Journal/Conference : Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)
Year(published year): 2019
Author: Yuxuan Xi, Pengcheng Li, Yan Song, Yiheng Jiang, Lirong Dai
Subject: Domain Adaptation, Speech Emotion Recognition
Speaker to Emotion: Domain Adaptation for Speech Emotion Recognition with Residual Adapters
Summary
- The paper proposes a new method for domain adaptation in speech emotion recognition using residual adapters.
- The proposed method transfers information from a speaker corpus to an emotion corpus, resulting in significant improvements in SER performance.
- The paper demonstrates the effectiveness of the proposed method through experiments and shows that domain-agnostic parameters learned by VoxCeleb2 are necessary for effective domain adaptation in SER.
Introduction
Recently, deep learning based systems have achieved significant progress for SER, but to be successful, sufficient labeled data is needed, particularly due to the complexity of emotional information. However, existing corpora, such as IEMOCAP [15], CHEAVD [14], FAU-AIBO [29], and EMODB [30], are generally size-limited, in part due to annotation cost, and also suffer label ambiguity.
One possible solution is to utilize emotion information from multiple corpora. Based on this approach, several transfer learning and multi-task learning (MTL) based methods have been proposed [1], [2], [3], [4].
Transfer learning focuses on adapting knowledge from available auxiliary resources to the target domain.
However, due to the limited size of emotion corpora, SER performance is far from satisfactory and it is still difficult to apply successful deep learning architectures like ResNet and DenseNet to further improve performance.
Based on this view, we propose a domain adaptive model which can utilize a common representation between emotion and speaker identity to further improve SER accuracy, using ResNet as a backbone architecture.
Specifically, the proposed method aims to tackle the lack of labeled corpus by employing a residual adapter model [12] to transfer the information from VoxCeleb to a specific SER target dataset. The residual adapter resembles ResNet [10], with the major difference that all convolutional layers are replaced by adapter modules.
In this paper, the residual adapter model is trained using VoxCeleb2 data with speaker labels, then emotion corpora are used to train the domain-specific parameters, and different fully-connected layers are used to predict the classification score, as shown in Fig.1.
The main difference lies in that the proposed residual adapter utilizes supervised learning to exploit the relationship between speaker and emotion data. To prove the effectiveness of our method, we first use ResNet that is trained with emotion data only as a baseline system, and then conduct a series of experiments as shown in Fig.1, including: (1) A ResNet trained by VoxCeleb2 data as the feature extractor, then the classifier trained for SER. (2) The same ResNet fine-tuned with emotion data – the common practice in transfer learning. (3) The proposed residual adapter method, furthermore testing the adapter module alone, aiming to demonstrate that features learned from the speaker classification task can be beneficial to SER.
Overview of Speaker-To-Emotion Domain Adaptation Framework
SER encompasses some existing problems. (1) Deep learning based methods have become prevalent in recent years [20], [21], [22], owing to the powerful representation learning ability of neural networks. In general, increasing network depth benefits performance, but the limited scale of emotion corpora greatly restricts the network complexity in practice.
(2) Existing methods mainly focus on cross-corpus learning among emotion corpora, but due to the difficulty and cost of labeling emotion data, cross-corpus methods still have limitations.
Speaker-labeled corpora are potential choices, as described in Section I, where speaker characteristics such as age and gender can influence SER results.
This fact indicates that there is some shared representation between speaker characteristics and emotion.
On the other hand, the scale of speaker corpora are much larger than those for emotion, a fact that aids in training a deep neural network. Based on those motivations, the VoxCeleb2 [13] corpus is selected in this paper for initial model training.
In order to utilize speaker labels, a complex network is first trained by speaker corpora, and then adapted to the target emotion corpora.
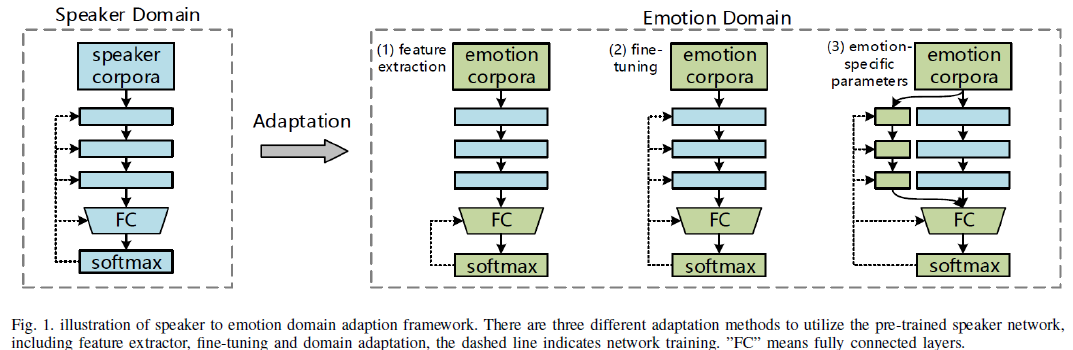
The first method is a feature extractor, which constructs an emotion classifier by retraining the topmost FC layer. The second method is finetuning, which takes the same structure as the feature extractor, then all network parameters as well as the FC classifier, are fine-tuned using the emotion corpora. Although these two
methods can exploit the information from both speaker and emotion data, they have some obvious problems.
Firstly, the network parameters are pre-trained for speaker verification, which may be quite different from SER, therefore directly utilizing the model may not be a appropriate choice. Secondly, due to the limited scale of the target emotion corpora, training the whole network may be difficult and may cause an overfitting
problem. On the other hand, the fine-tuning stage may result in forgetting the source corpora, reducing the benefit of the auxiliary information.
첫 번째 방법은 특징 추출기입니다. 이 방법은 화자 코퍼스 대해 훈련된 사전 훈련된 복잡한 네트워크를 가져와 최상위 완전 연결(FC) 계층만 재훈련하여 감정 분류기를 구성하는 것입니다. FC 레이어는 추출된 특징을 출력 클래스에 매핑하는 네트워크의 마지막 레이어입니다. 이 레이어만 재학습하면 화자 코퍼스의 정보를 그대로 활용하면서 네트워크를 목표 감정 코퍼스에 맞게 조정할 수 있습니다.
이 방법은 특징 추출기와 동일한 복잡한 네트워크 구조를 취하고 감정 코퍼스를 사용하여 FC 분류기를 포함한 모든 네트워크 파라미터를 미세 조정하는 것입니다. 미세 조정을 통해 네트워크가 특징 추출기 방식보다 더 광범위하게 대상 감정 코퍼스에 적응할 수 있지만, 대상 감정 코퍼스의 제한된 규모에 과적합하고 화자 코퍼스의 정보를 잊어버릴 위험이 있습니다.
To address these issues, this paper attempts to establish the third method, a new domain adaptation. In this method, the deep learning model is first trained using VoxCeleb2 data with speaker labels as usual. But during the adaptation stage, some extra emotion-specific parameters are added to the original model, then the emotion corpora are utilized to only fine-tune the additional parameters which coexist alongside the previously trained parameters. Through the proposed framework, the information forgetting problem is avoided, and because the emotion corpora is only utilized to fine-tune a part of the network, the over-fitting problem may be mitigated.
이러한 문제를 해결하기 위해 본 논문에서는 세 번째 방법인 새로운 도메인 적응 방식을 시도 합니다. 이 방법에서는 먼저 평소와 같이 화자 레이블이 있는 VoxCeleb2 데이터를 사용하여 딥러닝 모델을 훈련합니다. 그러나 적응단계 에서는 원래 모델에 몇 가지 추가 감정 관련 파라미터를 더한다음, 감정 코퍼스를 활용하여 이전에 학습된 파라미터를 함께 공존하는 추가 파라미터만 미세조정 합니다. 제안된 프레임워크를 통해 정보 망각 문제를 피할 수 있으며 감정 코퍼스 네트워크의 일부분만 미세조정 하는데 활용하기 때문에 과적합 문제를 완화할 수 있습니다.
Residual Adapter Model
Model Design
The basic idea of constructing an adapter module is to linearly parameterize the convolutional filter group, which is the same as introducing an intermediate convolutional layer.
기본 아이디어는 컨볼루션 필터 그룹을 선형적으로 파라미터화하는 것으로 이는 중간 컨볼루션 계층을 도입하는 것과 같습니다.
For the training progress, firstly the model is trained on the initial task, using a large corpus. Next, the parameters are fixed and other domain adapters are trained using the target domain corpus.
이 문장은 잔여 어댑터를 사용한 도메인 적응을 위한 훈련 과정을 의미합니다. 첫 번째 단계는 초기 작업(이 경우 화자 검증)을 위해 대규모 코퍼스에서 딥러닝 모델을 훈련하는 것입니다. 모델이 학습되면 파라미터가 고정되고 목표 도메인 말뭉치(이 경우 감정 코퍼스)를 사용하여 추가 도메인 어댑터를 학습합니다. 도메인 어댑터를 원래 모델에 추가하고 대상 도메인 코퍼스를 사용하여 미세 조정하여 모델을 새 도메인에 맞게 조정합니다. 제안한 방법은 원래 모델의 파라미터를 고정하고 추가 도메인 어댑터만 미세 조정함으로써 전체 네트워크를 미세 조정할 때 발생할 수 있는 과적합 및 정보 망각 문제를 방지하는 것을 목표로 합니다.
Adapter module and network structure
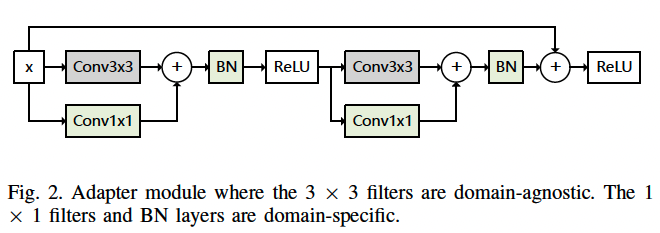
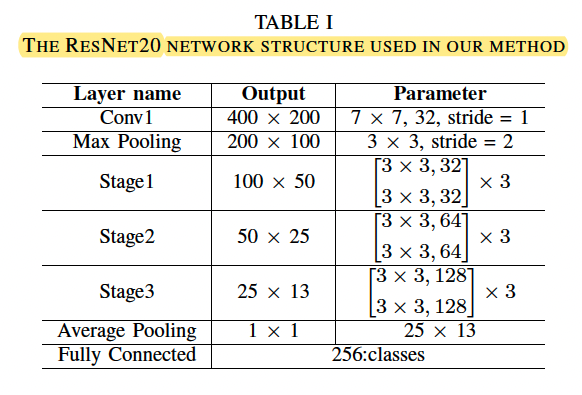
The residual adapter model is constructed on the ResNet20 model with a network structure outlined in Table I.
EXPERIMENTS AND ANALYSIS
Data description and pre-processing
In this study, both speaker data and emotion data are utilized. For speaker-labeled data, we choose the VoxCeleb2 corpus [13]. VoxCeleb2 is a large-scale speaker-labeled database, prevalent for SV tasks, that was collected from more than 6000 celebrities on YouTube. VoxCeleb2 consists of 2442 hours, with more than a million speech utterances, covering different ages, genders, accents and scenes.
For the emotion part, we select Interactive Emotional Dyadic Motion Capture (IEMOCAP) [15] and Chinese Natural Audio-Visual Emotion Database (CHEAVD) [14] 2.0 databases. IEMOCAP has scripted and improvised parts, depending on the recording scenarios. We choose the improvised data part in order to exclude undesired contextual information. Labels of neutral, angry, happy and sad are used.
CHEAVD 2.0 is a Chinese emotion corpus, the official data of the Multimodal Emotion Recognition Challenge (MEC) 2017. CHEAVD contains data selected from Chinese movies, soap operas and TV shows. It contains 8 emotion labels (angry, happy, sad, worried, anxious, surprise, disgust, neutral).
The corpus is divided into training, validation and testing sets. We use the training/validation split for performance evaluation, the hyper-parameter tuning is based on validation set, keeping the evaluation that same as in [25].
Magnitude spectrograms are utilized as input features, with the spectrograms extracted over 40 ms Hamming windows with a 10 ms window shift and 1600 FFT points. Then 0-4000 Hz spectrogram are utilized since human vocal expression is mainly located in this frequency range. The speech utterances are cut into 2 s portions with 1 s overlap, and zero-padding applied for utterances shorter than 2 s. Thus the input spectrograms have a size of 400 200. For each spectrogram, we then apply a $\mu$-law expansion, as used and described in our previous paper [18].
윈도우 시프트가 10밀리초인 40밀리초 해밍 윈도우와 1600개의 FFT 포인트로 추출한 스펙트로그램을 입력 피쳐로 활용합니다. 그런 다음 사람의 음성 표현이 주로 이 주파수 범위에 위치하기 때문에 0-4000Hz 스펙트로그램을 활용합니다. 음성 발화는 1초가 겹치는 2초 부분으로 잘리고, 2초보다 짧은 발화에 대해서는 제로 패딩을 적용하여 입력 스펙트로그램의 크기는 400×200입니다. 그런 다음 각 스펙트로그램에 대해 이전 논문 [18]에서 사용 및 설명한 대로 μ 법칙 확장을 적용합니다.
진폭 스펙트로그램은 시간에 따라 변화하는 신호 주파수의 진폭을 시각적으로 표현한 것입니다. 이는 시간에 따른 신호의 주파수 내용을 분석하는 방법인 신호의 단시간 푸리에 변환(STFT)의 크기를 구하여 얻을 수 있습니다. STFT는 신호를 짧게 겹치는 윈도우로 나누고 각 윈도우에 윈도우 함수를 적용한 다음 각 윈도우의 푸리에 변환을 취하여 계산합니다. 그런 다음 결과 복소수 값의 STFT 계수의 크기를 취하여 크기 스펙트로그램을 얻습니다. 크기 스펙트로그램은 시간 경과에 따른 신호의 주파수 내용을 간결하고 유익하게 표현하기 때문에 음성 처리 및 기타 신호 처리 애플리케이션에서 일반적으로 사용되는 특징 표현입니다.
For VoxCeleb2 data, we randomly choose 50 speakers to train the ResNet20 with adapters. For IEMOCAP improvised data, we conduct a 5-fold cross-validation, where 4 sections are used to train the network and the remaining 2 speakers are used as validation and test data.
Experiment setup
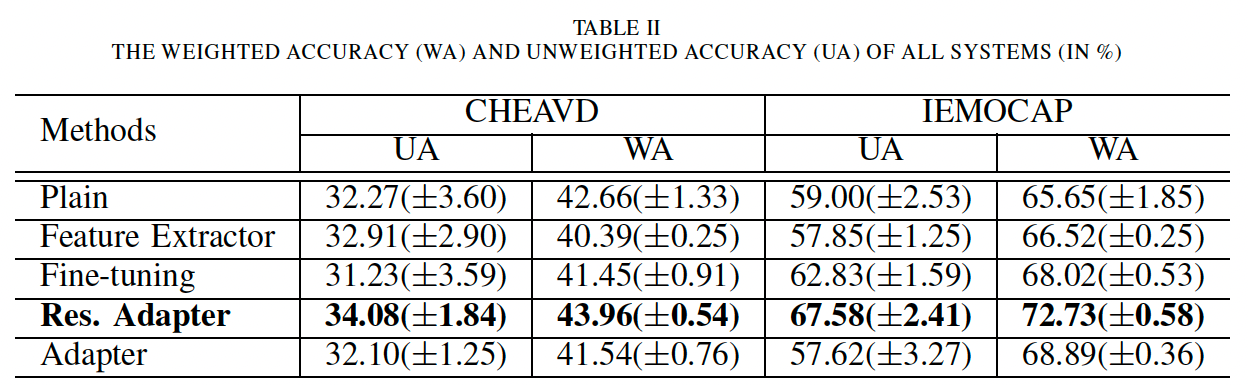
Baseline: We use IEMOCAP and CHEAVD to train a plain ResNet20 with results in the top row of Table II. Obviously, emotion data is insufficient to train a ResNet, so UA, WA are unsatisfactory for IEMOCAP and CHEAVD, in line with our expectations.
Fine-tuning: We use VoxCeleb2 data to pre-train a plain ResNet20 then, after training, the FC layer of the network is replaced and the whole network fine-tuned by the target emotion corpus. The result is not significantly better than baseline, likely to be because the number of parameters is too large for the smaller extent of emotion data to train. On the other hand, forgetting the learned speaker information may be another problem which would reduce the accuracy.
VoxCeleb2 데이터를 사용하여 일반 ResNet20을 사전 훈련한 다음, 훈련 후 네트워크의 FC 계층을 교체하고 전체 네트워크를 목표 감정 코퍼스로 미세 조정합니다. 결과는 기준선보다 크게 나아지지 않는데, 이는 훈련할 감정 데이터의 범위가 작아 매개변수 수가 너무 많기 때문일 가능성이 높습니다. 반면에 학습된 화자 정보를 잊어버리는 것도 정확도를 떨어뜨리는 또 다른 문제일 수 있습니다.
Feature extractor: When fixing the parameters learned by the primary domain, the network becomes a feature extractor. In this experiment we fix all ResNet20 parameters and train the FC layer with emotion corpora. The performance is worse than the fine-tuning method, this indicates utilizing only speaker information is not appropriate for SER.
기본 도메인에서 학습한 파라미터를 수정하면 네트워크는 특징 추출기가 됩니다. 이 실험에서는 모든 ResNet20 파라미터를 수정하고 감정 말뭉치로 FC 레이어를 훈련합니다. 미세 조정 방식보다 성능이 떨어지는데, 이는 화자 정보만 활용하는 것이 SER에 적합하지 않다는 것을 나타냅니다.
Residual Adapter: We next evaluate the residual adapter model. We use VoxCeleb2 data to train the same ResNet20 with adapter modules. During the adapting process, all of the parameters of the 3 3 filters are fixed, then the adapters are trained using emotion data. The result significantly outperforms the baseline system, especially for IEMOCAP, where the UA and WA achieve 67.58% and 72.73%. On CHEAVD they achieve 34.08% and 43.96%. We attempted to increase the number of speakers during residual adapter training, but the performance did not benefit from this, perhaps because a more complex model is needed.
다음으로 잔여 어댑터 모델을 평가합니다. VoxCeleb2 데이터를 사용하여 어댑터 모듈로 동일한 ResNet20을 훈련합니다. 적응 과정에서 3개의 필터의 모든 파라미터가 고정된 다음 감정 데이터를 사용하여 어댑터를 훈련합니다. 그 결과 기준 시스템보다 훨씬 뛰어난 성능을 발휘하며, 특히 IEMOCAP의 경우 UA와 WA가 67.58%와 72.73%를 달성합니다. CHEAVD에서는 34.08%와 43.96%를 달성했습니다. 잔류 어댑터 훈련 중에 화자 수를 늘리려고 시도했지만 더 복잡한 모델이 필요하기 때문에 성능에 도움이 되지 않았습니다.
Evaluation of adapters: Finally, we want to clarify if the improvement in SER performance has benefited from domain-agnostic parameters learned by VoxCeleb2, or simply because adapters have fewer parameters so the model can be trained by emotion corpora. To answer the question, we keep the same experiment configuration with the residual adapters, retain the model but set all 3X3 convolutional filter weights to 0, so the domain-agnostic parameters will offer no information. As a result, the accuracy significantly drops, which proves the necessity of domain-agnostic parameters.
마지막으로 SER 성능의 개선이 VoxCeleb2가 학습한 도메인에 구애받지 않는 파라미터의 덕분인지, 아니면 단순히 감정 코퍼스로 모델을 학습할 수 있도록 어댑터의 파라미터 수가 적기 때문인지 명확히 하고자 합니다. 이 질문에 답하기 위해 잔여 어댑터와 동일한 실험 구성을 유지하고 모델을 유지하되 3개의 컨볼루션 필터 가중치를 모두 0으로 설정하여 도메인에 구애받지 않는 파라미터가 아무런 정보도 제공하지 않도록 했습니다. 결과적으로 정확도가 크게 떨어지며 도메인에 구애받지 않는 파라미터의 필요성이 입증됩니다.
Comparison to state-of-the-art systems
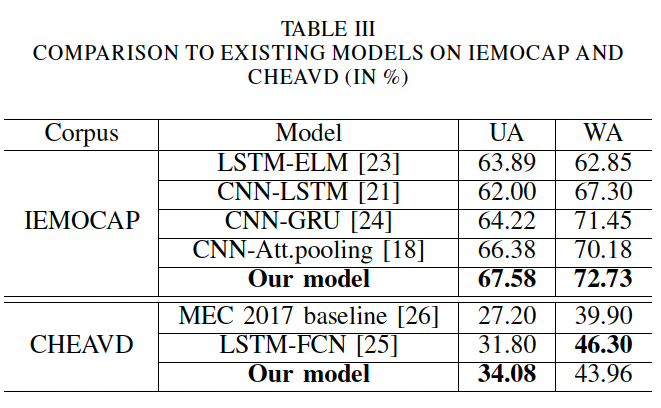
Compared to [25], our method does not exceed their WA but has better UA, indicating that the performance of data-limited small classes is improved. In fact these results show that the proposed residual adapter model can effectively utilize speaker characteristic information from the VoxCeleb2 training data, yet also provide discrimination ability for the SER task. In future we believe there is potential to exploit a deeper network for SER to further improve performance.