Journal/Conference : INTERSPEECH
Year(published year): 2023
Author: Tran, M., Yin, Y., Soleymani, M.
Subject: Speech Emotion Recognition, Personalization, Adaptation
Personalized Adaptation with Pre-trained Speech Encoders for Continuous Emotion Recognition
Abstract
- To achieve unsupervised personalized emotion recognition, we first pre-train an encoder with learnable speaker embeddings in a self-supervised manner to learn robust speech representations conditioned on speakers.
- We propose an unsupervised method to compensate for the label distribution shifts by finding similar speakers and leveraging their label distributions from the training set.
Introduction
(1) What happens to the personalization gap as the number of speakers increases for fine-tuned encoders?
(2) How do existing personalization methods behave when the input speech features are not fixed?
(3) How can we incorporate personalization with pre-trained encoders to boost performance?
We first show that as the number of speakers increases, the personalization gap (the performance difference between speaker-dependent and speaker-independent) of fine-tuned models decreases, which motivates the need for methods that adapts the pre-trained weights for personalization prior to fine-tuning. Hence, we propose to continue the pre-training process of the speech encoder jointly with speaker embeddings (see Figure 2 (a)).
We also introduce a simple yet effective unsupervised personalized calibration step to adjust label distribution per speaker for better accuracy (see Figure 2 (b)). The proposed methods are unsupervised, requiring no prior knowledge of the test labels.
The major contributions of this work are as follows.
(1)We propose a method for personalized adaptive pre-training to adjust the existing speech encoders for a fixed set of speakers.
(2) We propose an unsupervised personalized post-inference technique to adjust the label distributions.
(3)We provide extensive experimental results along with an ablation study to demonstrate the effectiveness of the methods.
(4) We further show that our methods can be extended to unseen speakers without the need to re-train any component, achieving superior performance compared to the baselines
Related work
Adaptive Pre-training
- In the field of speech emotion recognition, Chen et al. [10] propose a novel pseudo-label generation method in combination with task-adaptive pre-training for wav2vec2.0 [12] to boost emotion recognition accuracy. However, there is no prior work exploring personalized adaptive pre-training.
Personalized Speech Emotion Recognition
Most relevant to our work is the unsupervised personalized method proposed by Sridhar et al. [14], which is validated on the same dataset (MSP-Podcast) as in this paper. They propose to find speakers in the train set to form the adaptation set whose acoustic patterns closely resemble those of the speakers in the test set. Specifically, they apply Principal Component Analysis (PCA) on the feature set proposed for the computational paralinguistics challenge (ComParE) [19] and fit Gaussian Mixture Models to measure the speaker similarity based on the KL divergence metric.
we explore personalization with fine-tuned encoders instead of pre-extracted features, which achieves superior performance compared to the best-performing models. For example, our weakest baseline (HuBERT-large fine-tuning) achieves a two times higher Concordance Correlation Coefficient (CCC) compared to the reported results from Sridhar et al. [14] for valence estimation. More importantly, our method is extensible and remains effective for unseen speakers without the need to re-train any components.
Preliminary information
Problem Formulation
- Our goal is to produce a robust emotion recognition model that performs better than a model exposed to the same amount of data excluding speaker ID information. We further want our method to be extensible to new speakers outside of D.
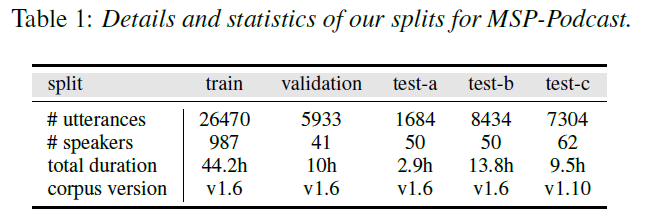
Dataset
We use the MSP-Podcast corpus [13] as our dataset D. MSP-Podcast is the largest corpus for speech emotion recognition in English, containing emotionally rich podcast segments retrieved from audio-sharing websites.
In this paper, we focus on arousal and valence estimation. The labels range from 1 to 7. The dataset contains pre-defined train, validation, and test sets, namely $D_{tr}, D_{val}, D_{te}$, which are subject independent.
We use two versions of the dataset, namely v1.6 and v1.10, for the experiments. To be consistent with prior studies [20, 14, 9], most of our experiments are based on MSP-Podcast v1.6. We remove all the utterances marked with “Unknown” speakers in accordance with our problem formulation.
Pre-trained Speech Encoder
HuBERT consists of two main components, namely a 1D CNN and a Transformer encoder [22]. The 1D CNN takes raw waveforms as inputs and returns low-level feature representations of speech.
Therefore, the pre-training loss $L_{pt}$ for HuBERT can be defined as the sum of the cross-entropy loss computed over the masked frames.
Personalization Gap
- The concept of the personalization gap is introduced and investigated. The personalization gap refers to the performance difference between speaker-dependent models (trained on data specific to individual speakers) and speaker-independent models (trained without considering speaker information). The study explores how the personalization gap changes as the number of speakers in the dataset increases. By conducting experiments with subsets of data containing different numbers of speakers, the authors demonstrate that as the dataset becomes more diverse with a larger number of speakers, the personalization gap decreases.
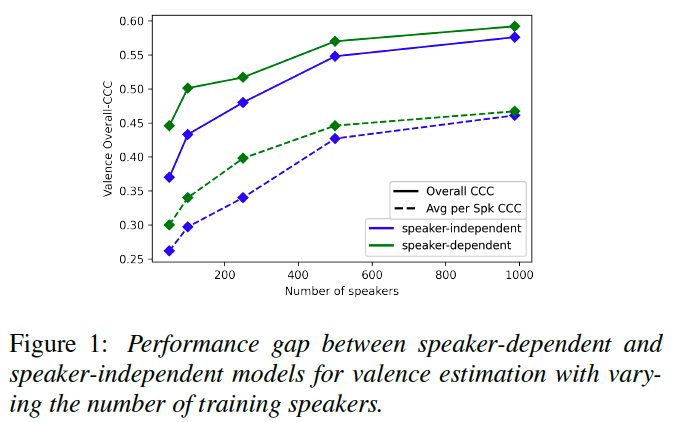
Figure 1 demonstrates the inverse relationship between k and the performance gap.
It suggests that given sufficiently large and diverse training data, the pre-trained encoders become robust enough to learn both the general emotional patterns and the unique characteristics of different groups of speech expressions such that supervised training of the model on the test speakers leads to marginal gains.
Hence, to enhance the performance of the pre-trained encoders for a target speaker, we can: (1) make the input data personalized (pre-processing); (2) modify the weights of the pre-trained encoder for the target speaker; or (3) adjust the label predictions to be more personalized (post-processing). Existing studies on personalized SER, e.g., [5, 8, 14], focus on the first approach.
Performance variance across speakers
We investigate whether the performance variance is due to the feature shift or the label shift. Specifically, to measure the feature and label shift for each target speaker, we calculate the KL divergence between the feature and label distributions of the target speaker and those of the whole training set. Then we calculate the Pearson correlation coefficient (PCC) between the feature/label shift and the speaker performance. For arousal estimation, we find that the PCC between the feature shift and the regression performance is −0.714 while the PCC between the label shift and performance is −0.502.
The results suggest that both feature and label shifts contribute to the performance variance. Moreover, the correlation between the feature shift and label shift is 0.285, which suggests the potential of using features to detect and remove label shifts.
- 화자 간 성능 차이를 논의하는 섹션에서는 데이터 세트의 여러 화자에서 관찰되는 성능의 변동성에 기여하는 요인을 살펴봅니다. 이 맥락에서 언급되는 두 가지 핵심 개념은 feature shift와 label shift입니다:
- feature shift: 특징 이동은 개별 화자 간의 입력 특징(예: 음성의 음향적 특성) 분포의 차이 또는 변동을 의미합니다. 음성 감정 인식의 맥락에서 화자마다 음성 패턴, 억양 또는 기타 음향적 특징에 차이가 있을 수 있으며, 이는 모델의 정확한 감정 인식 능력에 영향을 미칠 수 있습니다. 특징 편차는 특정 화자의 입력 특징이 훈련 세트의 전체 특징 분포에서 얼마나 벗어나는지를 정량화 합니다.
- label shift: 반면에 레이블 이동은 여러 화자에 걸쳐 음성 샘플에 할당된 감정 레이블 분포의 불일치 또는 변화와 관련이 있습니다. 이는 데이터 세트에서 화자마다 감정 주석(레이블)의 분포가 달라지는 것을 반영합니다. 라벨 이동은 개인이 감정을 표현하거나 인지하는 방식의 차이로 인해 발생할 수 있으며, 화자 간 일관된 감정 인식에 문제를 일으킬 수 있습니다.
- 이 논문은 데이터 세트의 각 대상 화자에 대한 특징 및 라벨 이동을 분석하여 이러한 이동이 음성 감정 인식 작업에서 화자 간에 관찰되는 성능 차이에 어떻게 기여하는지 이해하는 것을 목표로 합니다. 특징 이동, 라벨 이동, 화자 성능 간의 상관관계는 모델이 다양한 화자에 대해 감정을 정확하게 인식하는 능력에 영향을 미치는 요인을 파악하는 데 도움이 됩니다.
Method
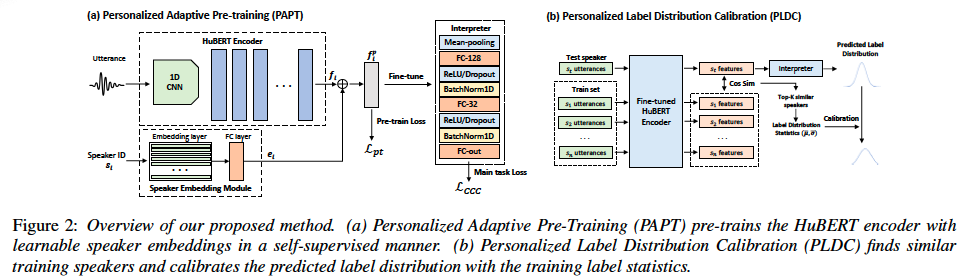
Personalized Adaptive Pre-training (PAPT)
we propose to perform adaptive pre-training on $D = {(u_i, s_i)}^N_{i=1}$ along with trainable speaker embeddings in a self-supervised manner.
Specifically, in addition to the original speech encoder E, we train a speaker embedding network S to extract the speaker embedding $e_i = S(s_i) ∈ R^d$, where d is the embedding size for the Transformer.
Then, the speaker embedding $e_i$ is summed with the utterance feature $f_i = E(u_i)$ to get a personalized feature representation $f^p_i = f_i + e_i$. For personalized pre-training, $f^p_i$ is used to compute the pre-training loss (cross-entropy) on pseudo-label prediction for masked frames.
$L_(pt) = - \sum\limits_{i=1}^{N_b} \sum\limits_{t=1}^{M_i}logP(l_{it}|f_{it}^p)$
$N_b$ is the number of utterances in the batch
$M_i$ is the number of masked frames for utterance $u_i$,
$l_{it}$ denotes the pseudo-label for the $t$-th masked frame in utterance $u_i$.
For ER downstream tasks, we reduce the temporal dimension for $f_i^p$ by mean-pooling and feed the output to a fully-connected layer to produce the label predictions.
Personalized Label Distribution Calibration (PLDC)
we further want to add a personalized post-inference technique to correct the predicted label distributions. Specifically, given the predictions for a target speaker, the main idea is to identify the most similar speakers from the train set based on the feature similarity and use their label distribution statistics (means and standard deviations) to calibrate the predicted label distributions of the target test speaker.
In particular, for speaker s in both the train and test set, we extract the features for each utterance of s and average them to form the speaker vector
$v_s = \frac{\sum\limits_{k=1}^{N_s} \bar{E}_{ft}^p(u_s^k)}{N_s}$
Where $E_{ft}^p$ denotes the ER-fine-tuned model of $E^p$ (the personalized adapted version of E), $\bar{E}_{ft}^p(u_s^k)$ denotes the mean-pooled vector representation for utterance $u_s^k$ , and $N_s$ is the number of utterances from speaker s.
Then, for each speaker in the test set, we retrieve the top-k most similar speakers in the train set based on the cosine similarity between the speaker vectors. Next, we average the label distribution statistics from the retrieved speakers to get an estimation of the mean $\bar{μ}$ and standard deviation $\bar{σ}$.
Finally, each predicted label y for the target speaker would be shifted as
$\tilde{y} = \frac{y-\mu}{\sigma} * \bar{\sigma} + \bar{\mu}$
- μ and σ are the mean and standard deviation for the predicted label distribution.
Experiments and Discussions
Implementation and Training Details
we perform adaptive pre-training for ten epochs using the Adam optimizer with a linear learning rate scheduler (5% warm-up and a maximum learning rate of 1e−5) on a single NVIDIA Quadro RTX8000 GPU.
All other settings are identical to HuBERT’s pre-training configurations.
For downstream fine-tuning experiments, we add a light interpreter on top of the HuBERT encoder to process the mean-pooled extracted representations.
Following prior work [14], the models are optimized with a CCC loss LCCC = 1 − CCC for arousal and valence estimation
All of our experiments are performed with the HuBERT-large architecture, except for the personalization gap experiments, as the model used to generate the pseudo-labels for HuBERT-base is not publicly available.
We report two evaluation metrics, namely the Overall CCC (O-CCC), which concatenates the predictions on all test speakers before computing a single CCC score for the test set, and A-CCC, which denotes the average CCC scores computed for each test speaker.
Baselines
- We compare our method to three baselines: (1) Vanilla-FT in which E is fine-tuned on Dtr. (2) B2 represents the data weighting method proposed by Sridhar et al. [14]. (3) Task-Adaptive Pre-Training (TAPT) in which encoder E is continued pre-training on D for ten epochs.
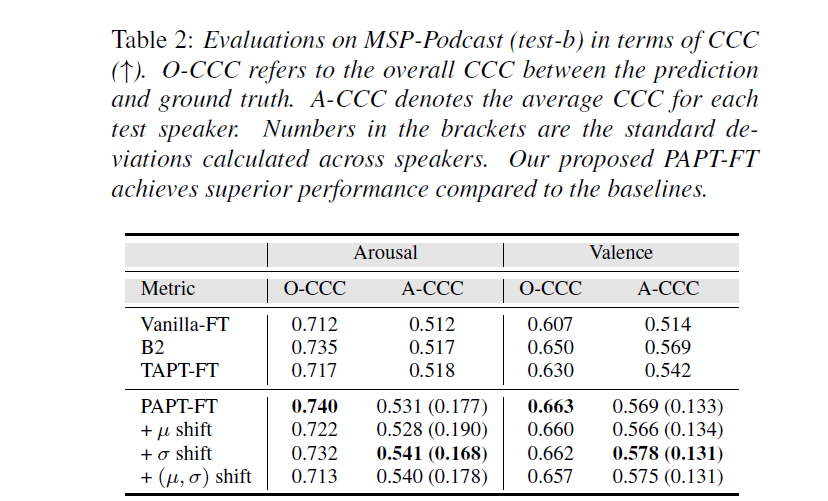
Experimental Results on test-b
Compared to the best-performing baselines, our methods achieve superior performance on both arousal and valence estimation, with a gain of 0.023 and 0.009 on arousal and valence A-CCC respectively. Notably, we achieve state-of-the-art results for the task of valence estimation, in which our Overall-CCC score achieves 0.665.
We attribute this to the high variance in the number of utterances of each speaker in the test set. Furthermore, Table 2 also demonstrates that PLDC consistently achieves the best performance when we only perform σ shifting, while μ shifting often reduces both A-CCC and O-CCC.
Ablation Study
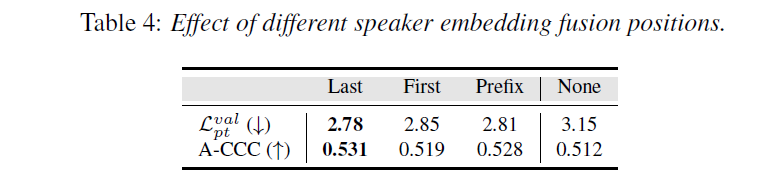
Table 4 shows the experimental results for arousal estimation on test-b of fine-tuned encoders (without PLDC) adaptively pre-trained with different fusion positions of the speaker embeddings.
In particular, Last refers to our proposed setting in which the speaker embeddings are added to the output of the Transformer encoder; First refers to speaker embeddings being added to the inputs of the first layer of the Transformer encoder, and Prefix refers to the setting in which the speaker embeddings are concatenated as prefixes to the inputs of the Transformer encoder. None refers to the vanilla HuBERT encoder.
We find that Last provides the best results.
Conclusion
In this paper, we propose two methods to adapt pre-trained speech encoders for personalized speech emotion recognition, namely PAPT, which jointly pre-trains speech encoders with speaker embeddings to produce personalized speech representations, and PLDC, which performs distribution calibration for the predicted labels based on retrieved similar speakers.
We validate the effectiveness of the proposed techniques via extensive experiments on the MSP-Podcast dataset, in which our models consistently outperform strong baselines and reach state-of-the-art performance for valence estimation.