Journal/Conference: Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) (pp. 1008-1012). IEEE.
Year(published year): 2023
Author: Yue, P., Wu, Y., Qu, L., Zheng, S., Zhao, S., & Li, T.
Subject: Few-shot Learning, Speech Emotion Recognition, Metric Learning
Few Shot Learning Guided by Emotion Distance for Cross-corpus Speech Emotion Recognition
Introduction
- Two main types of emotion classification systems have been widely used in emotion research and applications, namely discrete emotion categories and continuous emotion. Discrete emotion theories propose that there are a number of emotion categories, such as anger, fear, happiness, sadness, disgust and surprise, that are biologically based and universally recognizable by facial expressions and physiological responses [6][7][8]. Dimensional models of emotion suggest that emotions can be described along a few continuous dimensions, such as valence (positive-negative), arousal (high-low) and dominance (active-passive) [9][10][11].
- 감정 연구와 응용 분야에서 널리 사용되는 두 가지 주요 유형의 감정 분류 체계는 Discrete 감정 범주와 Dimensional 감정입니다. Discrete 감정에서는 분노, 공포, 행복, 슬픔 혐오, 놀라움과 같은 여러 가지 감정 범주가 있으며, 이는 생물학에 근거하여 얼굴 표정과 생리적 반응에 의해 보편적으로 인식될 수 있다고 제안합니다. Dimensional 감정 모델은 valence(pos-neg), arousal(high-low), dominance(active-passive)와 같은 몇가지 연속적인 차원을 따라 감정을 설명할 수 있다고 제안합니다.
- In recent years, there have been articles verifying that discrete emotion labeling and continuous emotion labeling can complement each other, and better emotion recognition performance can be achieved through multi-task learning[12][13][14][15]. The logic behind these articles is that both discrete and continuous emotion annotation information can provide a basic emotion feature extraction capability for emotion recognition models, and the information provided by the two is complementary. Especially, continuous emotion annotations can provide useful information for discrete emotion recognition.
- 지난 몇년 동안 두 감정 체계들의 라벨링이 서로 보완된다는 논문들이 발표 되었고, multi task learning에 높은 성능을 달성하였습니다. Continuous 감정 주석은 discrete 감정 인식에 유용한 정보를 제공합니다.
- Another problem with traditional cross-corpus SER methods is their weak ability in speech representation because they use traditional speech features mostly coming from openSMILE toolkit or low-level speech descriptor instead of state-of-the-art unsupervised pre-trained speech features.
- Inspired by the above series of studies on discrete versus continuous emotions, this paper quantifies the distance between emotion categories through their distribution in continuous emotion space, and uses this as prior knowledge in discrete emotion category learning.
- For instance, the Euclidean distance between the two emotions of happy and sad is the farthest, because they are relatively far apart in the two dimensions of valence and arousal. According to the distribution, one can divide the distance between pairs of emotion categories into several levels.
- The emotion distance guides the metric loss construction in fewshot learning to learn more meaningful and generalizable representations of emotions that are consistent across domains.
- The contributions of this paper are as follows: 1) This paper introduces emotion distance for the first time to the cross corpus SER task. 2) This paper adopts a self-supervised speech feature extractor instead of traditional features for cross-corpus SER. 3) The proposed few-shot learning guided by emotion distance method achieves good cross-corpus SER performance.
Method
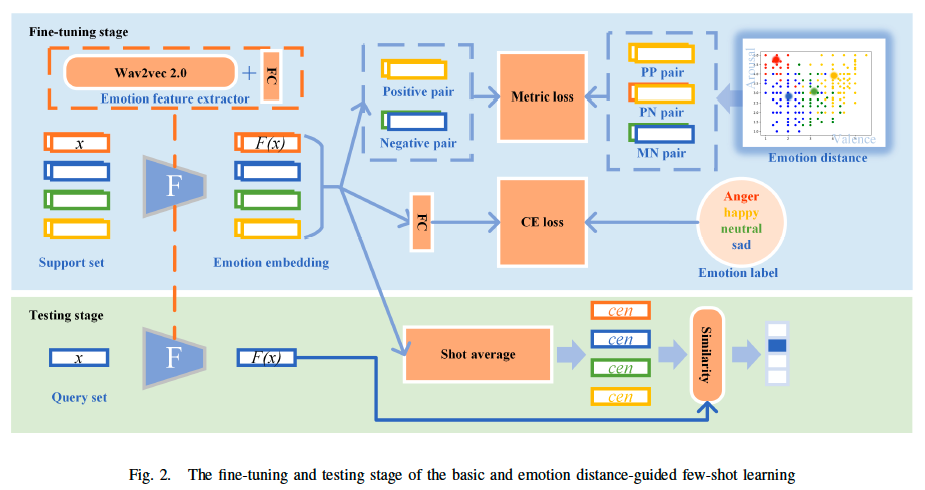
- Figure 2 shows the fine-tuning and testing stage of the baseline and emotion distance-guided few-shot learning, from which one can also see how the emotional distance knowledge is used in the construction of the metric loss.
- Some general notation assumptions of this paper are as follows. x represents a speech sample and F represents the speech emotion feature extractor. F(x) is the emotion embedding of sample x, and cen represents the shot average embedding of a certain emotion in the support set. The parameters of the SER model can be represented as W and the loss function is L(W).
A. Baseline transfer learning based on few-shot learning
The baseline method consists of three steps: 1) Training a feature extractor on a large source corpus using a self-supervised contrastive learning objective. 2) Fine-tuning a classifier on a few labeled examples from the target corpus using the extracted features. 3) Testing the SER model on the target corpus.
During the fine-tuning stage on the target corpus, the training loss of basic transfer learning (BTL) only contains the CE loss related to emotion labels, while the few-shot learning based transfer learning (FSTL) also takes into account the relationship between categories, as shown in the ‘metric loss’ in Figure 2.
The SNN is trained by creating positive and negative pairs of inputs, where positive pairs belong to the same class and negative pairs belong to different classes. The network uses a contrastive loss to minimize the distance between similar inputs and maximize the distance between dissimilar inputs:
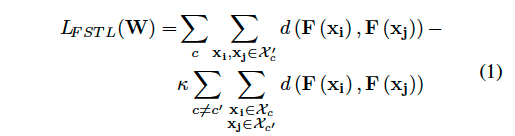
where Xc is the set of data belonging to class c,Xc′ is the set of data belonging to class c′ different than c, d is the Euclidean distance between sample pair embeddings and κ determines the trade-off between penalizing dissimilarity between samples belonging to the same class against similarity between samples belonging to different classes.
BTL은 기본적인 FSL과 CE loss를 사용하여 finetuning, FSTL은 SNN은 사용하여 Negative pair, Positive pair로 나눈 input으로 훈련됨 → contrasive loss를 사용하는데 비슷한 input은 서로 붙고, 다른 input은 멀리 떨어뜨려 놓음
B. Few-shot learning guided by emotion distance
Inspired by the distribution of emotion categories in the valence-arousal continuous emotion space, this study proposes few-shot learning based on a fine-grained emotion relationship metric.
본 연구에서는 valence-arousal 연속 감정 공간의 감정 범주 분포에서 영감을 얻어 세분화된 감정 관계 메트릭을 기반으로 한 few-shot learning 학습을 제안
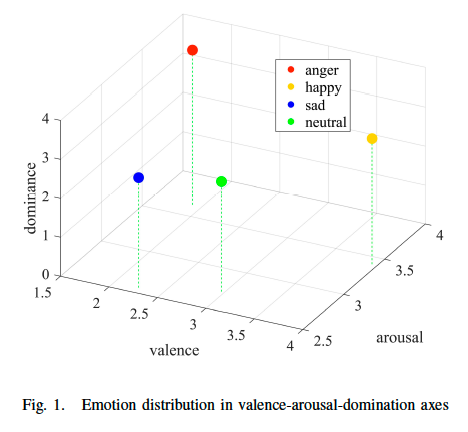
As shown in Figure 1, in the continuous emotion space, the {happy, sad} sample pair has the farthest Euclidean distance. In addition, in the learning of speech emotion representation, the representation ability of emotion representation in the arousal dimension is stronger than that of the valence dimension, so when we consider the distance between emotion categories, the distance in the valence dimension is compressed, which leads to the emotion distance between {anger, sadness} sample pair being as far as that between {happy, sad} sample pair. These two types of emotion sample pairs are considered to be pure negative (PN) pairs.
{화남, 슬픔} 그리고 {행복, 슬픔}의 두 쌍을 PN 쌍이라고 간주
For pairs of samples with the same emotion category, we believe that the distance between them should be as close as possible and they are pure positive (PP) pairs. For other emotion sample pairs, such as {happy, neutral} and {happy, angry}, we consider the distance between them to be at an intermediate level, not as far away as PN pairs, and we call them medium negative (MN) sample pairs.
동일한 감정 카테고리를 가진 샘플 쌍의 경우 그 사이 거리는 가능한한 가까워야 하며 PP 쌍으로 간주.
{행복, 중립}, {행복, 분노}와 같은 다른 감정 샘플 쌍의 경우 PN 쌍만큼 거리가 멀지 않다고 간주하여 이를 MN 이라고 간주.
Following the above discussion of emotion distance, we construct a fine-grained metric loss function for few-shot learning guided by emotion distance (EMOFSL):
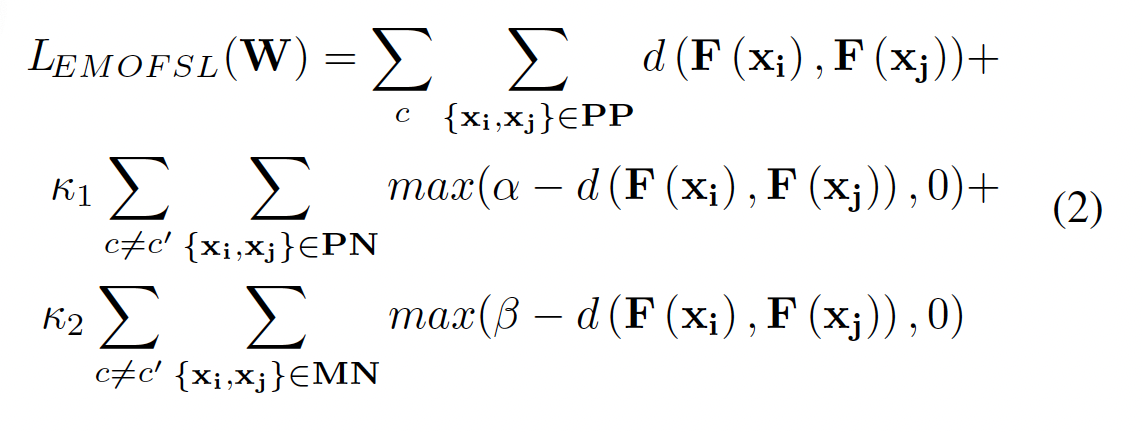
where α > β and represent the restricted distance margin of the PN pairs and the MN pairs, respectively, and κ1 and κ2 determine the trade-off among different parts of the loss.
여기서 α는 β보다 크며, PN과 MN의 제한된 거리 마진을 나타냄. 그리고 κ1과 κ2는 손실의 다른 부분의 트레이드 오프를 결정.
- 제한된 거리 마진: 제공한 문장의 맥락에서 PN 쌍과 MN 쌍에 대한 ‘제한된 거리 여백’은 서로 다른 감정 카테고리의 임베딩 간에 허용되는 거리 또는 간격을 나타냅니다. 특정 여백(PN 쌍의 경우 α, MN 쌍의 경우 β)을 설정함으로써 모델은 서로 다른 감정 카테고리의 임베딩이 특징 공간에서 얼마나 멀리 떨어져 있어야 하는지에 대한 제약을 적용합니다.
- α와 β: α와 β는 다양한 유형의 감정 샘플 쌍에 대한 제한된 거리 마진을 정의하는 데 사용되는 매개변수입니다. 구체적으로 α는 순수 음수(PN) 쌍의 제한된 거리 마진을 나타내고 β는 중간 음수(MN) 쌍의 제한된 거리 마진을 나타냅니다. α > β 조건은 PN 쌍의 마진이 MN 쌍의 마진보다 크다는 것을 나타냅니다.
- κ1 및 κ2: κ1과 κ2는 손실 함수의 여러 부분 간의 트레이드오프 또는 균형을 결정하는 계수입니다. 이 계수는 학습 과정에서 손실 함수의 여러 구성 요소의 중요도 또는 영향을 제어합니다. κ1과 κ2를 조정함으로써 모델은 원하는 학습 목표에 따라 손실 함수의 특정 측면을 다른 측면보다 우선순위를 정할 수 있습니다.
- 손실의 다른 부분 간의 트레이드 오프: 이 문장은 κ1과 κ2가 훈련 중에 손실 함수의 가중치와 균형을 결정하는 데 중요한 역할을 한다는 점을 강조합니다. κ1과 κ2를 적절하게 설정하면 모델은 전체 손실에 대한 다양한 구성 요소(예: PN 및 MN 쌍의 거리 마진)의 기여도를 효과적으로 관리하여 학습 과정과 감정 범주 간의 관계를 포착하는 모델의 능력에 영향을 줄 수 있습니다.
EXPERIMENTAL RESULTS AND DISCUSSIONS
A. Experimental setup
- In this section, we evaluate the proposed framework for cross-corpus SER. Three most common emotion corpora
containing English speech, including IEMOCAP (I) [21], RAVDESS (R) [22], and MSP-IMPROV (M) [23], are employed in our experiments. Two of the above corpora are randomly selected as the source and target corpora respectively, and six groups of cross-corpus SER tasks (source corpus-target corpus) I-R, I-M, R-M, R-I, M-I, M-R, are conducted. We select four common emotional categories, i.e., anger, neutral, happy, and sad, in our experiments. - 전이 학습 과정에서는 실험 결과의 신뢰성을 확인하기위해 각 타겟 코퍼스 마다 다른 설정으로 교차검증(CV)을 실시했습니다. IEMOCAP의 경우, 한 세션을 사용하는 방식으로 데이터셋을 분할했습니다. RAVDESS의 경우 화자의 id에 따라 데이터셋을 6개의 동일한 하위집합으로 분할한 후 하나의 집합을 테스트 집합으로, 나머지를 학습데이터로 선택했습니다. MSP의 경우 6 fold leave-one-speaker-out CV를 수행했습니다(각 폴드 내에서 ‘한 명의 화자만 남겨두기’ 전략이 사용되었습니다. 즉, 각 폴드마다 한 화자의 데이터는 테스트 세트로 남겨두고 나머지 화자의 데이터는 모델 학습에 사용했습니다.)
- For few-shot learning based transfer learning, 5 random fixed samples of each emotion in the training set of the target corpus are selected for fine-tuning, and all of the samples in the testing set are used for testing. The training set and the testing set are obtained from the cross-validation settings.
- We compared the proposed EMOFSL with basic transfer learning(BTL) and few shot learning based transfer learning(FSTL) in terms of unweighted accuracy assessing the SER performance.
B. Results and discussions
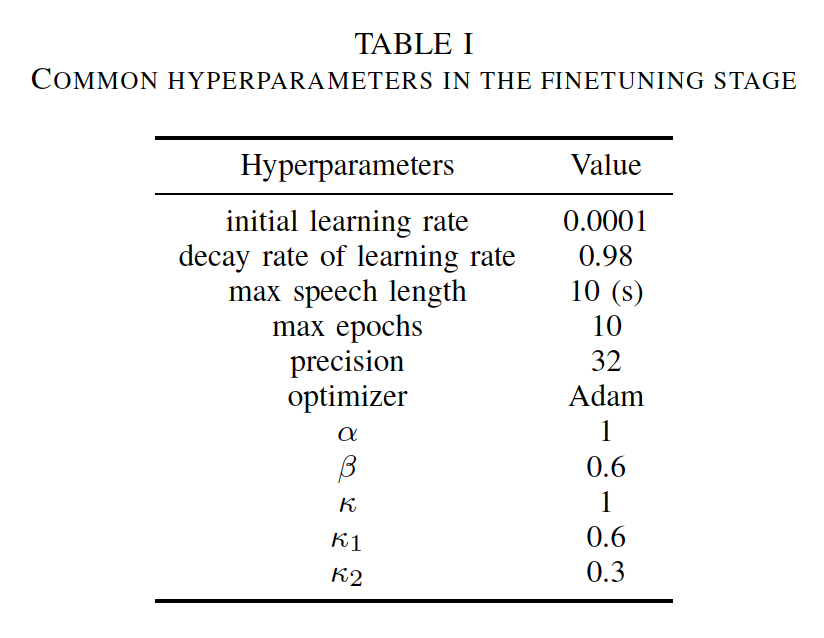
- Table II shows the cross-corpus SER performance of the compared methods, in which 5 samples from each of the 4 emotions are selected to form the support set in the fine-tuning process. Few-shot learning method guided by emotion distance (EMOFSL) is compared with basic transfer learning (BTL) and few-shot learning based transfer learning (FSTL) in terms of unweighted accuracy rate (UAR).
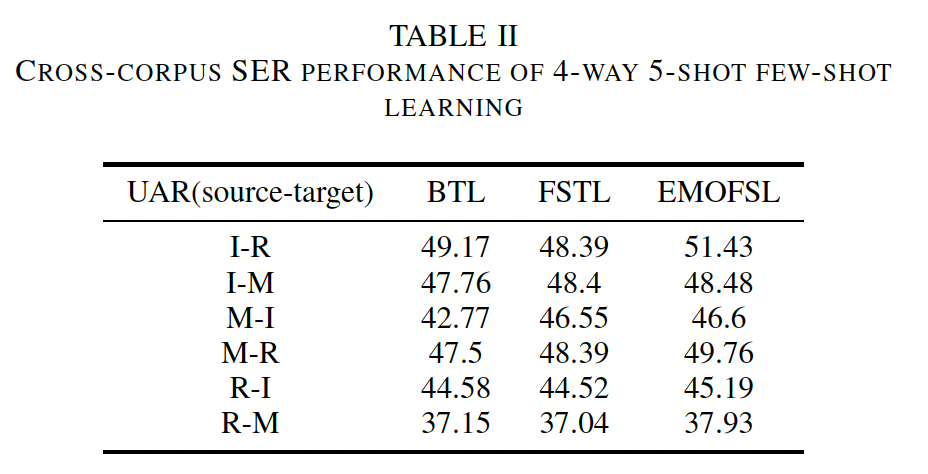
- It can be observed that our proposed EMOFSL performs better than the other two baseline methods, which proves the effectiveness of emotion category distance prior knowledge for cross-corpus SER task. It can be also observed that in most cross-corpus tasks, the few-shot learning-based transfer learning performs better than the basic transfer learning, which verifies that metric loss obtained from the positive and negative sample pairs helps the learning of speech emotion on the target corpus.
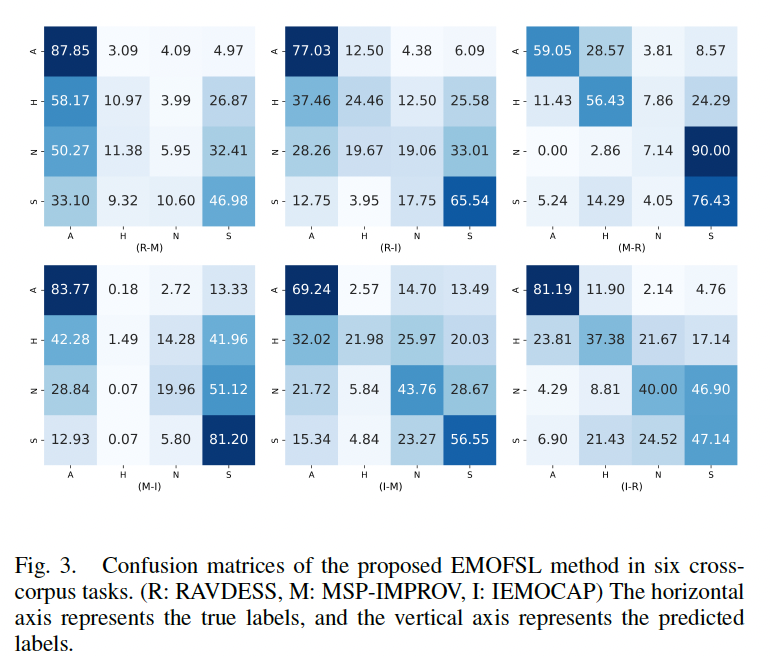
- Figure 3 presents the confusion matrices of the proposed EMOFSL method for six cross-corpus tasks. One can observe that the recognition results of anger and sad in all tasks are generally better than other emotions, indicating that these two emotions in speech are easier to be recognized, which is partly related to the prior knowledge of the emotional distance we added to the metric loss.
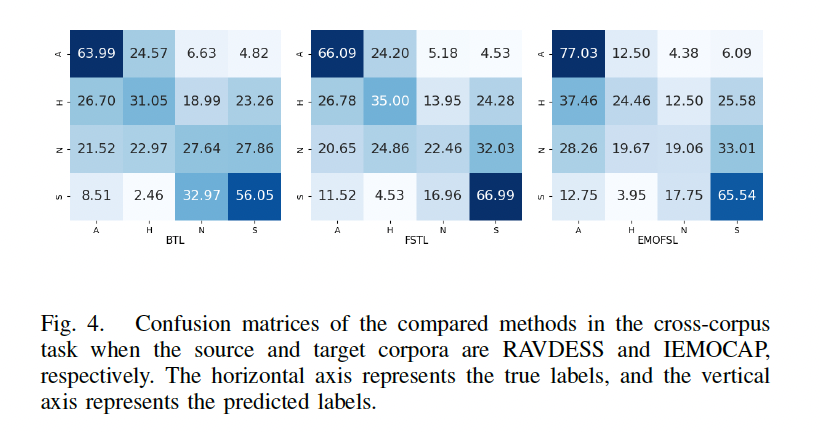
- Figure 4 shows the confusion matrix comparison between the proposed method and the baseline methods. We can see that with metric loss representing the distance relationship of different emotion categories, FSTL and EMOFSL achieve better recognition on anger and sad.
- Figure 3 and 4 also indicate that happy is often misidentified as anger and neutral is often misidentified as sad, which is consistent with our previous understanding in the continuous emotion space that arousal is easier to distinguish than valence in speech emotion expression.
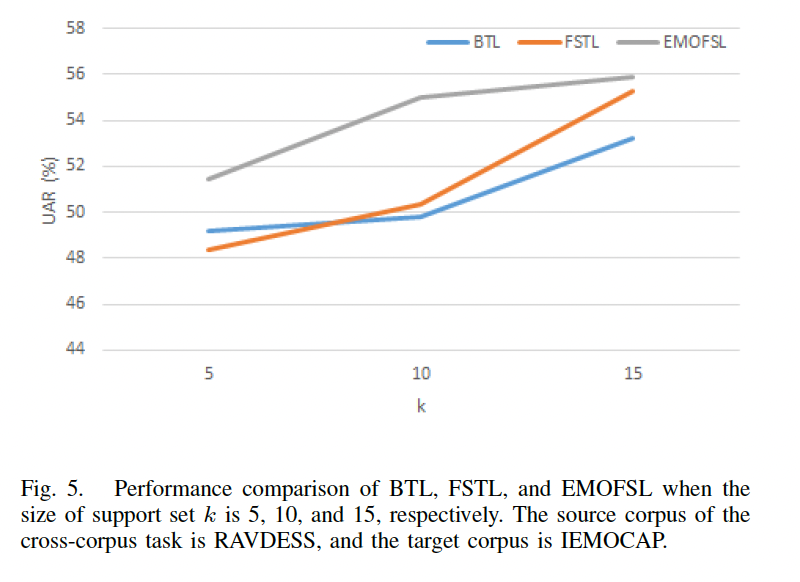
- Figure 5 shows the performance comparison of BTL, FSTL, and EMOFSL when the size of support set k is 5, 10,
and 15, respectively. The source corpus of the cross-corpus task is RAVDESS, and the target corpus is IEMOCAP. One can observe that: 1) As the number of training samples in the support set increases, the SER performance of the three methods improves accordingly. 2) In the case of different support set sizes, the performance of EMOFSL is better than the other comparison methods. 3) The performance of FSTL is better than that of BTL in most cases.
CONCLUSION
- Cross-corpus speech emotion recognition faces the problem of sparse target set data. To solve this problem, this study introduces the prior knowledge of emotion distance to guide the few-shot learning process of cross-corpus emotion recognition, thereby alleviating the problem of insufficient emotional information to a certain extent. Experimental results show that the proposed method performs better than traditional few-shot learning verifying the efficiency of the emotion distance prior knowledge. In addition, this paper introduces a self-supervised pre-training model with stronger speech representation ability than traditional features as a feature extractor, which also improves the performance of cross-corpus speech emotion recognition.