개요
- 이전 포스트의 5단계에서 ML 모델을 평가할때 나왔던 지표들에 대한 소개
- 바이너리 로지스틱 회귀 모델을 사용했을 때 모델의 성능을 평가하는 지표들을 소개
알아야 할 개념
True/False & Positive/Negative
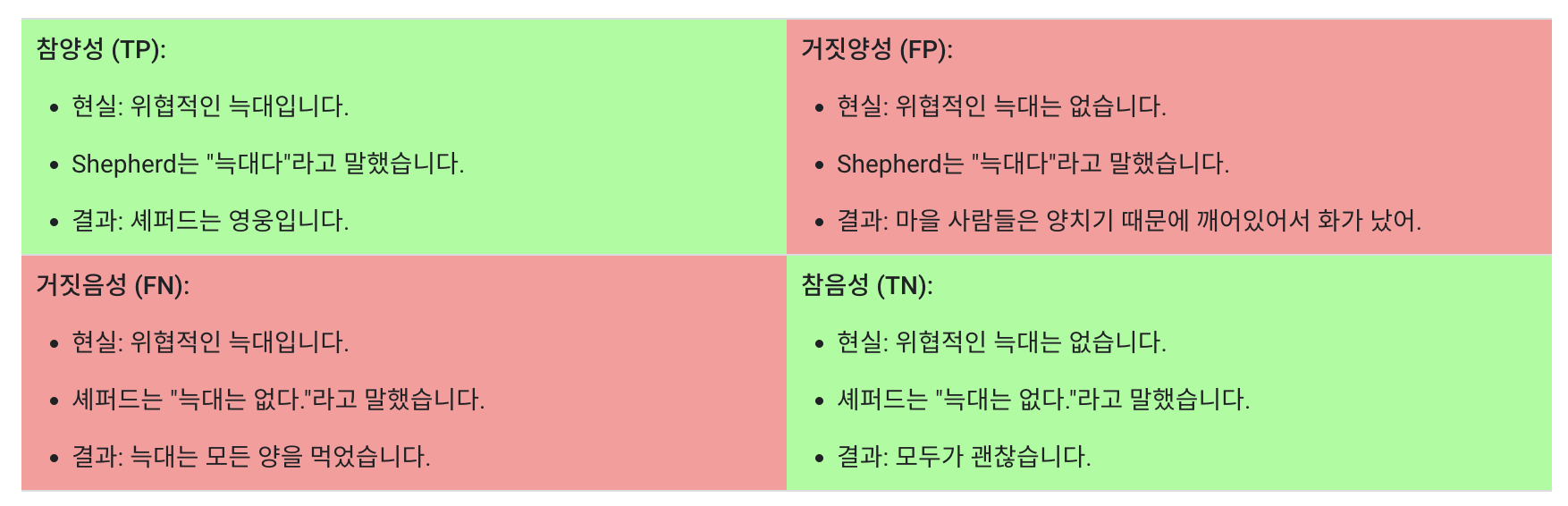
- 임계값(Threshold)
- 로지스틱 회귀 값을 이진 카테고리에 매핑하려면 분류 임계값(결정 임계값)을 정의 해야 함
- 일반적으로 0.5로 잡지만, 데이터나 상황에 따라서 달라질수 있으므로 조정해야 하는 값.
- 정밀도(Precision) = $\frac{TP}{TP+FP}$
- 거짓 양성(FP)이 생성되지 않는 모델의 정밀도는 1.0
- 재현율(Recall) = $\frac{TP}{TP+FN}$
- 거짓 음성(FN)을 생성하지 않는 모델의 재현율은 1.0
- 실제 양성 중 정확히 양성이라고 식별된 사례의 비율
- 정확도(Accuracy) = $\frac{올바른 예측값}{전체 예측 값}$
- 이진분류에서 정확도 = $\frac{TP+TN}{TP+TN+FP+FN}$
- 비 공식적으로 모델이 올바르게 예측한 비율
- 클래스간 데이터 차이가 있다면 정확하지 않을 가능성이 높음
- ROC curve
- 모든 분류 임계값에서 분류 모델의 성능을 보여주는 그래프
- 참 양성률(TPR)과 거짓양성률(FPR)을 매개변수로 표시한다.
- 분류 임계값을 낮추면 더 많은 항목이 양수로 분류 되므로 거짓양성과 참 양성이 모두 증가한다.
- ROC 곡선의 포인트를 계사나기 위해 분류 입곗값이 다른 여러차례의 로지스틱 회귀모델을 평가했지만 이는 비효율적 → 이러한 정보제공을 할수 있는 효율적인 정렬기반 알고리즘인 AUC를 사용하는 이유
- AUC: ROC 곡선 아래의 영역
- ROC 곡선의 적분값
- 0부터 1사의 값
- 절댓값이 아닌 예측의 순위를 측정하므로 규모 불변
- 선택한 분유 임곗값과 관계 없이 모델의 예측 품질을 측정하기에 분류 기준 불변
- 주의 사항
- 확장 불변이 항상 바람직한것은 아님 → 잘 보정된 확률 출력이 필요한 경우가 있는데 AUC는 이를 알려주지 않음
- 분류 임계값 불변이 항상 바람직한 것은 아님 → 거짓음성 대비 거짓양성의 비용이 큰 경우 한 자기 유형의 분류 오류를 최소화 하는 것이 중요함. 예를 들어 스팸 감지를 실행할때 거짓 양성을 최소화하는 것이 중요할 수 있음.(이렇게 하면 거짓 음성이 크게 증가하더라도 상관 없음) AUC는 이 유형의 최적화에 유용한 측정항목이 아님.
GCP 공식 설명
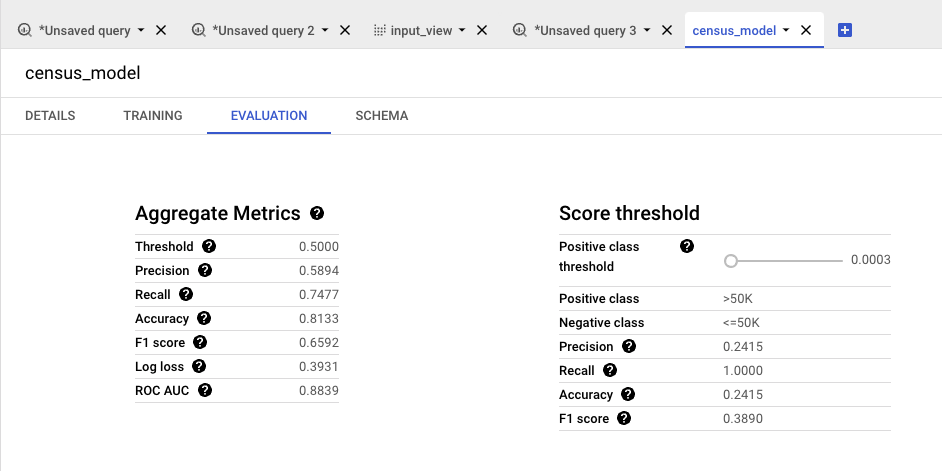
Aggregate Metrics
- For binary classification models, all metrics reflect the values computed when threshold is set to 0.5.
- 이진 분류 모델의 경우 모든 지표는 임계값을 0.5로 설정했을 때 계산된 값을 반영합니다.
- Threshold : For binary classification models, this is the positive class threshold.
- 이진 분류 모델의 경우 이는 양성 클래스의 임계값을 뜻합니다.
- Precision : Fraction of predicted positives that were actual positives.
- 예측된 양성 반응 중 실제 양성 반응으로 판명된 비율입니다. → 학습 모델이 판단한 양성 비율
- Recall : Fraction of actual positives that were predicted positives.
- 예측된 양성 반응 중 실제 양성 반응의 비율입니다. → 실제 양성이라고 나온 비율
- Accuracy : Fraction of predictions given the correct label.
- 올바른 레이블이 주어진 예측의 비율입니다. → precision과 recall 을 비교했을 때 학습 모델이 맞춘 비율
- F1 score : Harmonic mean of precision and recall.
- 정확도 및 회수율의 조화 평균입니다.
- Precision 과 Recall은 서로 Trade-off 관계를 가지면서 접근하는 방식도 Precision은 모델의 예측, Recall은 정답 데이터 기준이므로 서로 상이 합니다.
- 하지만 두 지표 모두 모델의 성능을 확인하는 데 중요하므로 둘 다 사용되어야 합니다. 따라서 두 지표를 평균값으로 통해 하나의 값으로 나타내는 방법으로 F1 score를 사용합니다.
- 극단적으로 Precision과 Recall 중에 한쪽이 1에 가깝고 한쪽이 0에 가까운 경우 산술 평균과 같이 0.5가 아니라 0에 가깝도록 만들어 줍니다. 따라서 F1 score를 높이려면 Precision, Recall이 균일한 값이 필요 하기 때문에 두 지표 성능을 모두 높일 수 있도록 해야 합니다.
- $F_1 = 2*\frac{precision X recall}{precision + recall}$
- Log loss : A measure for model performance between 0 (perfect) and 1. The greater the log-loss, the greater the predicted probability diverges from the actual label.
- 0(완벽)에서 1 사이의 모델 성능 측정값입니다. 로그 손실이 클수록 예측 확률이 실제 레이블과 차이가 커집니다.
- ROC AUC : Area under the receiver operating characteristic curve.
Score threshold
- Positive class threshold: Predictions above the threshold are classified as positive.
- 임계값을 초과하는 예측은 양수로 분류됩니다.
- Positive class >50K
- Negative class <=50K
- Precision : Fraction of predicted positives that were actual positives.
- 예측된 양성 반응 중 실제 양성 반응으로 판명된 비율입니다.
- Recall: Fraction of actual positives that were predicted positives.
- 예측된 양성 반응 중 실제 양성 반응의 비율입니다.
- Accuracy : Fraction of actual positives that were predicted positives.
- 올바른 레이블이 주어진 예측의 비율입니다.
- F1 score : Harmonic mean of precision and recall.
- 정밀도 및 회수율의 조화 평균입니다.
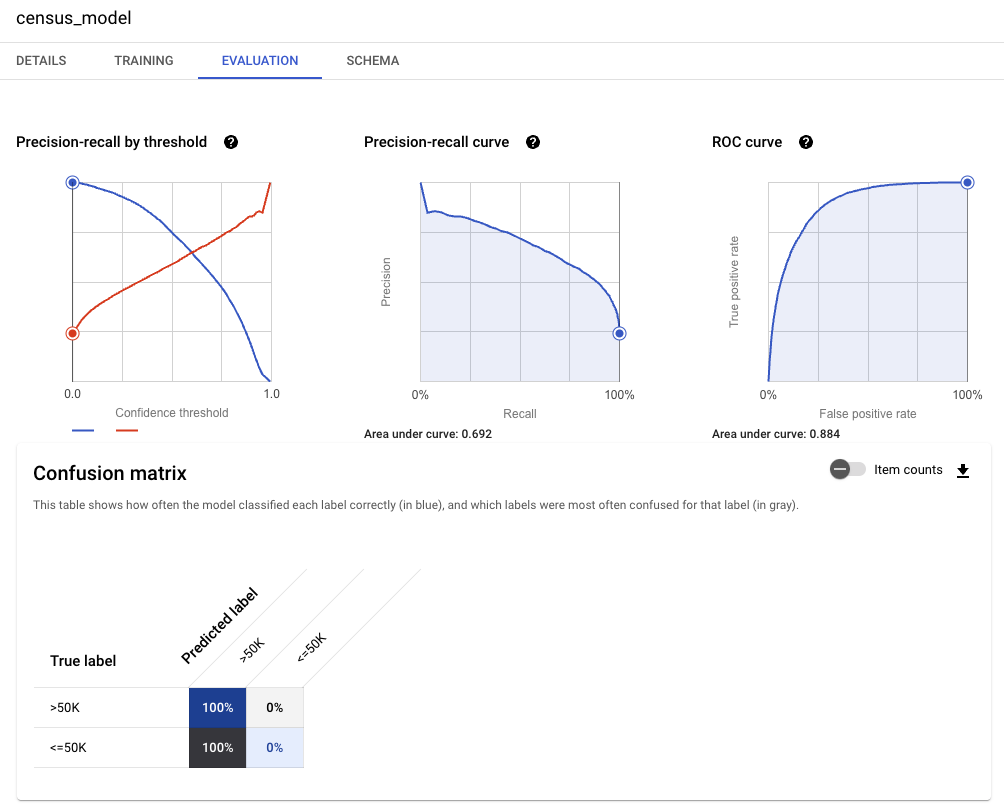
Precision-recall by threshold: Shows how your model performs on the top-scored label along the full range of confidence threshold values. A higher confidence threshold produces fewer false positives, which increases precision. A lower confidence threshold produces fewer false negatives, which increases recall.
- 전체 신뢰도 임계값 범위에서 가장 높은 점수를 받은 레이블에 대한 모델의 성능을 표시합니다.
- 신뢰도 임계값이 높을수록 false positive 값이 줄어들어 정밀도가 높아집니다.
- 신뢰도 임계값이 낮을수록 false negative 값이 줄어들어 회수율이 높아집니다.
Precision-recall curve: Shows the trade-off between precision and recall at different confidence thresholds. A lower threshold results in higher recall but typically lower precision, while a higher threshold results in lower recall but typically with higher precision.
- 서로 다른 신뢰 임계값에서 정밀도와 리콜 간의 균형을 표시합니다.
- 임계값이 낮을수록 회수율은 높지만 일반적으로 정밀도는 낮으며
- 임계값이 높을수록 회수율은 낮아지지만 일반적으로 정밀도가 높습니다.
ROC curve: The receiver operating characteristic (ROC) curve shows the trade-off between true positive rate and false positive rate. A lower threshold results in a higher true positive rate (and a higher false positive rate), while a higher threshold results in a lower true positive rate (and a lower false positive rate)
- receiver operating characteristic(ROC) 곡선은 true positive의 비율과 false positive의 비율 사이의 균형을 보여줍니다.
- 임계값이 낮을수록 true positive의 비율(및 false positive의 비율)이 높아지고, 임계값이 높을수록 true positive의 비율(및 false positive의 비율)이 낮아집니다
Confusion matrix
This table shows how often the model classified each label correctly (in blue), and which labels were most often confused for that label (in gray).
- 이 표는 모델이 각 레이블을 올바르게 분류한 빈도(파란색)와 해당 레이블과 가장 자주 혼동되는 레이블(회색)을 보여줍니다.