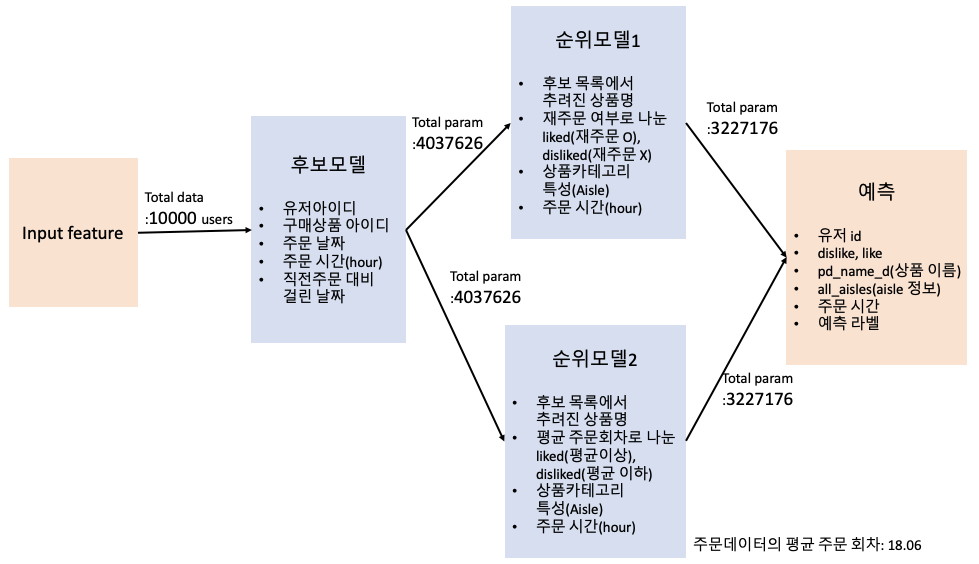
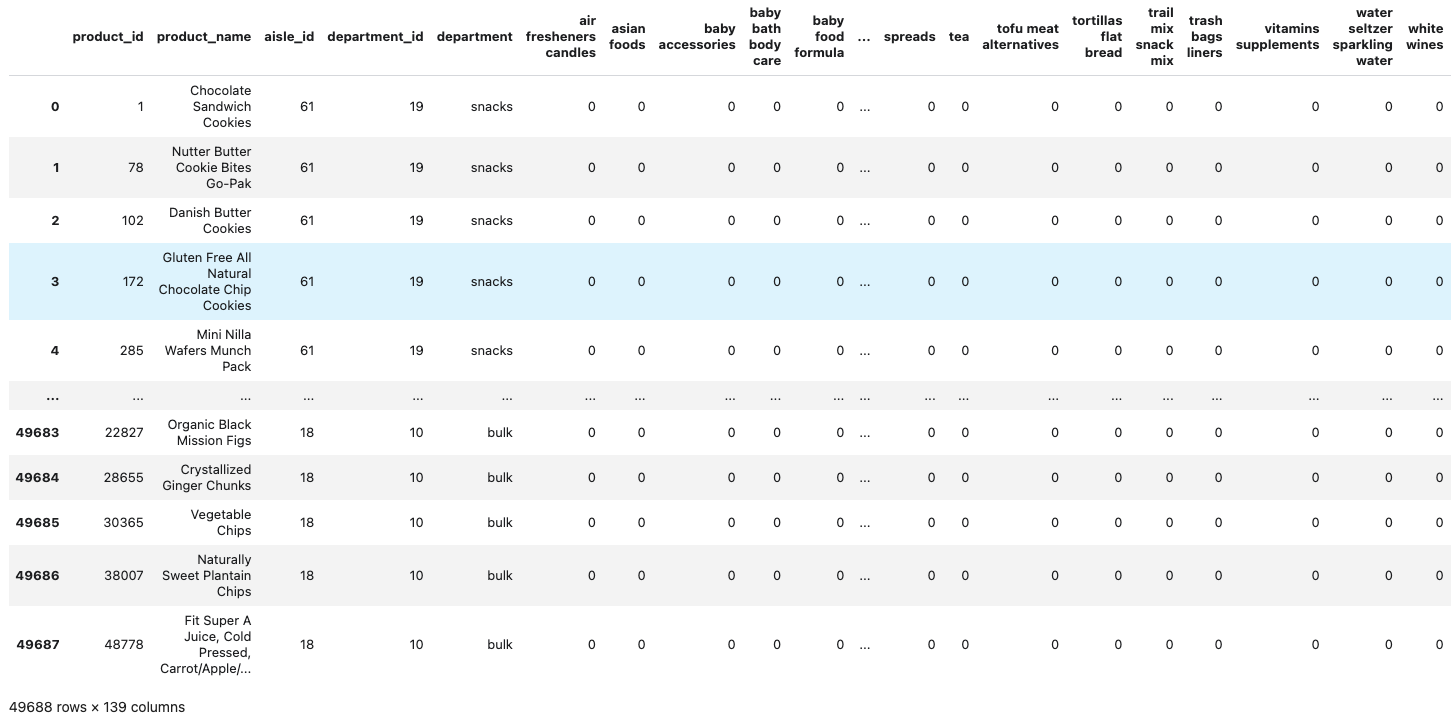
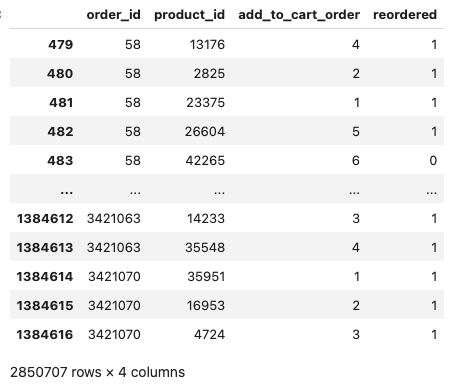
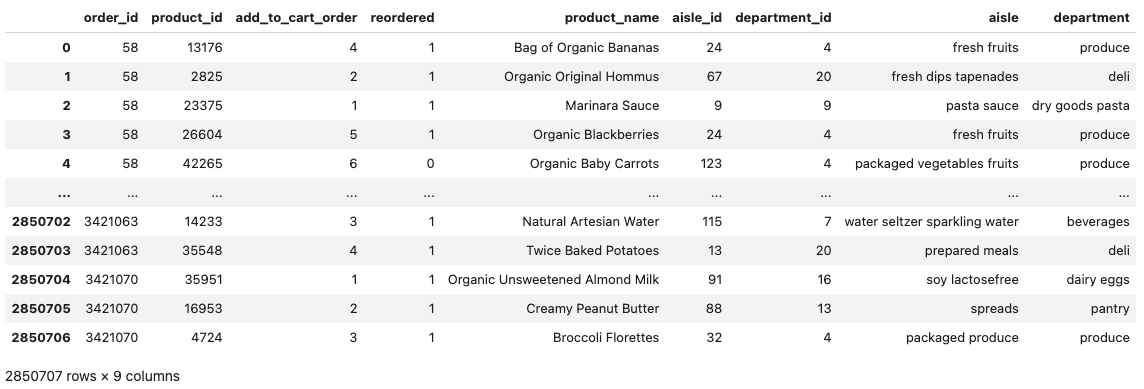
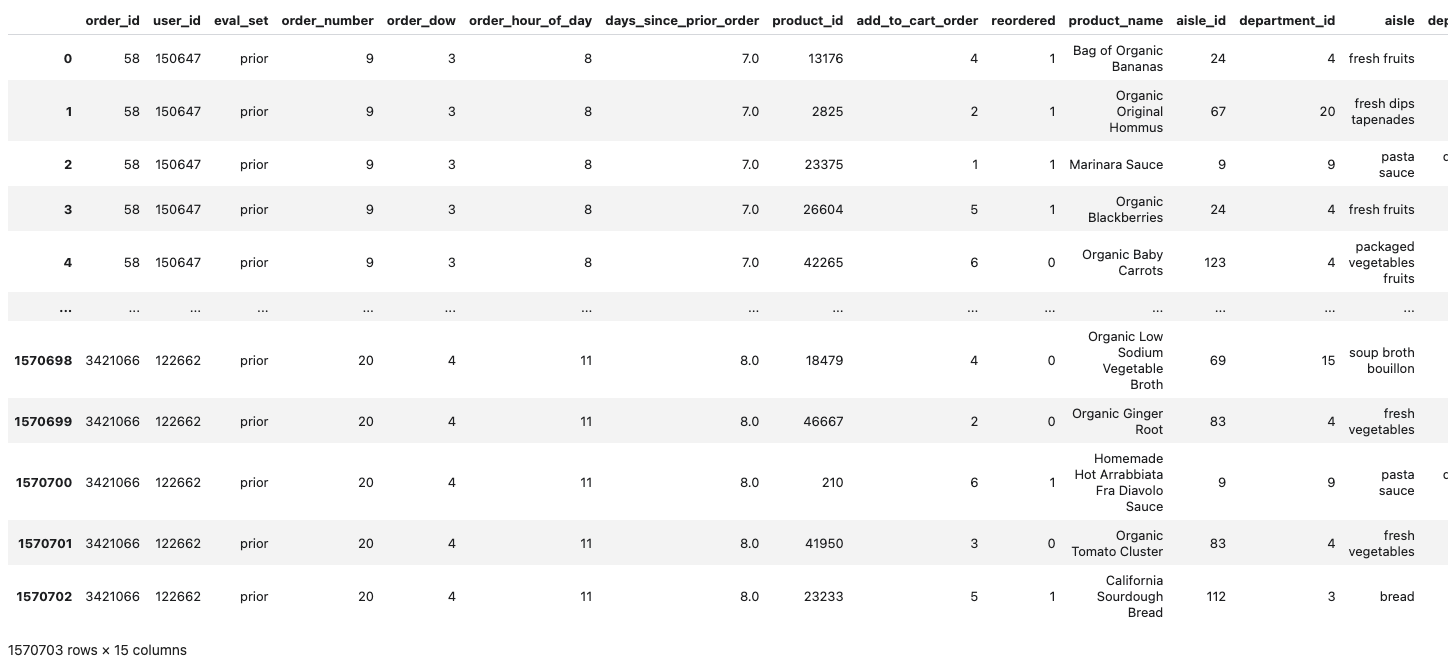
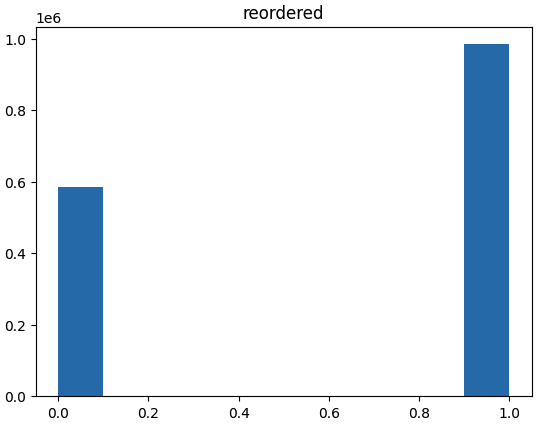
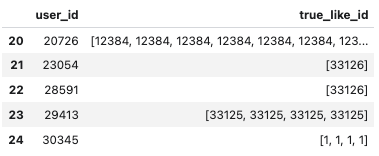
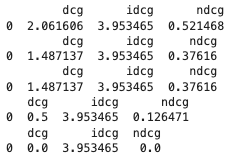
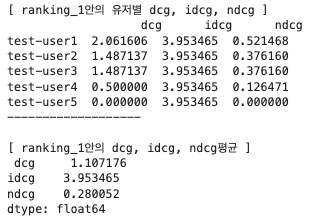
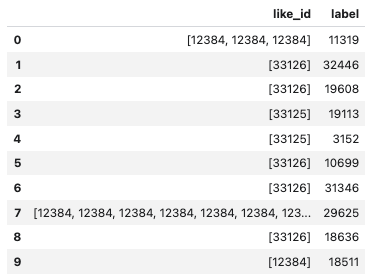
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
import tensorflow as tf
import datetime
import os
input_name = tf.keras.Input(shape=(None, ), name='product_name')
inp_item_liked = tf.keras.layers.Input(shape=(None,), name='like')
inp_item_disliked = tf.keras.layers.Input(shape=(None,), name='dislike')
input_aisle = tf.keras.Input(shape=(None, ), name='aisle')
input_order_hour = tf.keras.Input(shape=(None, ), name='order_hour')
features_embedding_layer = tf.keras.layers.Embedding(input_dim=NUM_CLASSES, output_dim=EMBEDDING_DIMS,
mask_zero=True, trainable=True, name='features_embeddings')
labels_embedding_layer = tf.keras.layers.Embedding(input_dim=NUM_CLASSES, output_dim=EMBEDDING_DIMS,
mask_zero=True, trainable=True, name='labels_embeddings')
avg_embeddings = MaskedEmbeddingsAggregatorLayer(agg_mode='mean', name='aggregate_embeddings')
dense_1 = tf.keras.layers.Dense(units=DENSE_UNITS, name='dense_1')
dense_2 = tf.keras.layers.Dense(units=DENSE_UNITS, name='dense_2')
dense_3 = tf.keras.layers.Dense(units=DENSE_UNITS, name='dense_3')
l2_norm_1 = L2NormLayer(name='l2_norm_1')
dense_output = tf.keras.layers.Dense(NUM_CLASSES, activation=tf.nn.softmax, name='dense_output')
features_embeddings = features_embedding_layer(input_name)
l2_norm_features = l2_norm_1(features_embeddings)
avg_features = avg_embeddings(l2_norm_features)
labels_liked_embeddings = labels_embedding_layer(inp_item_liked)
l2_norm_liked = l2_norm_1(labels_liked_embeddings)
avg_liked = avg_embeddings(l2_norm_liked)
labels_disliked_embeddings = labels_embedding_layer(inp_item_disliked)
l2_norm_disliked = l2_norm_1(labels_disliked_embeddings)
avg_disliked = avg_embeddings(l2_norm_disliked)
labels_aisle_embeddings = labels_embedding_layer(input_aisle)
l2_norm_aisle = l2_norm_1(labels_aisle_embeddings)
avg_aisle = avg_embeddings(l2_norm_aisle)
labels_order_hour_embeddings = labels_embedding_layer(input_order_hour)
l2_norm_order_hour = l2_norm_1(labels_order_hour_embeddings)
avg_order_hour = avg_embeddings(l2_norm_order_hour)
concat_inputs = tf.keras.layers.Concatenate(axis=1)([avg_features,
avg_liked,
avg_disliked,
avg_aisle,
avg_order_hour
])
dense_1_features = dense_1(concat_inputs)
dense_1_relu = tf.keras.layers.ReLU(name='dense_1_relu')(dense_1_features)
dense_1_batch_norm = tf.keras.layers.BatchNormalization(name='dense_1_batch_norm')(dense_1_relu)
dense_2_features = dense_2(dense_1_relu)
dense_2_relu = tf.keras.layers.ReLU(name='dense_2_relu')(dense_2_features)
dense_3_features = dense_3(dense_2_relu)
dense_3_relu = tf.keras.layers.ReLU(name='dense_3_relu')(dense_3_features)
dense_3_batch_norm = tf.keras.layers.BatchNormalization(name='dense_3_batch_norm')(dense_3_relu)
outputs = dense_output(dense_3_batch_norm)
optimiser = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
model = tf.keras.models.Model(
inputs=[input_name,
inp_item_liked,
inp_item_disliked,
input_aisle,
input_order_hour,
],
outputs=[outputs]
)
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
model.compile(optimizer=optimiser, loss='sparse_categorical_crossentropy', metrics=['acc'])
model.summary()
|