요약
- Kaggle 데이터 다운로드
- GCP에 데이터 세트 만들고 서비스 계정 생성하기
- Python-BigQuery 연결 후 데이터 조회
- 데이터 적재 하기
Kaggle 데이터 다운로드
kaggle을 설치한다
1
!pip install kaggle
kaggle의 key를 받아온다
1
2
3!mkdir ~/.kaggle
!echo '{"username":"your_id","key":"your_key"}' > ~/.kaggle/kaggle.json
!chmod 600 ~/.kaggle/kaggle.jsonkaggel TOKEN 받아오기
kaggle에 접속한다음 프로필을 선택하고 Account를 누른다
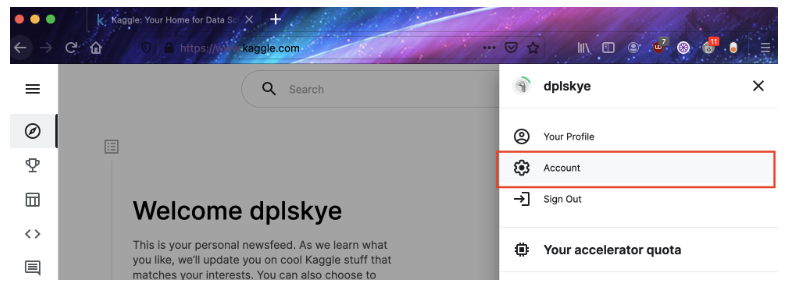
화면을 내리면
API 탭을 찾을수 있다.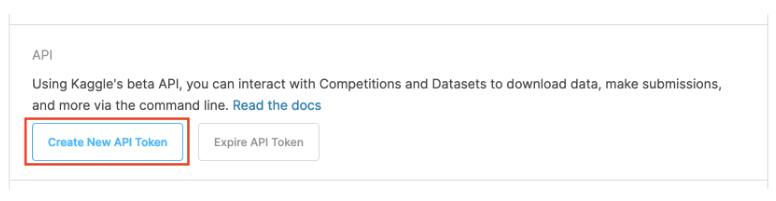
Create New API Token을 누르고 다운
kaggle.json파일을 받아줍니다.한번 발급 받으면 이전의 것은 알려주지 않기 때문에 잊어버렸다면
Expire API TOKEN으로 모두 지고 새로운 토큰을 받는다.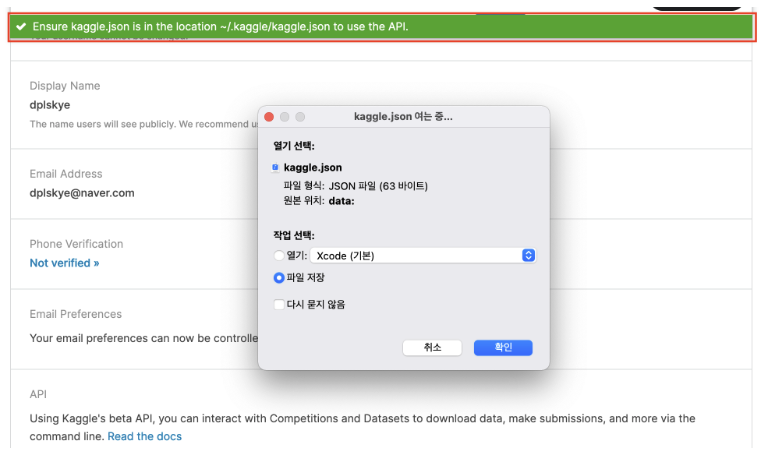
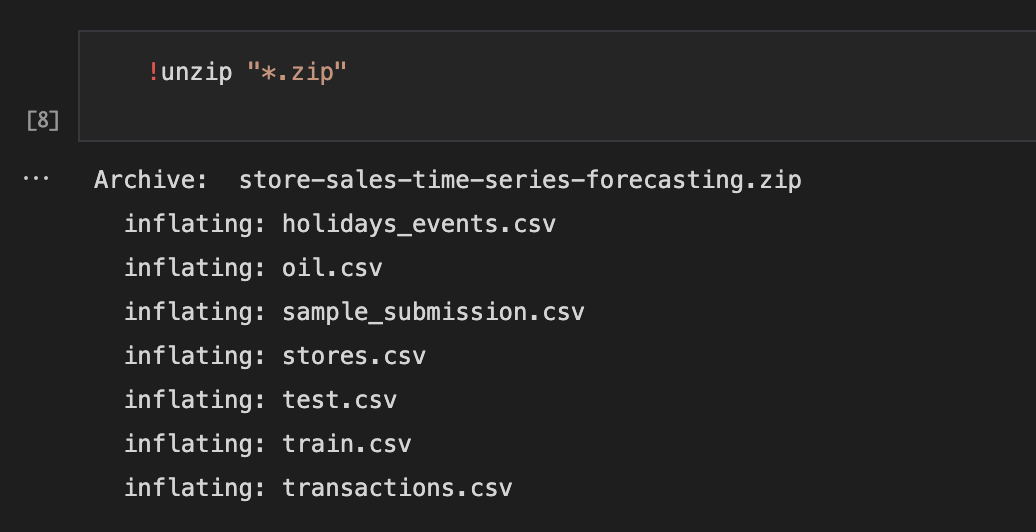
kaggle에서 원하는 데이터를 다운 받아준다 → competitions에서 원하는 competition을 선택하고 data 탭으로 가면 다운 받을 수 있는 api가 있다.


GCP에 데이터 세트 만들고 서비스 계정 생성하기
GCP에 프로젝트를 만들고 새로운 데이터 세트를 만들어 준다
중간에 Default table expiration 을 클릭하면 테이블이 며칠 후에 만료되는지도 설정 가능하다
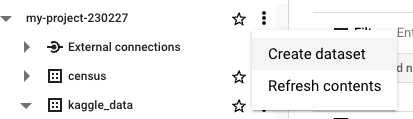
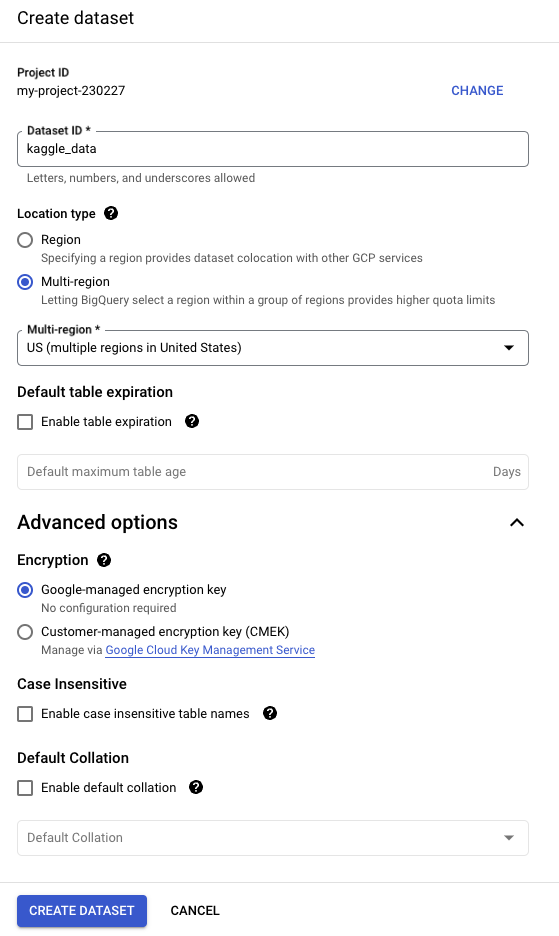
서비스 계정 생성
GCP 좌측 상단 ‘탐색 메뉴’ 클릭후 ‘IAM 및 관리자’의 ‘서비스 계정’으로 이동
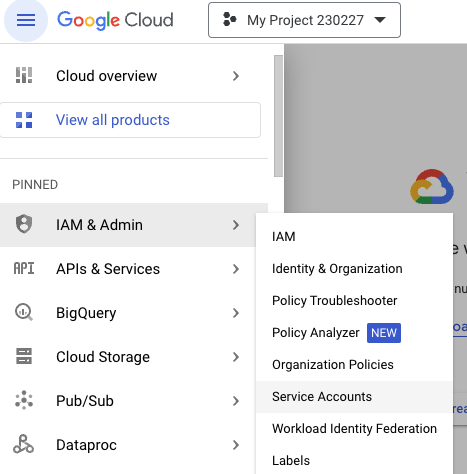
‘+ 서비스 계정 만들기’ 클릭 후 서비스 계정 만들기 진행

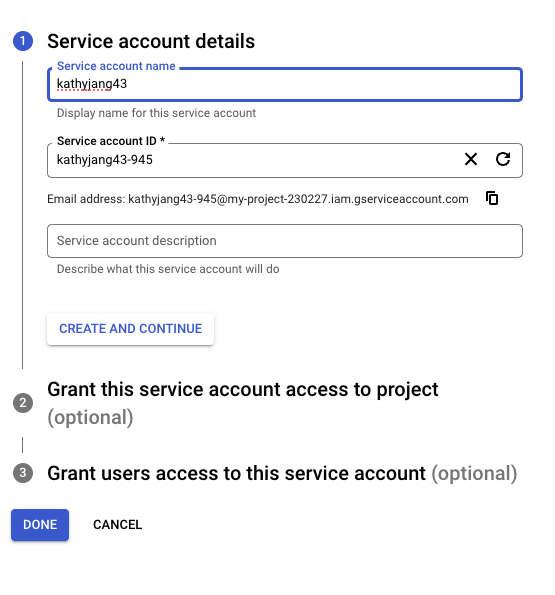
서비스 계정 키 생성 후 JSON 파일 추출
Email에 생성된 서비스 계정 클릭 → 페이지 상단에 KEYS → ADD KEY → Create new key
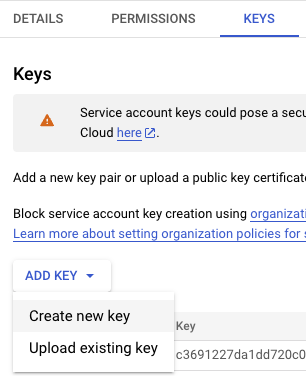
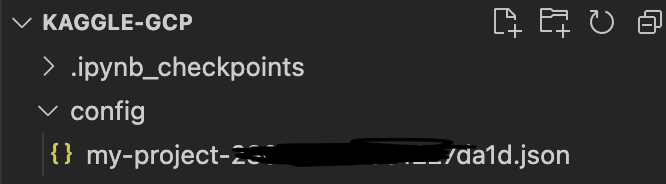
config 폴더 생성 후 해당 경로에 json 파일 다운로드

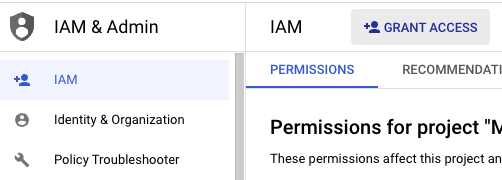
서비스 계정에 빅쿼리 관련 역할 추가
GCP 좌측 상단 ‘탐색 메뉴’ 클릭후 ‘IAM 및 관리자’의 ‘IAM’으로 이동
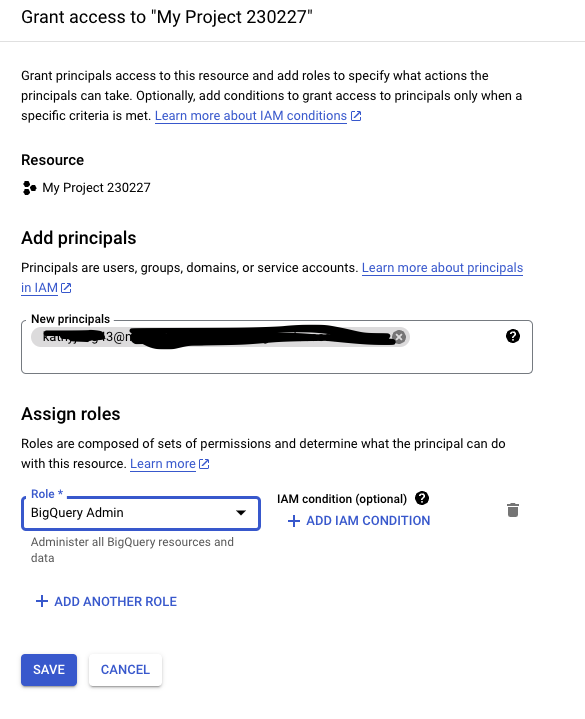
‘추가’ 클릭 - 생성된 서비스 계정 이메일 추가 및 ‘BigQuery 관리자’ 역할 선택 후 저장
Python-BigQuery 연결 후 데이터 조회
구글 클라우드 빅쿼리 클라이언트 설치
1
!pip install google-cloud-bigquery
서비스 계정 키 설정 → 빅쿼리 클라이언트 정의 → 데이터 조회 쿼리 실행
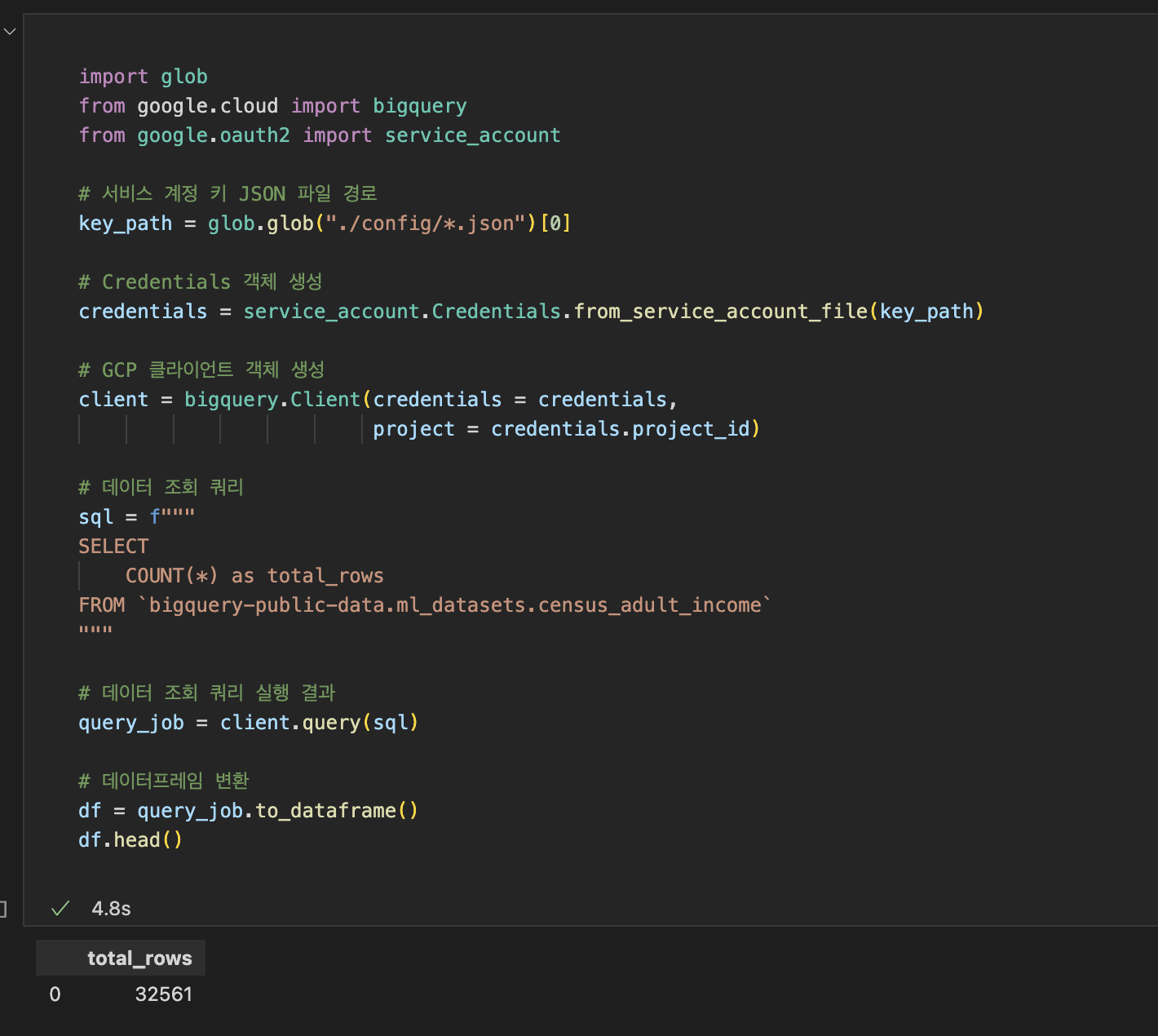
데이터 적재 하기
데이터를 불러온다
1
2
3
4
5
6
7import pandas as pd
BASE_DIR = "./"
train = pd.read_csv(BASE_DIR + 'train.csv')
test = pd.read_csv(BASE_DIR + 'test.csv')
train.shape, test.shape1
((3000888, 6), (28512, 5))
데이터를 적재 한다
1
2
3
4
5
6
7
8
9
10from google.oauth2 import service_account
import pandas_gbq
cd = service_account.Credentials.from_service_account_file("./config/my-project-230227-c3691227da1d.json")
project_id = 'my-project-230227'
train_table = 'kaggle_data.train'
test_table = 'kaggle_data.test'
train.to_gbq(train_table,project_id,if_exists='replace',credentials=cd)
test.to_gbq(test_table,project_id,if_exists='replace',credentials=cd)
print('migration complete')
GCP에 들어가서 확인해 본다
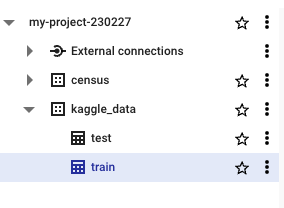
이렇게 테이블을 gcp에 적재하면 데이터들을 다양한 방면으로 사용이 가능하다: Looker Studio를 이용한 시각화