개요
- 유저들의 재주문 여부 예측하기
- instacart kaggle: https://www.kaggle.com/competitions/instacart-market-basket-analysis/leaderboard
- 2위 한 모델 github: https://github.com/KazukiOnodera/Instacart
필요 메모리
- 약 300GB RAM이 필요.
- 개인용 LB에서는 약 60GB RAM만으로도 0.4073을 얻을 수 있음을 확인.
- 또한 메모리가 충분하지 않고 높은 점수를 얻고 싶다면 xgb.train의 xgb_model을 사용하여 연속 훈련을 시도.
데이터 구조
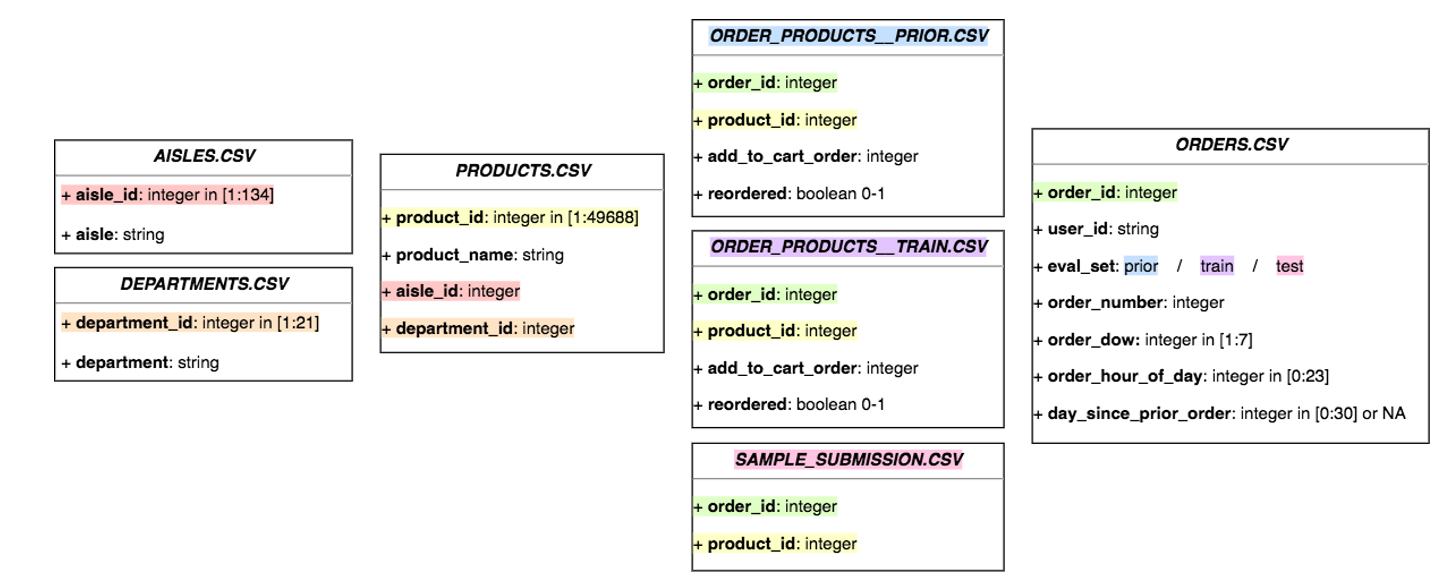
주요 approach
두 가지 모델: 재주문 예측 및 재주문 없음 예측
재주문 모델의 키는 user_id와 product_id
없음 모델의 키는 user_id
더 나은 예측을 위해 더 많은 훈련 데이터를 사용해야 한다고 생각했습니다.
prior 데이터를 훈련 데이터로로 사용하기로 결정
튜닝 결과, 최적의 윈도우 수는 3개
재주문 예측

재주문 없음 예측

모델 구조
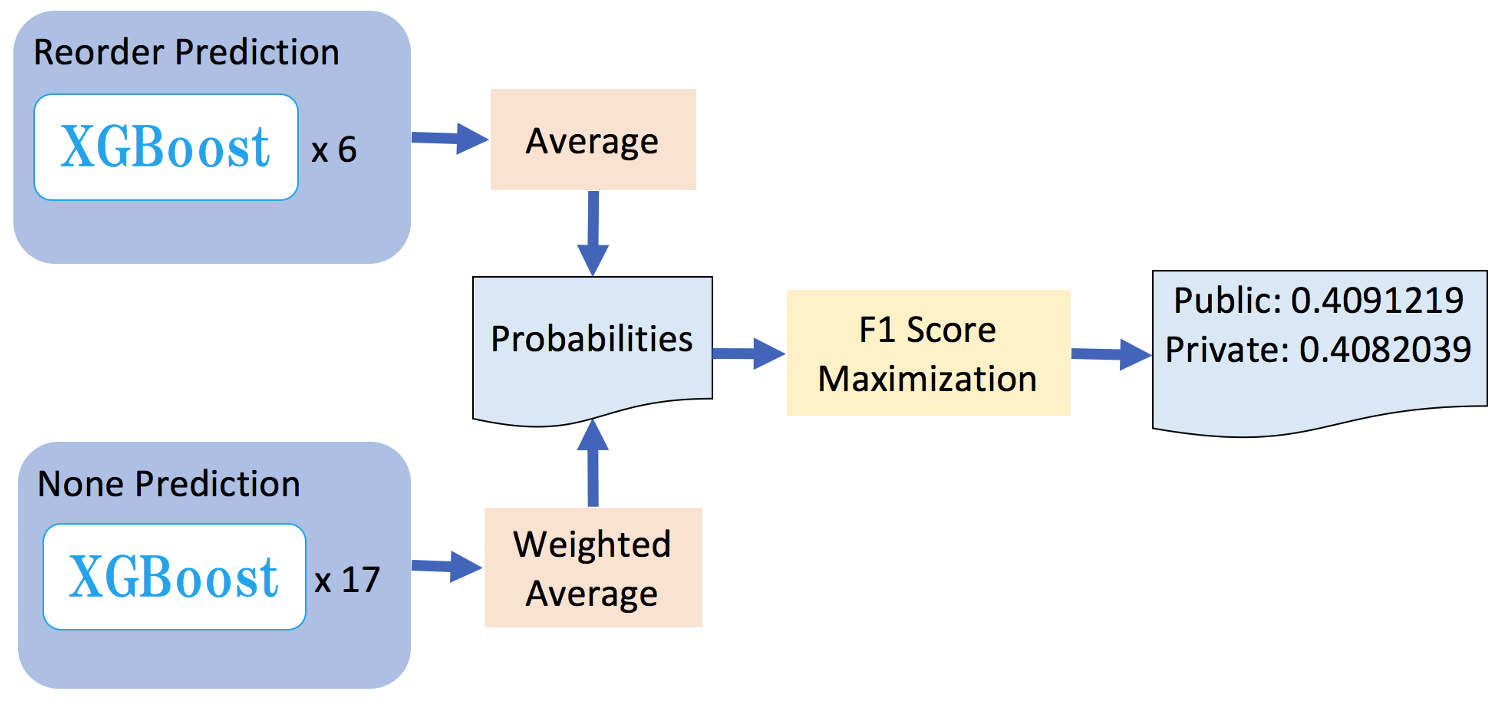
Feature Engineering
- User: what this user like
- Item: what this item like
- User x Item: How do user feel about the item
- Datetime: What this day and hour like
*For None model, I can’t user above features except user and datetime, so I convert those to stats(min, mean, max, sum, std…)
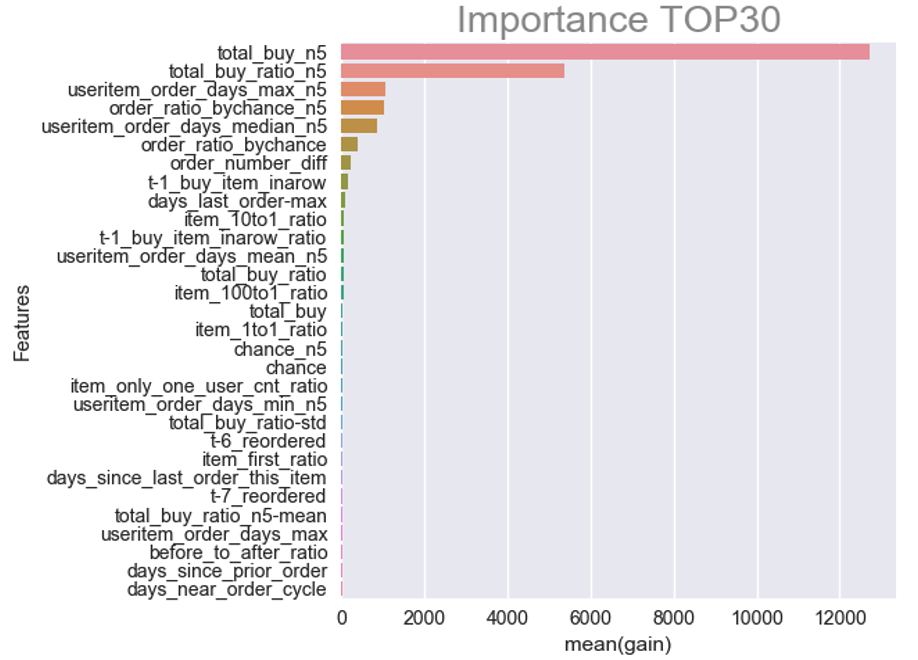
Feature Importance for reorder
Feature Importance for None
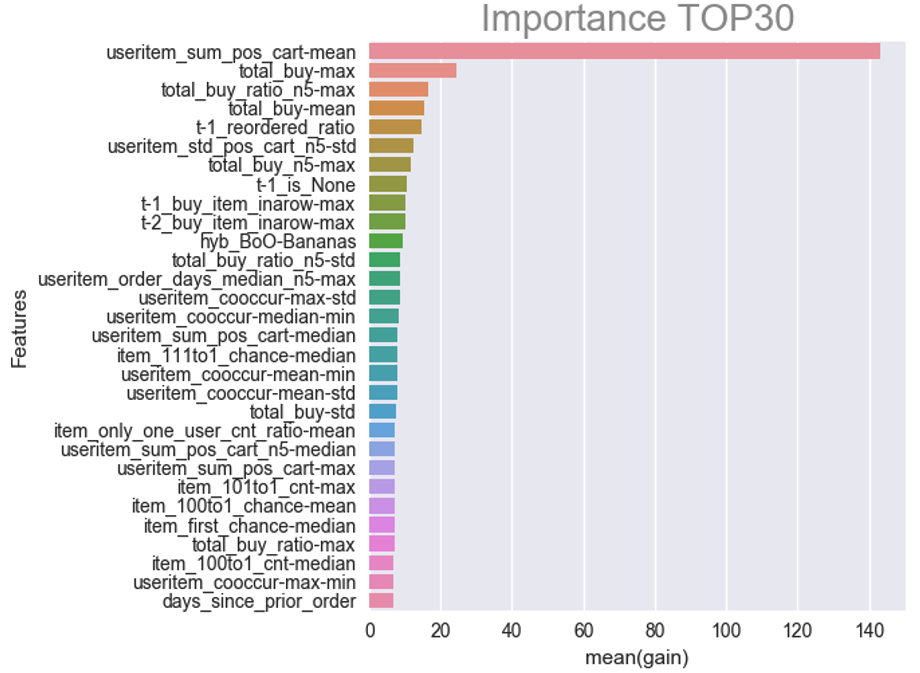
Importance Findings for reorder
- 상식적으로 과거에 여러 번 구매한 품목은 재주문될 확률이 높다는 것을 알 수 있습니다.
하지만 재주문되지 않는 품목에 대한 패턴이 있을 수 있습니다 → 이 패턴을 파악하여 사용자가 언제 상품을 재주문하지 않는지 파악할 수 있습니다.
user_id : 54035
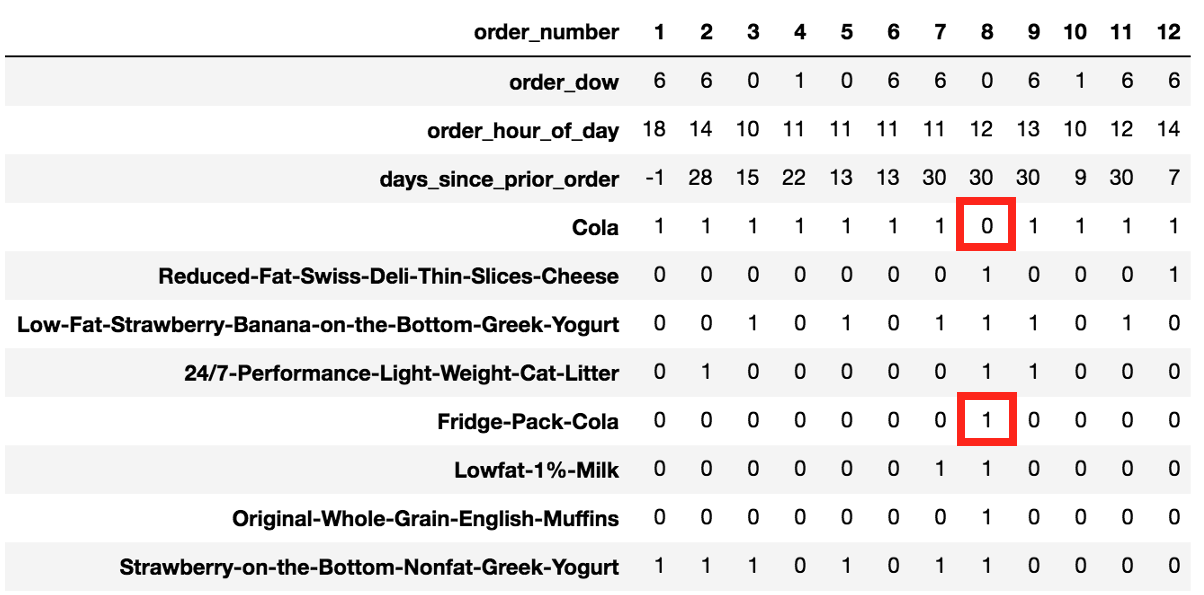
이 유저는 콜라를 항상 재주문하였다.
그러나 8번 주문을 보면 유저는 재주문 하지 않았다 그 이유는 fridge-pack-cola를 대신 샀기 때문.
이러한 행동 유형을 잡기 위해서 피처를 만들었다.
- days_last_order_max는 days_since_last_order_this_item과 useritem_order_days_max를 뺀 것.
days_since_last_order_this_item는 유저와 아이템 사이의 피처이다. → 이는 마지막 오더에서 얼마나 많은 일수가 지나갔는지에 대한 것
useritem_order_days_max 는 유저와 아이템 사이의 피처이다 → 이는 주문의 최대 주문 기간(일)을 의미한다.
index 0을 보면, 이는 유저가 주문을 14일 전에 샀고 주문 최대 기간이 30일인걸 알수 있다.
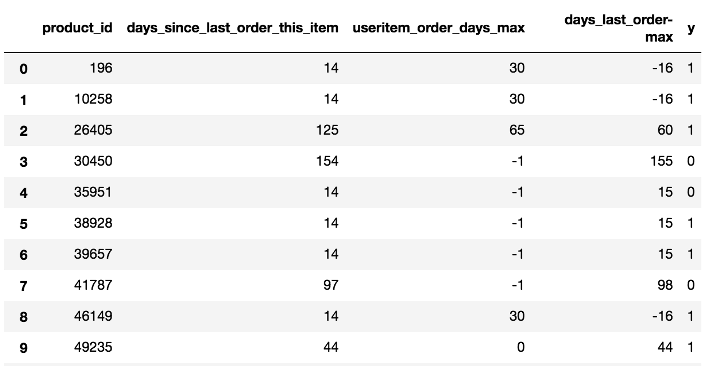
이 피처는 유저가 그 아이템을 사는것에 싫증을 느끼는지 아닌지에 대한 것
- 이미 우리는 야채보다 과일의 재주문율이 더 많은걸 알고 있다.
얼마나 더 자주인지 알아보자
item_10to1_ratio 피처를 만듦: 주문된 경우와 주문되지 않은 경우의 재주문 비율로 정의
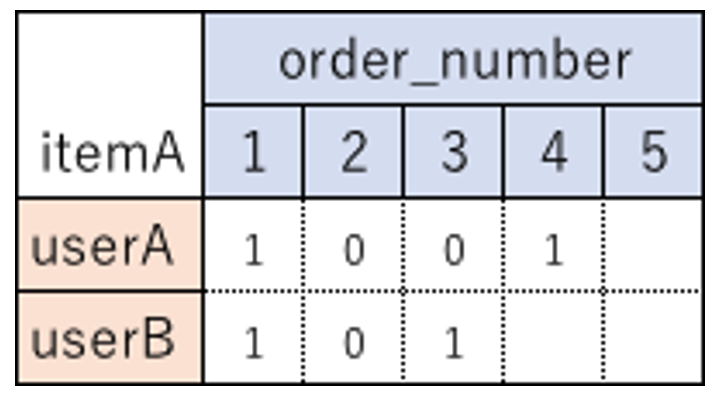
유저 A가 item A를 order_number 1과 4를 샀다. 유저B는 item_A를 order_number 1과 3을 샀다.
- item_10to1_ratio는 0.5 : 유저 a가 먼저 1,4를 사고 유저 b가 1,3을 샀는데 산 1,3 중에 재주문 된 order_number가 1이어서 2개 중에 재주문율 1개 그래서 ratio는 0.5
Importance Findings for reorder
- useritem_sum_pos_cart(사용자 A, 아이템 B)는 사용자 A의 카트에서 아이템 B가 속하는 평균 위치입니다.
- useritem_sum_pos_cart-mean(사용자 A)은 모든 항목에 대한 위 기능의 평균입니다.
- 따라서 이 feature는 기본적으로 사용자의 카트에서 아이템의 평균 위치를 캡처하며, 한 번에 많은 아이템을 구매하지 않는 사용자는 ‘재주문이 아님’일 가능성이 더 높다는 것을 알 수 있습니다.
- total_buy는 total order의 숫자
- 만약 유저a가 item A를 과거에 3번 샀다면, total_buy는 3이 됨
- 그래서 total_buy_max는 유저당 주문의 최대값
- 우리는 이를 통해 유저가 재주문할지 안할지를 예측
- t-1_is_None(User A)는 binary feature: 유저의 전 주문이 재주문인지 아닌지를 알려줌
- 만약 이 전주문이 ‘재주문하지 않음’이라면, 다음 주문은 재주문하지 않을 가능성이 30%가 있는것. /
F1 maximization
F1 최대화에 관해서는 Faron이 커널을 발표하기 전까지는 그 논문을 읽지 않았습니다. 하지만 저는 F1 최대화 덕분에 높은 점수를 받았습니다. 설명해드리겠습니다. F1을 최대화하기 위해 저는 예측된 확률에 따라 y_true를 생성합니다. 그리고 더 높은 확률에서 F1을 확인합니다. 예를 들어 {A: 0.3, B: 0.5, C: 0.4}와 같이 항목과 확률이 정렬되어 있다고 가정해 보겠습니다. 그런 다음 y_true를 여러 번 생성합니다. 제 경우에는 9999번 생성했습니다. 이제 [[A,B],[B],[B,C],[C],[B],[None]…..]와 같이 많은 y_true가 생겼습니다. 위에서 언급했듯이 다음으로 할 일은 [B], [B,C], [B,C,A]에서 F1을 확인하는 것입니다. 그런 다음 F1 피크 아웃을 추정하고 계산을 중지하고 다음 순서로 넘어갈 수 있습니다. 이 방법에서는 [A],[A,B],[A,B,C],[B]…와 같은 모든 패턴을 확인할 필요가 없다는 것을 알 수 있습니다. “더 멀리 가기 위한 팁”이라는 제 코멘트에서 이 방법을 알아낸 분도 있을 것 같습니다. 그러나 이 방법은 시간이 많이 걸리고 시드에 따라 달라집니다. 그래서 저는 결국 Faron의 커널을 사용했습니다. 다행히도 Faron의 커널을 사용해서 거의 동일한 결과를 얻었습니다. py_model/pyx_get_best_items.pyx를 참고하세요.
모델 평가 지표인 F1 score: 단일 메트릭에서 정확도와 리콜을 모두 캡처하는 방법
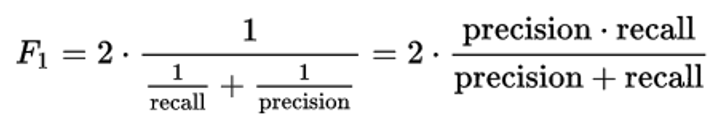
그래서 우리는 재주문 확률을 이진 형태로 바꿔야 함.
하지만 이 변환을 수행하려면 임계값을 알아야 함. 처음에는 그리드 검색을 사용하여 0.2라는 보편적인 임계값을 찾았지만 Kaggle 토론 게시판에서 주문에 따라 임계값이 달라야 한다는 의견을 봄
왜그래야 하는지에 대해서 밑의 예시를 살펴 보자
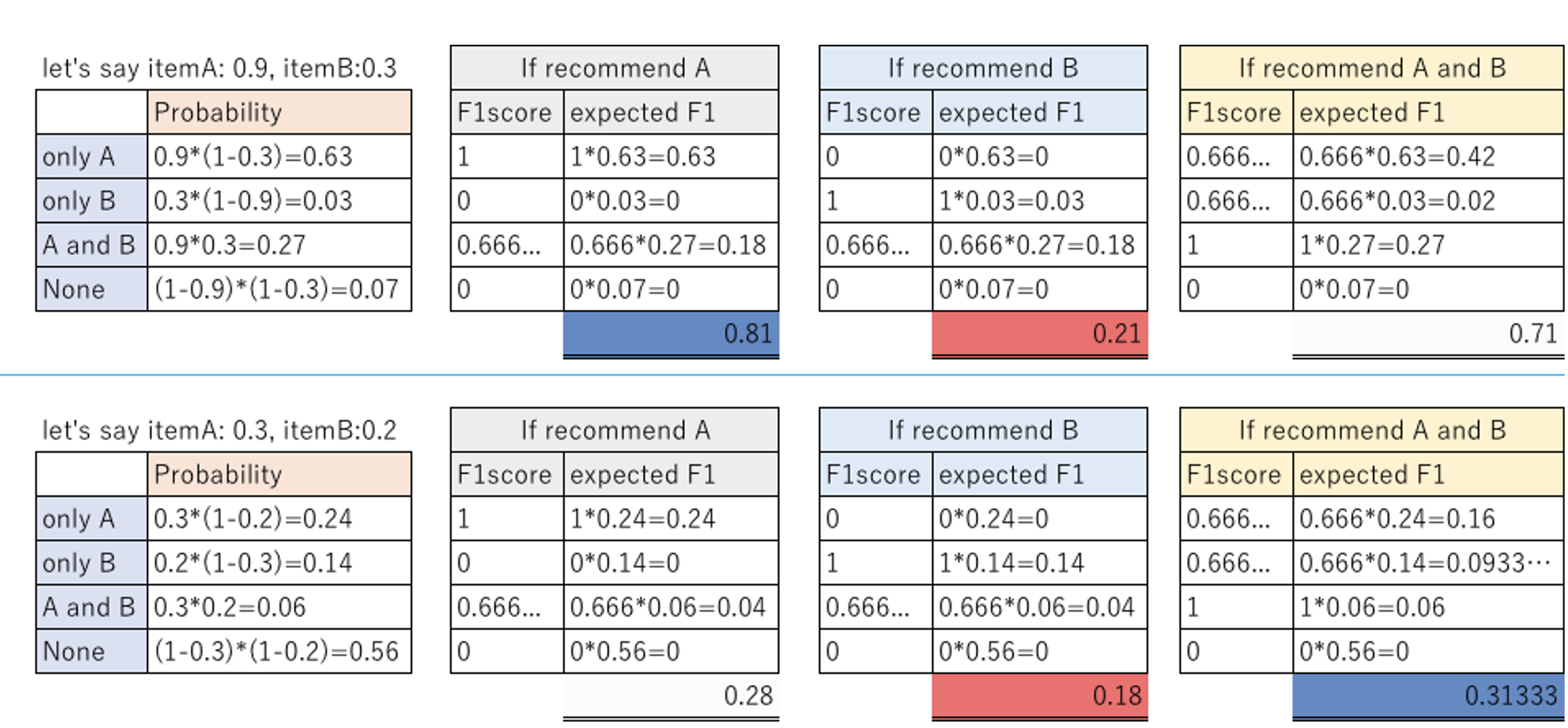
- 첫 번째 예에서 임계값은 0.9에서 0.3 사이입니다.
- 두 번째 예에서는 임계값이 0.2보다 낮습니다.
- 앞서 설명했듯이 각 주문에는 각각의 임계값이 있어야 합니다.
- 하지만 위의 계산을 사용하면 모든 확률 패턴을 먼저 준비해야 합니다.
- 따라서 다른 계산을 생각해 내야했습니다.
- 모델에서 품목 A가 0.9의 확률로 재주문되고 품목 B가 0.3의 확률로 재주문될 것으로 예측한다고 가정해 보겠습니다.
- 그런 다음 이 확률을 사용하여 9,999개의 대상 레이블(A와 B가 재주문될지 여부)을 시뮬레이션합니다.
- 예를 들어 시뮬레이션된 레이블은 다음과 같이 보일 수 있습니다. 그런 다음 확률이 가장 높은 항목부터 시작하여 F1 점수가 정점에 달했다가 감소할 때까지 항목(예: [A], [A, B], [A, B, C] 등)을 추가하여 각 레이블 세트에 대한 예상 F1 점수를 계산합니다.
- A, B, AB…와 같은 모든 패턴을 계산할 필요는 없습니다.
- 항목B를 선택해야 한다면 항목A도 선택해야 하기 때문입니다.

- ‘재주문 없음’(None)에 대해 생각하는 한 가지 방법은 (1 - 항목 A) * (1 - 항목 B) * …의 확률로 생각하는 것입니다.
- 하지만 또 다른 방법은 None을 특수한 경우로 예측하는 것입니다.
- None 모델을 사용하고 None을 다른 항목으로 취급하면 F1 점수를 0.400에서 0.407로 높일 수 있습니다.