Meta Learning
“Learn to Learn”: 새로운 테스크를 더 빨리 학습 하기 위해 이전의 학습 경험을 적극적으로 활용한다.
핵심아이디어: 학습 에이전트가 단순히 데이터를 학습하는 것이 아니라, 자신의 학습 능력을 스스로 향상 시킨다 → 이 학습 방법은 일종의 inductive bias라고 볼 수 있음.
학습하는 방법을 학습한다는 것
딥러닝에서는 파라미터 초기화 시, 무작위로 초기화함
→ 이 새로운 테스크를 빠르게 학습하는 “좋은 초기화”를 학습할 수 없나?
ex) MAML(Model-Agnostic Meta Learning) Algorithm
⇒ 좋은 초기화라는 학습 방법을 학습
$\therefore$ 새로운 태스크에 대한 빠른 학습 가능
ie, MAML로 학습한 메타 러닝 모델은 새로운 태스크가 주어졌을 때 이를 빠르게 학습할수 있는 ‘좋은 초기화’에서 시작하여 소량의 데이터와 작은 경사하강법만으로 빠른 학습이 가능
Multi Task Learning과 차이점
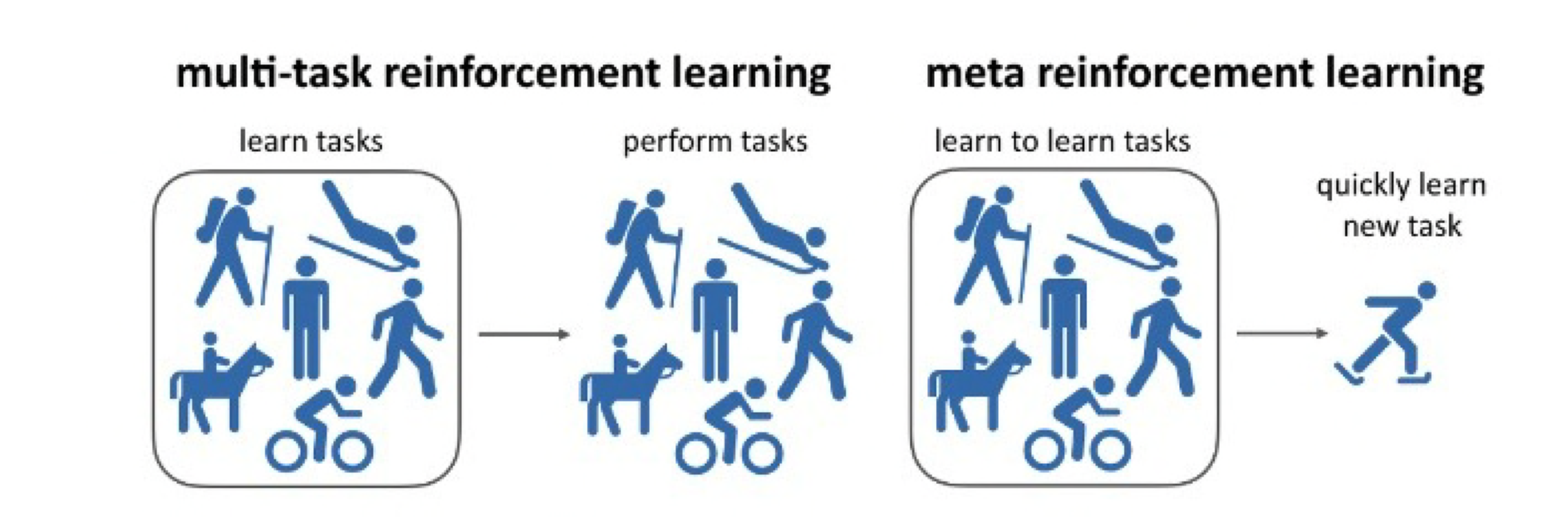
- Multi task learning: 하나의 모델이 여러가지 task 학습 ⇒ 학습한 task 들과 같은 여러 task 수행
- Meta learning: 여러 task 학습 그러나 학습하는 걸 학습 ⇒ 새로운 task가 주어졌을 때 빠르게 학습
Few shot Learning
Few shot learning을 잘 하기 위해 나올 방법론이 Meta Learning
n개의 훈련 data를 보여주는 것을 few shot, 1개의 훈련 data를 보여주는 것이 1 shot
n way k shot: n(클래스의 개수), k(클래스별 data 개수)

- 2 class 3 shot → 2 way 3 shot
- 논문에서는 5 way 1 shot, 20 way 5shot이 성능 평가 방법으로 많이 사용됨
Meta learning, Few shot learning의 대표적인 접근 방법
- Metric Based Learning(거리 학습 기반): 효율적인 거리 측정 학습이 핵심
- support set, query set 간의 유사도 측정 방법(유클리디안으로 거리 측정)
- 대표적인 알고리즘: Siamese Network, Prototypical Network, Relation Network
- 모델은 주어진 서포트 데이터를 feature space에 나타내어 측정을 뽑아냄
- 같은 클래스면 가깝게, 멀면 멀게 분리
- Model Based Learning(모델 학습 기반): 메모리를 이용한 순환 신경망이 핵심
- 적은 수의 학습단계로도 파라미터를 효율적으로 학습할 수 있는지
- 모델에 별도 memory를 두어 학습속도를 조절
- MANN(Memory Augmented NN) → 외부 메모리 공유
- Optimizer Learning(최적화 학습 방식): 모델 파라미터 최적화가 핵심
MAML: 기술역전파 → 큰 scale의 data를 위한 설계
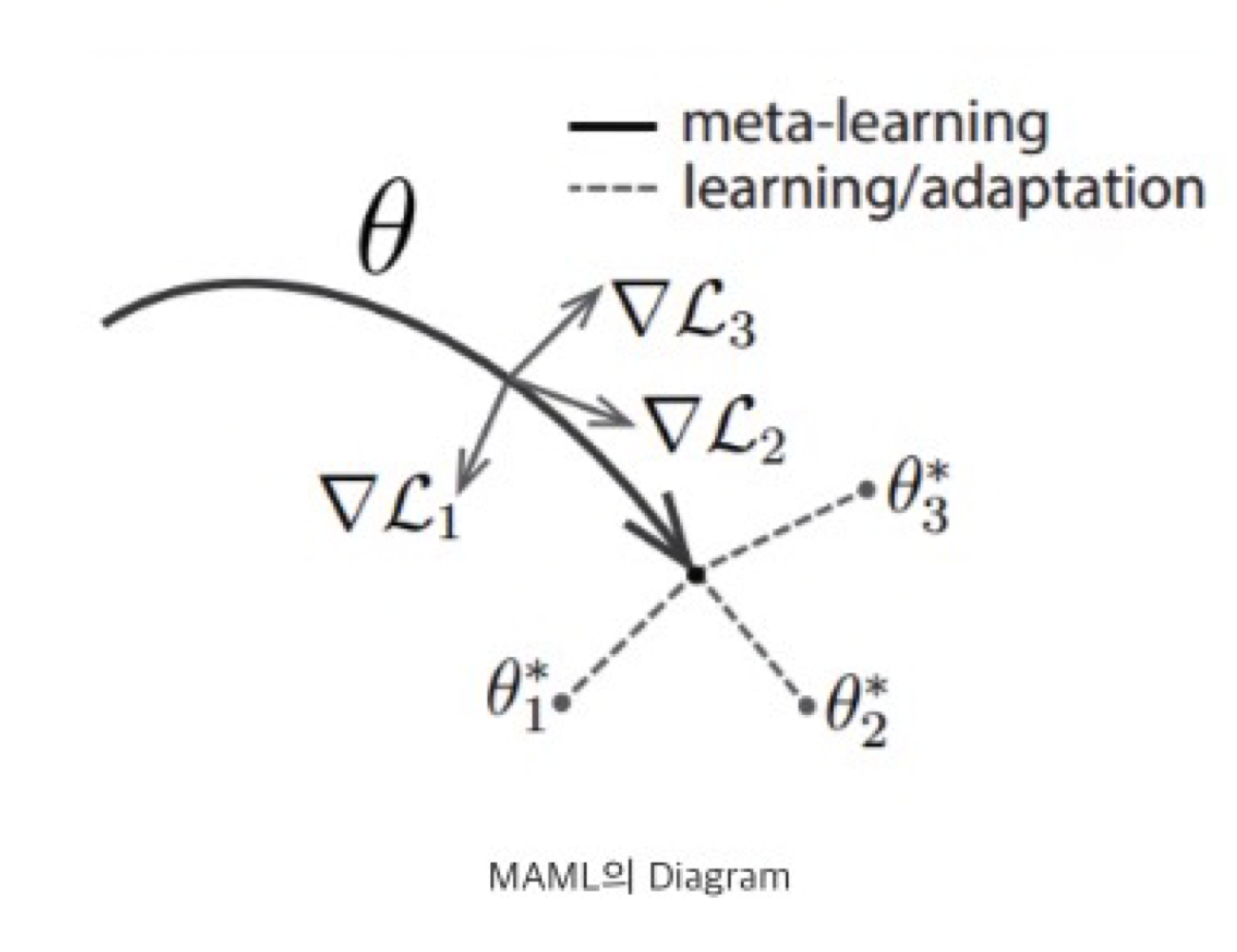
- 실선
- 각 Task의 그래디언트를 합산하여 모델을 업데이트
- 1,2,3의 데이터에서 학습된 그래디언트 정보로 전반적인 파라미터를 업데이트함
- 점선
- 공통 파라미터로부터 다시 모델이 학습하면서 세부 파라미터 업데이트
⇒ 이 과정을 최적의 파라미터를 찾을때까지 반복하면 모델 최적의 파라미터를 찾을 수 있음
⇒ 최적의 초기 파라미터 값을 설정하는 걸 배우는 방법
- 실선
Reptile, Meta-SGD
- Metric Based Learning(거리 학습 기반): 효율적인 거리 측정 학습이 핵심
Self Supervised Learning과의 차이점
SSL
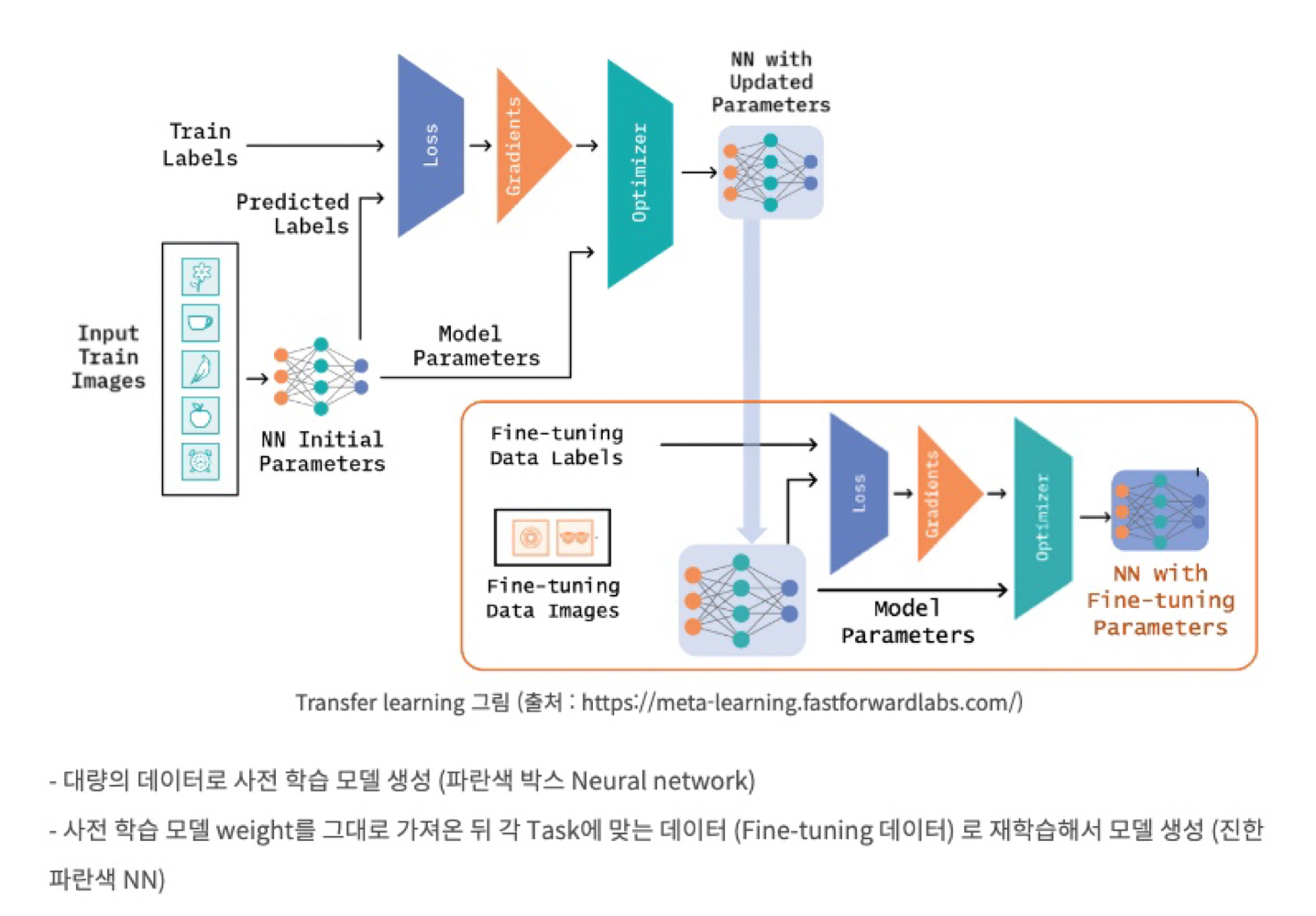
- Transfer learning의 한 종류
- pre trained 모델을 중심으로 학습, 소량의 데이터로 재학습
- transfer learning에서 multi task learning을 할때 pretrained 모델을 불러온 뒤에 각각의 task에 맞게 fine tuning 함.
- transfer learning
Meta Learning
여러개의 task를 동시에 학습 & 각 task 간의 차이로 학습(Meta parameter)
전체 학습 이후 소량의 데이터(few-shot)으로도 추론할 수 있는 범용적인 모델 생성
meta learning
Episode Training
모든 class를 활용하지 않음
기존 방식
A B C D E Train 80 80 80 80 80 Test 20 20 20 20 20 Episode 방식
- Task 1: A,B 클래스 분류기
- Task 2: C, D 클래스 분류기
- Task 3: D, E 클래스 분류기
⇒ 이러고 나서 완전히 새로운 데이터로 분류 성능 확인
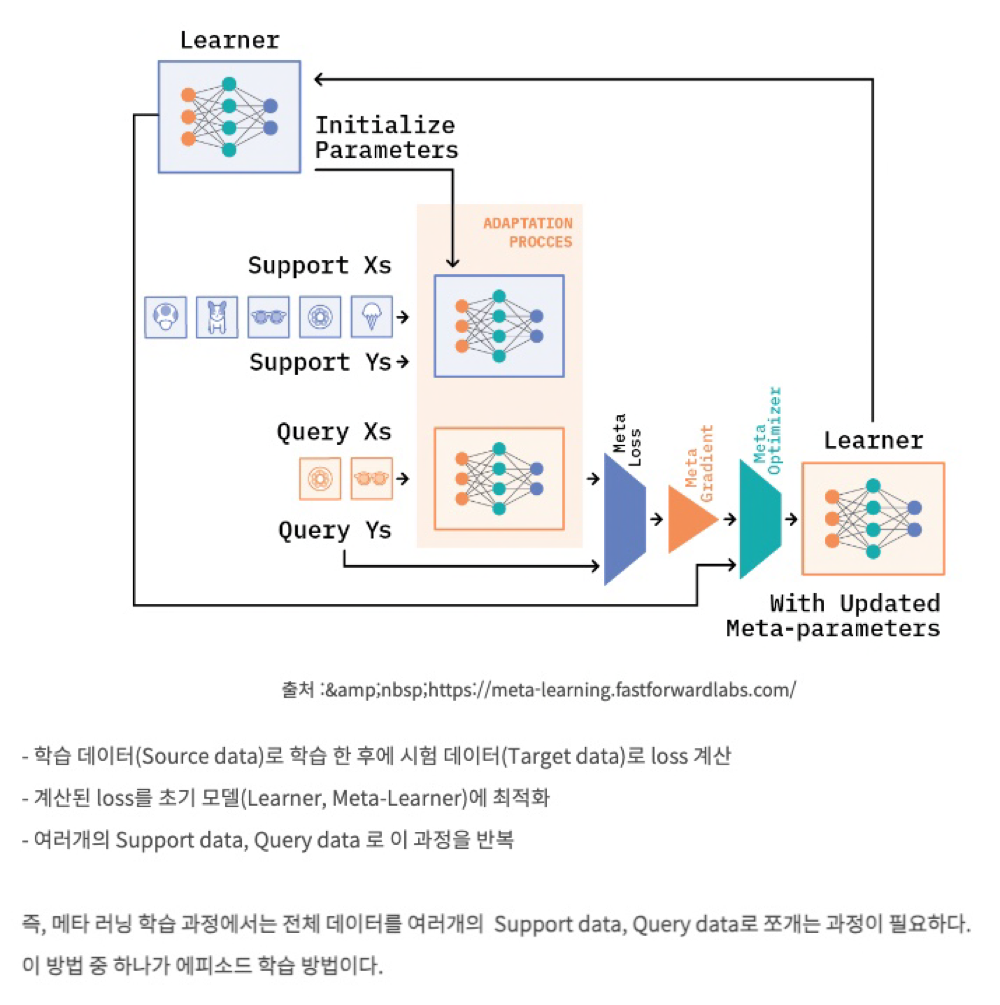
학습 방법
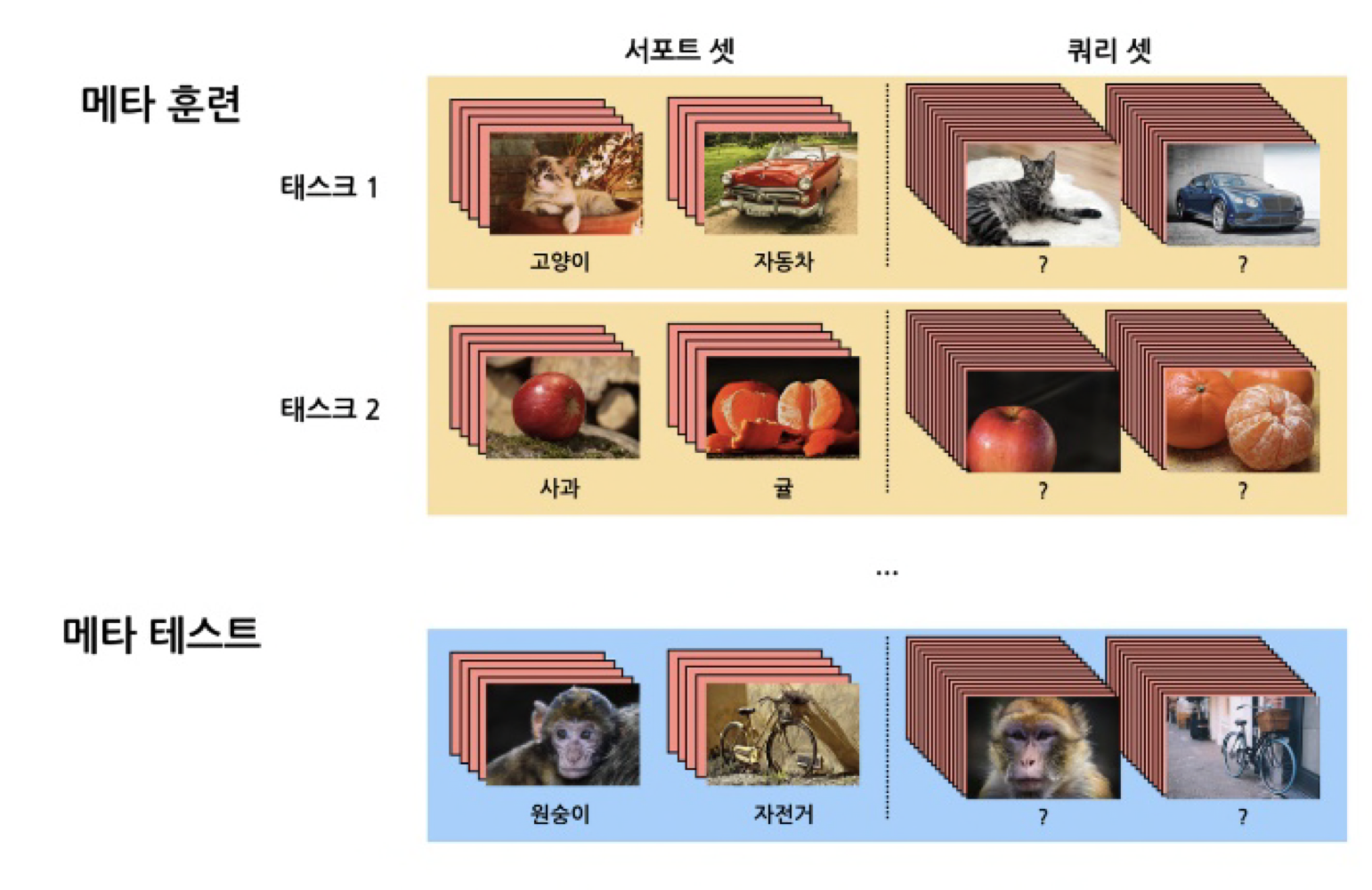
- train - test data split: 전체 학습 데이터를 meta-train, meta-test(meta-train에 등장하지 않은 완전히 새로운 class) 나눔
- task sampling: meta tarin 데이터 셋을 각 task data로 쪼갬. 전체 class 중 일부 class 데이터가 task1(episode)에 sampling
- support-query dataset split: 각 task 별 데이터들을 다시 suppor set(training set), query set(test set)으로 샘플링 (기존의 DL 방식과 마찬가지로 이 둘의 data는 겹치지 않음)
- Task Training: 각각의 task로 학습을 진행하며 모델을 생성함
- meta test evaluation: 생성 모델에 meta test의 support set으로 새로운 이미지 class를 학습 시키고 최종적으로 meta test query 셋을 분류해내는 것이 목적
- Goal: 학습에 활용되지 않는 클래스의 데이터(meta-test)에서도 일부 meta test support data로 훈련한 뒤 meat test query 데이터를 구분할수 있는가 ⇒ 여기서 다양한 학습 방법이 고안됨. 크게 3가지 학습 기법으루 분류됨