1. What is K-means Clustering
- The K-Means clustering algorithm does not automatically identify and group the number of clusters by looking at the data.
- The number of clusters should be specified and the initial value should be selected accordingly by user.
- How to determine the number of clusters
- use the indicator that quantifies how well clustering has been done.
- After deciding the candidates of cluster numbers and performing clustering about each cluster number, calculate the index
- At this time, we select the number of clusterings that optimize the index as the optimal number of clusters.
- The frequently used indicators include Dunn Index, and Silhouette Index.
- How to determine the number of clusters
- The algorithm assigning the group determines the initial value which is the initial center point of the group.
- Each center point determines a group, and individual data is assigned to the same group as the center point close to itself.
- It does not end at once (depending on the form of the data) but repeats the process of updating the center of the group and assigning groups of individual data again.
- It belongs to the hard clustering algorithm, which is a clustering that unconditionally assigns a group of data points to a point close to the center.
2. Pros & Cons
- Advantages
- The process is intuitive, easy to understand, and the algorithm is simple so that it is easy to implement.
- It does not require complex calculations, so it can be applied to large-scale data.
- convergence is guaranteed.
- Disadvantages
- The result can be very different depending on the initial value.
- Can be affected by an outlier: because the distance is based on Euclidean Distance, it can be affected by an outlier in the process of updating the center value.
- Cannot reflect intra-group dispersion structure: Since the distance is based on Euclidean Distance, it cannot properly reflect the intra-group dispersion structure.
- As the dimensionality increases, the distance between individual data becomes closer, and the effect of clustering may not be effective.
This has the meaning of clustering only when the distance between clusters is kept as far apart as possible, but as the dimensionality increases, the distance between individual data becomes closer, so this effect may not be observed. - The number of clusters is not set automatically, but must be set in advance. However, the optimal number of clusters can be determined using indicators such as Dunn Index and Silhouette Index.
- Because of Euclidean Distance, it cannot be used if there is a categorical variable. In this case, it is possible to use the extended K-Modes Clustering algorithm.
3. Using python: scikit-learn
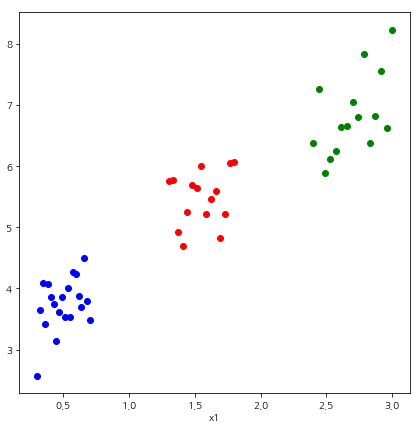
Put 3 in n_clusters and init_center in init, and create a KMeans instance.
If you put data(X) into the fit function, clustering is performed.
The final label can be obtained through the labels_ field.
1
2
3
4
5
6
7import warnings
warnings.filterwarnings('ignore')
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, init=init_center)
kmeans.fit(X)
labels = kmeans.labels_Visualization
1
2
3
4
5
6
7
8
9
10
11
12
13
14fig = plt.figure(figsize=(7,7))
fig.set_facecolor('white')
for i, label in enumerate(labels):
if label == 0:
color = 'blue'
elif label ==1:
color = 'red'
else:
color = 'green'
plt.scatter(X[i,0],X[i,1], color=color)
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()