Course
Unsupervised Learning
1. clustering
Usage: Grouping similar news, DNA analysis, Astronomical data analysis
k-means algorithm

- local minimum
- Occurs when optimization algorithm converges to a suboptimal solution
- K-means is sensitive to initial centroid placement
- Different initializations can lead to different local minima
- Multiple runs with random initializations can mitigate this issue
- elbow method
- Technique to determine optimal number of clusters (k)
- Plot within-cluster sum of squares (WCSS) against k
- Look for “elbow” point in the plot
- Elbow indicates diminishing returns in WCSS reduction with increasing k
- Choose k at elbow point as optimal number of clusters
- Evaluate K-means based on how well it performs on that later purpose → not depending on mathematics but business.
- local minimum
2. anomaly detection
gaussian(normal) distribution
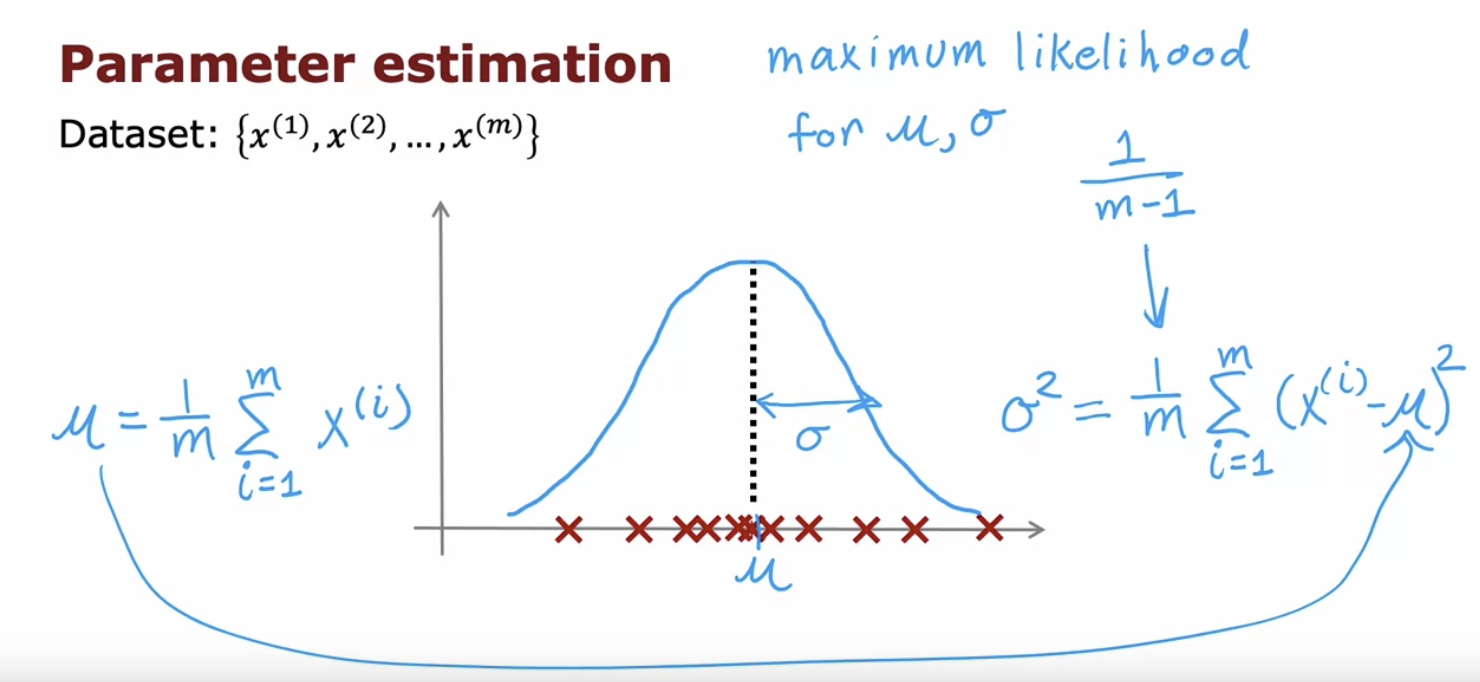
anomaly detection algorithm
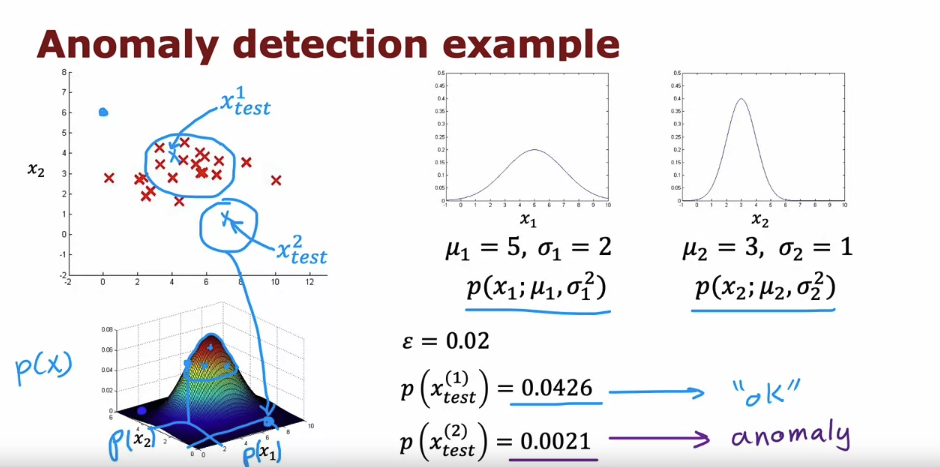
Anomlay detection VS Supervised Learning

- Just train the system to decide if a new smartphone that you just manufactured has any scratches in it.
- If you just see scratch smartphones over and over and you want to check if your phones are scratched, then supervised learning works well.
- Whereas if you suspect that they are going to be brand new ways for something go wrong in the future, then anomaly detection will work well.
- Anomaly detection tries to find brand new positive examples that may be unlike anything you’ve seen before. Where supervised learning looks at your positive examples and tires to decide if a future example is similar to the positive examples that you’ve already seen.
Recommender Systems

- With this framework for recommended systems one possible way to approach the problem is to look at the movies that users have not rated. And to try to predict how users would rate those movies because then we can try to recommend to users things that they are more likely to rate as five stars.
1. collaborative filtering
Using per-item features

Collaborative filtering
In which of the following situations will a collaborative filtering system be the most appropriate learning algorithm (compared to linear or logistic regression)?
- You run an online bookstore and collect the ratings of many users. You want to use this to identify what books are “similar” to each other (i.e., if a user likes a certain book, what are other books that they might also like?)
→ You can find “similar” books by learning feature values using collaborative filtering.
Binary lables: favs, likes and clicks
2. Recommender systems implementation detail
mean normalization

- It seems more reasonable to think Eve is likely to rate this movie 2.5 rather than think Eve will rate all movie zero stars just because she hasn’t rated any movies yet.
- In fact the effect of this algorithm is it will cause the initial guesses for the new user Eve to be just equal to the mean of whatever other users have rated these five movies.
- It turns out that by normalizing the mean of the different movies ratings to be zero, the optimization algorithm for the recommended system will also run just a little bit faster. But it does make algorithm behave much better for users who have rated no movies or very small numbers of movies. And the predictions will become more reasonable.
- There’s one other alternative that you could use which is to instead normalize the columns of this matrix to have zero mean. And that would be a reasonable thing to do too. But I think in this application, normalizing the rows so that you can give reasonable ratings for a new user seems more important than normalizing the columns.
Limitations of Collaborative Filtering

3. Content-based filtering

- Collaborative filtering:
- Recommend items based on similar user ratings
- Algorithm uses existing ratings to make recommendations
- Content-based filtering:
- Recommend items based on user and item features
- Requires features of users and items
- Finds good matches based on these features
- Can potentially find better matches than collaborative filtering alone
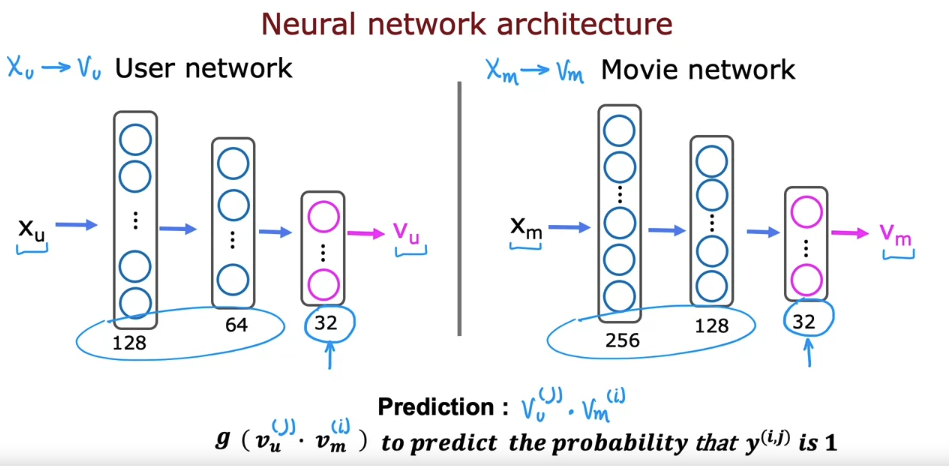
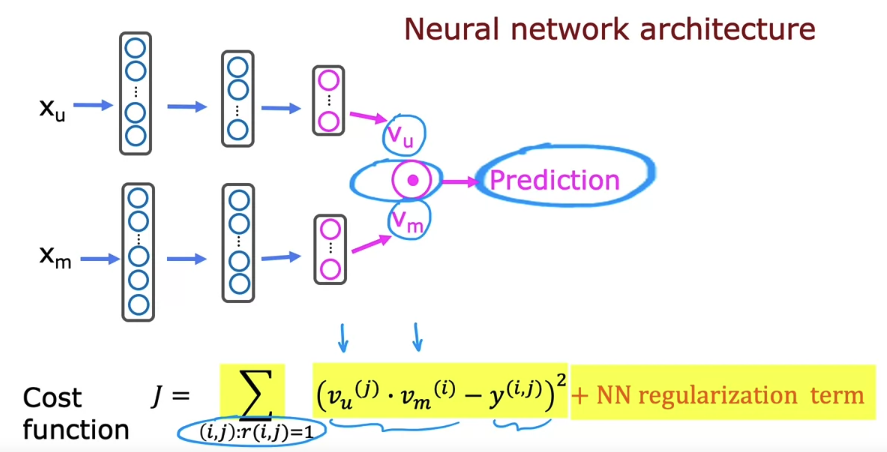
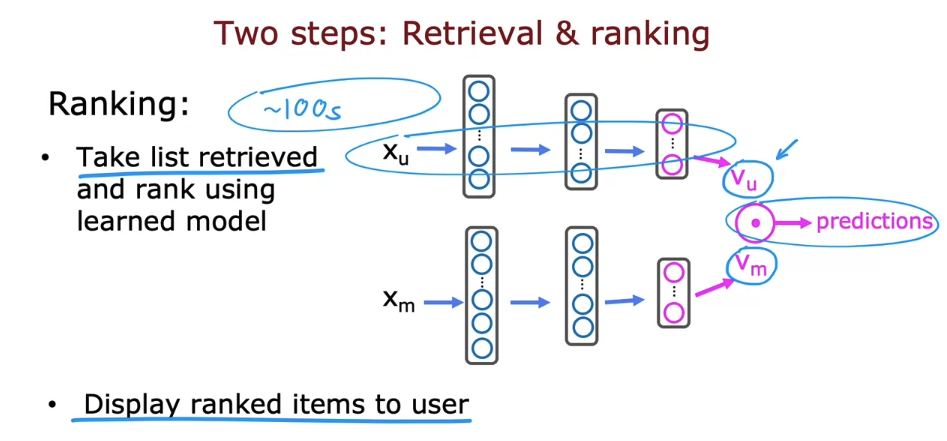
4. Recommending from a large catalogue

- During the retrieval step, retrieving more items will tend to result in better performance. But the algorithm will end up being slower to analyze or to optimize the trade off between how many items to retrieve to retrieve 100 or 500 or 1000 items.
5. Principle Componant Analysis(PCA)
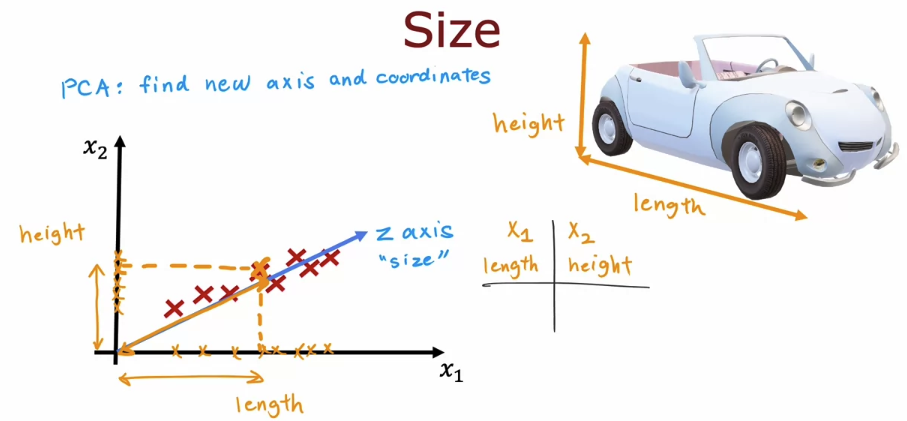
- the idea of PCA is to find one or more new axes, such as z so that when you measure your datas coordinates on the new axis, you end up still with very useful information about the car.
- PCA is a powerful algorithm for taking data with a lot of features, with a lot of dimensions or high-dimensional data, and reducing it to two or three features to two or three dimensional data so you can plot it and visualize it and better understand what’s in your data.
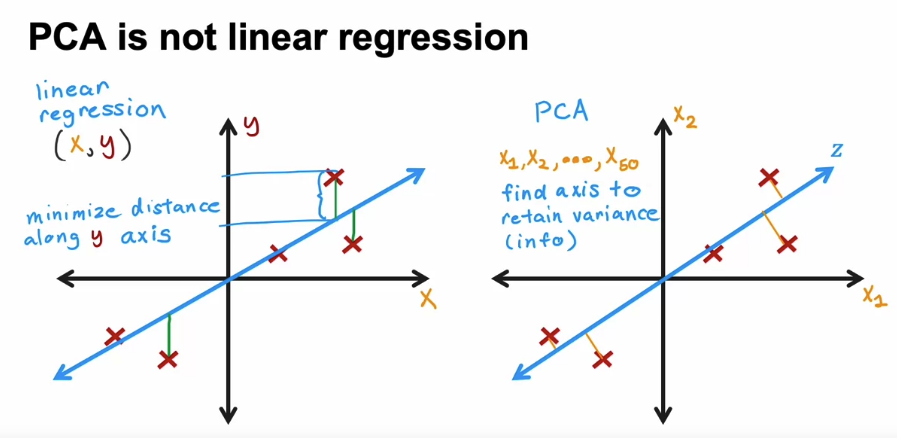
- Linear regression:
- One target variable Y
- Measures distance between fitted line and Y
- Distances measured in the direction of the y-axis
- PCA (Principal Component Analysis):
- Can have many features (e.g., X1, X2, … X50)
- All features treated equally
- Finds axis Z to retain maximum variance
- Projects data onto Z while preserving variance
- But when you have more than two features, which is most of the case, the difference between linear regression and PCA and what the algorithms do is very large. These algorithms are used for totally different purposes and give you very different answers.
- you should use linear regression if you’re trying to predict the value of y, and you should use PCA if you’re trying to reduce the number of features in your data set, say to visualize it.
- PCA (Principal Component Analysis) other applications:
- Data compression (less popular now):
- Reduce features for smaller storage or transmission costs
- Example: 50 features per car reduced to 10 principal components
- Speed up training of supervised learning models (less popular now):
- Reduce high-dimensional features to smaller set
- Used to make a difference for older learning algorithms (e.g., Support Vector Machines)
- Modern developments:
- Improved storage and networking capabilities
- Modern machine learning algorithms like deep learning handle high-dimensional data more effectively
- Less need for PCA in these applications
- Data compression (less popular now):
Reinforcement
1. Reinforcement learning introduction
- the key idea is rather than you needing to tell the algorithm what is the right output y for every single input, all you have to do instead is specify a reward function that tells it when it’s doing well and when it’s doing poorly. And it’s the job of the algorithm to automatically figure out how to choose good actions.
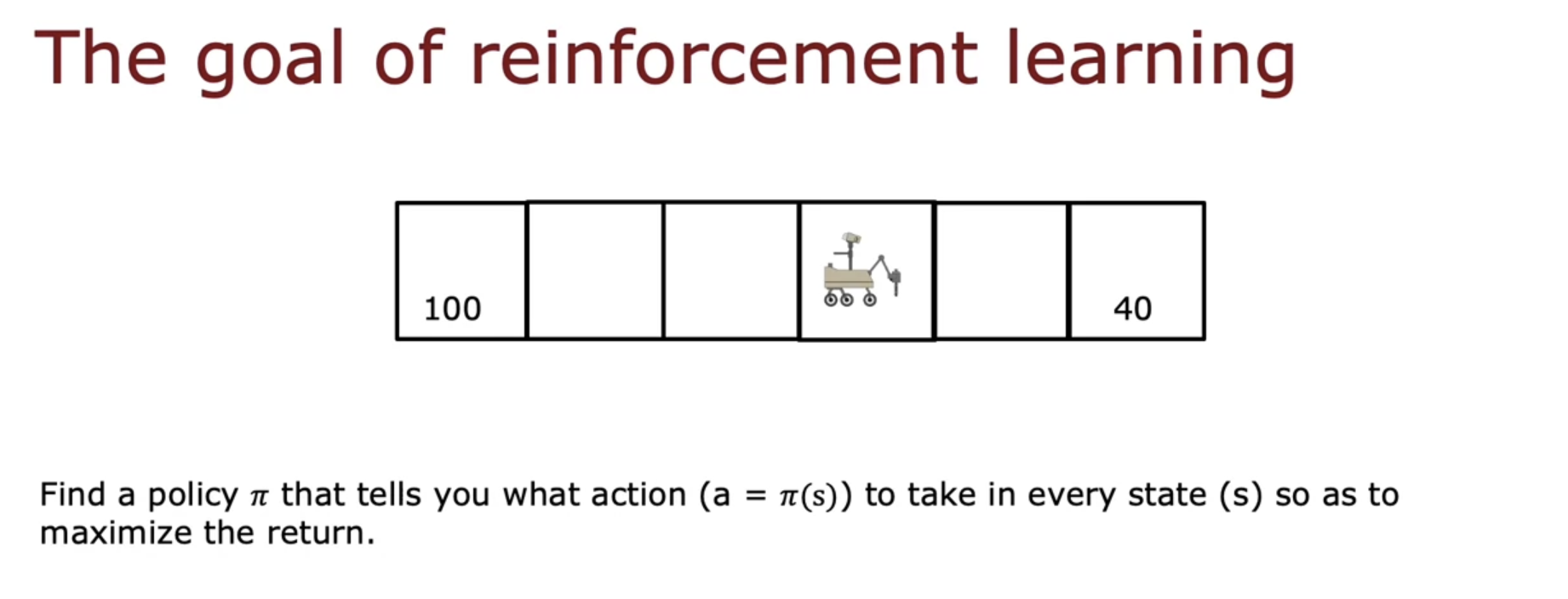
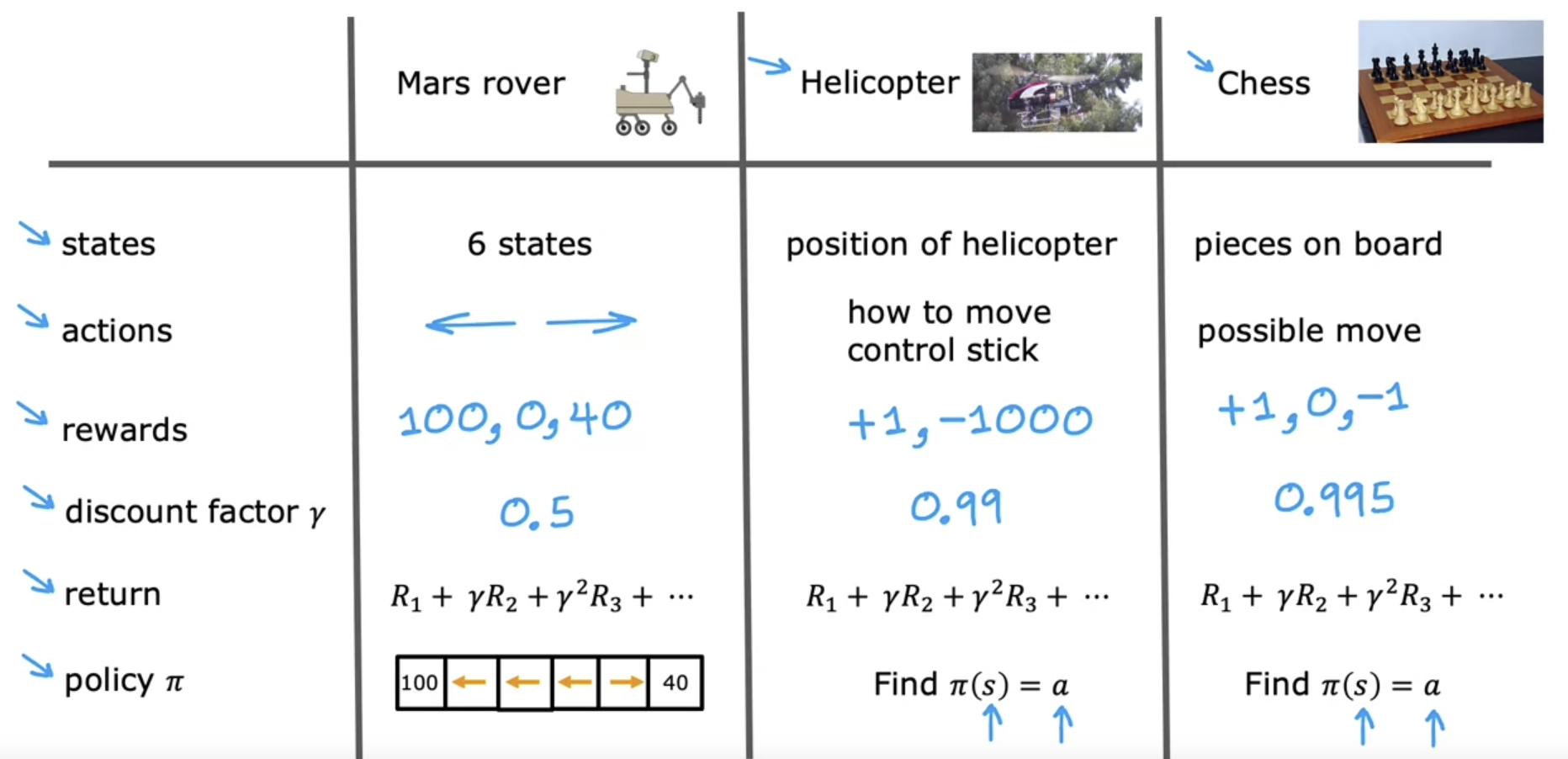
- the goal is given a board position to pick a good action using a policy Pi. This formalism of a reinforcement learning application actually has a name. It’s called a Markov decision process
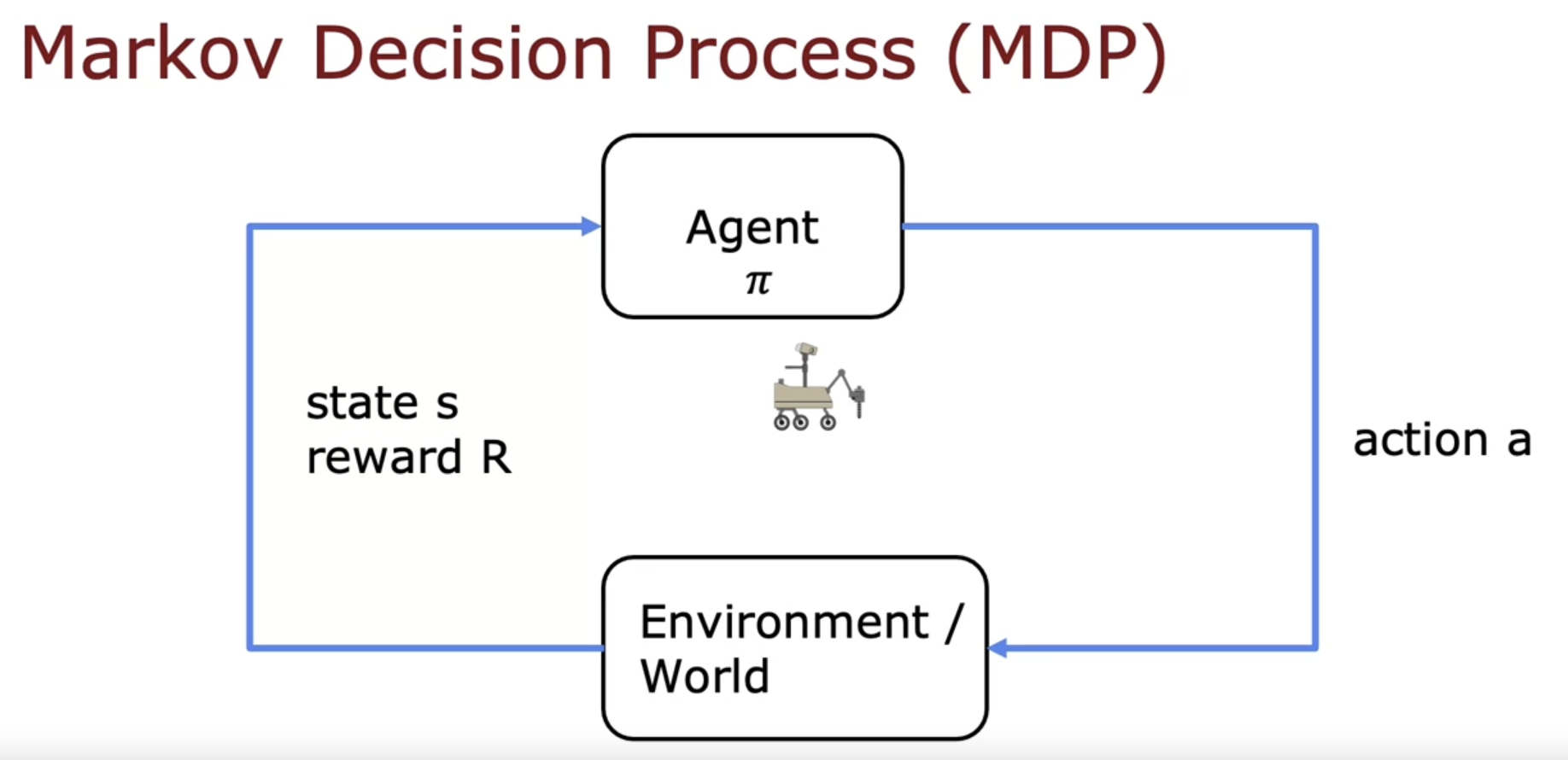
- in a Markov decision process, the future depends only on where you are now, not on how you got here.
2. State-action value function
In reinforcement learning, there’s a key equation called the Bellman equation that will help us to compute the state action value function.
