중복제거)
- 분노, 중립, 화남, 지루함, 행복, 슬픔, 혐오 총 7가지 감정
- eNTERFACE 89
- 영어 audio-visual emotion Database
- 14개의 국적의 42명(여성 19%, 남성 81%)
- 6개의 단편 스토리에 대한 반응을 표현
- 행복, 슬펌, 놀라움, 분노, 혐오감, 두려움 총 6가지 감정
- IEMOCAP
- Interactive Emotional Dyadic Motion Capture Database
- collected by University of South California
- 10명의 배우가 대본 시나리오와 즉흥 시나리오에서 얼굴, 머리, 손 등에 마커를 부착한채 녹음이 진행됨
- 12시간분량의 데이터
- 오디오는 3-15초 사이로 나눠지며 3-4명의 사람이 라벨링을 함
- 분노, 슬픔, 행복, 혐오감, 두려움, 좌절, 흥분, 중립 등 10가지 감정으로 확장됨(원래 설계는 분노, 슬픔, 행복, 좌절, 중립 5개 였음)
- SAVEE
- 영어 Audio-Visual Expressed Emotion Database
- 4명의 영국 남성 배우의 오디오 및 비디오 녹음
- 120개의 발화를 연기, 총 480개의 문장
- 감정별로 15개의 문장(공통 문장 3개, 감정별 문장 2개, 일반 문장 10개)
- 중립, 분노, 혐오, 공포, 행복, 슬픔, 놀람 총 7가지 감정
- Thai DB
- Audiovisual Thai Emotion Database
- 6명의 드라마 전공생들
- 1~7음절로 구성된 일반적인 태국어 단어 1000개 → 최종으로는 972개 단어
- 행복, 슬픔, 놀라움, 분노, 두려움, 혐오감 총 6가지 감정
- INTER1SP
- 스페인어 emotion database
- 남성 1명과 여성 1명의 Spanish 전문 배우의 녹음
- 단어, 숫자, 문장을 포함하는 184개 발화를 포함.
- 각 화자 마다 4시간 분량의 데이터, 6040개의 샘플이 포함
- 분노, 혐오, 공포, 행복, 슬픔, 놀라움, 중립등의 감정이 고려됨
- TESS
- Toronto emotion database
- 2명의 전문 배우
- 200개의 단어, 2800개의 샘플
- 분노, 혐오, 두려움, 행복, 유쾌함, 슬픔, 중립 총 7가지 감정
- RAVDESS
- 영어 Audio-Visual Database of Emotional Speech and Song
- 24명의 전문배우(여성 12명, 남성 12명)
- 2개의 문구, 1440개 음성 오디오 샘플(오디오 하나당 약 3초)
- 7356개의 오디오 및 비디오 클립으로 구성(25GB)
- 중립, 평온, 행복, 슬픔, 분노, 두려움, 혐오, 놀라움 총 8가지 감정
- JL-Corpus
- 뉴질랜드 emotion database
- 5개의 기본감정과 5개의 보조 감정
- [58]논문 외에는 다른곳에서 사용한 언급을 찾을수 없음
- MSP-PODCAST
- 영어 emotion database
- 오픈 오디오 데이터 소스로 자연스러운 (일반인의) 녹음
- 27시간(2.75~11초), 18000개의 자연스러운 감정 문장
- 300명의 평가자가 라벨링
- 8개의 감정(기본 arousal, valence, dominance + extended list of emotions)
Machine Learning
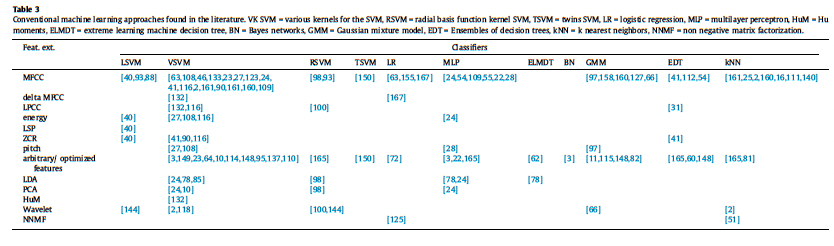
- Conventional machine learning approaches found in the literature.
- VK SVM = various kernels for the SVM
- RSVM = radial basis function kernel SVM
- TSVM = twins SVM, LR = logistic regression
- MLP = multilayer perceptron
- HuM = Humoments
- ELMDT = extreme learning machine decision tree
- BN = Bayes networks
- GMM = Gaussian mixture model
- EDT = Ensembles of decision trees
- kNN = k nearest neighbors
- NNMF = non negative matrix factorization.
Deep Learning
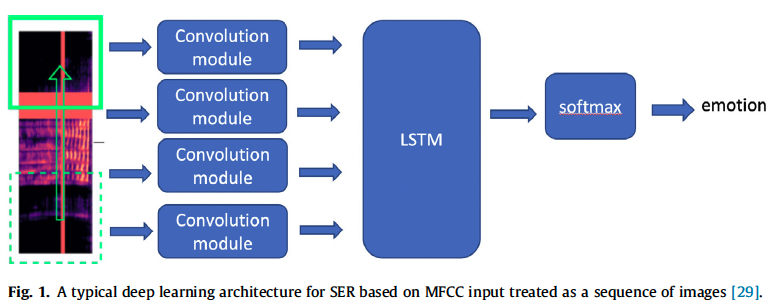
- 그림 1에는 CNN과 LSTM을 결합한 음성 감정 인식을 위한 일반적인 딥러닝 구조에 대해 설명합니다. CNN을 사용해 감정 특징을 학습하거나 기존의 수작업 특징 없이 CNN과 RNN을 연결해 기존 방식보다 더 높은 정확도를 달성한 초기 접근법의 예를 소개합니다.
- 이 문장들은 CNN 및 LSTM과 같은 딥러닝 모델을 사용하여 음성에서 감정을 인식하는 다양한 연구들을 설명합니다. 연구자들은 이러한 모델을 다양한 방식으로 결합하여 사용하였으며, CNN을 사용하여 affective feature를 학습하거나, CNN과 RNN을 결합하여 새로운 아키텍처를 만들어 감정을 인식하는 등 다양한 방법을 사용하였습니다. 많은 연구에서는 기존의 방법과 비교하여 높은 정확도를 보고하였습니다.
- 연구들은 MFCC, LFE(Log Mel-Filterbank Energies*)*, spectrograms 및 Mel spectrograms 등 다양한 유형의 데이터를 결합하고, 병렬화된 convolutional recurrent neural networks, multi-CNN, 1D convolutional layers 등 다양한 아키텍처를 사용합니다. 이러한 실험들은 다양한 데이터베이스에서 수행되었습니다.
- CNN, LSTM, transformers 등 딥러닝 모델을 사용하여 음성에서 감정을 인식하는 다양한 연구들을 설명합니다. 연구자들은 훈련 및 테스트를 위해 다양한 데이터셋을 사용하며, 데이터 증강 및 깊은 메트릭 러닝과 같은 다양한 기술을 적용하여 감정 인식 결과를 개선하려고 노력합니다.
- DL network, recurrent neural networks(RNN) 및 gated recurrent units (GRU) 등의 딥러닝 모델을 사용하여 음성에서 감정을 분류하기 위한 다양한 연구들을 설명합니다. 연구들은 spectrograms 및 MFCC와 같은 다양한 기술을 사용하며, 기존의 최신 방법보다 더 나은 정확도를 보고하고 있습니다. 하나의 연구에서는 전통적인 데이터 증강 기술을 사용하지 않는 DL network를 제안하며, 더 큰 이미지 차원이 더 높은 정확도를 보이지만 계산 복잡성이 증가한다는 것을 보고하고 있습니다.
- 이미지 스펙트럼에 적용되는 잘 알려진 DL 아키텍처를 transfer learning하는 것이 많은 DL 접근 방법에 사용됩니다. 많은 논문들이 CNN을 이용하여 스펙트럼 이미지를 처리하며, 그 중 Stolar et al. [130], Badshah et al. [12]은 AlexNet 모델을 transfer learning 하는 방법을 사용합니다. 또한, Huang and Bao [52], Zhang et al. [163], Gerczuk et al. [42], Popova et al. [106], Wang et al.[143] 등은 스펙트럼 이미지나 MFCC를 특징으로 하는 DL transfer learning 방법을 사용합니다.
- Tripathi et al.은 ResNet 기반의 신경망을 제안하여 어려운 샘플에 더 많은 중요도를 부여하는 focal loss로 감정 인식을 훈련시켰습니다. 이는 다양한 클래스 간에 중요한 클래스 불균형이 존재할 때 정확도를 향상시키려는 것입니다. Park et al.은 특성 입력에 직접 적용되는 음성 인식용 데이터 증강 방법을 제안하여, 주파수 채널 블록 및 시간 단계 블록을 마스킹하는 방법 등으로 특성을 왜곡합니다. 이 방법을 사용하여 훈련 세트를 보강하여 언어 모델의 도움 없이도 상태가 좋은 결과를 얻을 수 있었다고 보고하고 있습니다. Yi et al.는 생성 적대 신경망(GAN)을 사용하여 데이터 증강을 수행합니다. Shilandari et al. 및 Latif et al.도 데이터 증강을 위해 GAN을 제안합니다. Bakhshi et al.은 CNN에서 사용하기 위해 오디오 녹음에서 질감 있는 이미지를 생성합니다.
- Zeng et al. [156]은 오디오 파일에서 생성 된 스펙트로그램을 기능으로 사용하며 LSTM에서 사용하는 게이트 메커니즘과 유사한 ResNet 아키텍처를 기반으로 한 DL 접근 방식을 제안합니다. Jannat et al. [58]은 오디오 기능만 사용하여 Inception-v3 딥러닝 아키텍처를 사용하여 행복과 슬픔에 대해 66.41 %의 정확도 (교차 검증)를 달성하는 다중 모달 접근 방식을 사용합니다. Sanchez-Gutierrez 및 Gonzalez-Perez [113]는 딥러닝 네트워크에서 유용한 뉴런 노드를 식별하고 제거하여 오류율을 감소시키기 위해 여러 판별적 측정 방법을 적용하며, Manohar 및 Logashanmugam [84]은 감정 분류에 대한 딥러닝 네트워크의 성능을 높이기 위한 기능 선택 방법을 제안합니다.
- Wang et al. [145]는 이미지와 오디오 녹음으로부터 감정을 인식하는 멀티모달 시스템을 제안한다. 특히, 오디오 서브시스템은 CNN과 LSTM 네트워크를 사용하며, 녹음에서 생성된 스펙트로그램 이미지를 입력으로 사용한다. Heredia et al. [50]는 소셜 로봇에서 감정을 감지하기 위한 멀티모달 (비디오, 오디오 및 텍스트) DL 아키텍처를 제안하고 있다.
Conclusion
- 이제는 예측 모델의 비교 및 새로운 발전을 지탱할 데이터의 가용성이 과학의 핵심 중 하나이다. SER 분야에서는 지역적인 작은 규모의 데이터셋이 많다. 최근 데이터셋 중 일부는 아직 활용되지 않았으며, 오래된 데이터셋 중 일부만 활용되어 새로운 데이터셋이 제안될 때마다 오래되어 새로운 결론이 되지 않을 수 있다.
- SER 분야에서 중요한 신호 특성과 DL 아키텍처의 보급이 이미 시작되었지만, 이러한 접근 방식은 데이터 샘플링의 민감성 및 유효성 검사에 대한 분석과 검증이 필요하다. 또한, 이 분야에서는 새로운 아키텍처 및 기능이 빠르게 나타나고 있으므로, 고객과의 감성적 상호작용의 높은 가치 때문에 성능의 큰 향상이 곧 나타날 것으로 기대된다