Journal/Conference: arXiv preprint arXiv:2111.02735
Year(published year): 2022
Author: Yingzhi Wang, Abdelmoumene Boumadane, Abdelwahab Heba
Subject: wav2vec 2.0, HuBERT, speech emotion recognition, speaker verification, spoken language understanding
A fine-tuned wav2vec2.0/Hubert benchmark for SER, Speaker verification and spoken language understanding
Introduction
- The wav2vec 2.0 model architecture contains mainly three modules. A convolutional neural network (CNN) feature encoder encodes the raw waveform inputs into latent speech representations. Mask operations are applied before they are fed to the Transformer based contextualized encoder. A quantization module is used to quantize the latent speech representations from the CNN encoder into a discretized embedding which is then used as the target.
- HuBERT shares the same architecture as wav2vec 2.0.
- Specifically, HuBERT consumes masked continuous speech features to predict predetermined cluster assignments. The predictive loss is applied over the masked regions, forcing the model to learn good high-level representations of unmasked inputs in order to infer the targets of masked ones correctly.
- In the field of Speech Emotion Recognition (SER), Speaker Verification (SV) and Spoken Language Understanding (SLU), it is still vague whether self-supervised models can produce better performance compared with traditional supervised models (spectral features + CNN-based feature extraction + RNN/Transformer based time series modeling) [12, 13, 14, 15, 16].
- For SER, [22] combined the features from frozen wav2vec2.0 with other hand-crafted prosodic features and then fed them into a 1d-CNN for a deeper extraction. [23] explored wav2vec fine-tuning strategies and 65.4% WA on IEMOCAP was achieved.
- Taking inspiration from [10] and [11], we added another fine-tuning method by splitting a pre-trained wav2vec 2.0/HuBERT model into two parts: the CNN feature encoder and the Transformer contextualized encoder. We froze the CNN feature encoder and only fine-tuned the Transformer contextualized encoder. We then tested partially fine-tuned wav2vec2.0/HuBERT pre-trained models together with the entirely fine-tuned ones with the following tasks below:
- Speech Emotion Recognition on IEMOCAP
- Speaker Verification on VoxCeleb1
- Spoken Language Understanding on SLURP [26]
- The code and fine-tuned models for SER and SLU have been open-sourced on SpeechBrain [27].
METHOD
- In this section, we will first introduce the pre-training of wav2vec 2.0/HuBERT model, then we will show our fine-tuning methods and downstream models for each task.
Pretrained wav2vec 2.0
wav2vec 2.0 사전 훈련은 BERT[28]의 마스크 언어 모델링과 유사하며 자체 감독 설정에서 수행됩니다. CNN 인코더 표현의 연속적인 시간 단계는 무작위로 마스킹되며, 모델은 컨텍스트화된 인코더의 출력에서 마스킹된 프레임에 대해 양자화된 로컬 인코더 표현을 재현하도록 훈련됩니다.
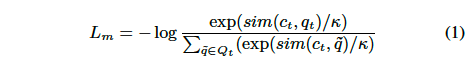
Training Objective
- sim($c_t$, $q_t$): cosine similarity between the contextualized encoder outputs $c_t$ and the quantized CNN encoder representations $q_t$.
- t is the masked time step
- $Q_t$: the union of candidate representations $\tilde{q}$ which includes $q_t$ and K = 100 distractors
- $\mathcal{K}$ is the temperature which is set to 0.1.
The distractors are outputs of the local encoder sampled from masked frames belonging to the same utterance as $q_t$. The contrastive loss is then given by $L_m$ summed over all masked frames. At the end, an L2 regularization is added to the contrastive loss, as well as a diversity loss to increase the use of the quantized codebook representations.
In this work, we compare four released wav2vec 2.0 pre-trained models
- the wav2vec 2.0 base model (12 transformer blocks and 768 embedding dimension)
- its ASR fine-tuned version
- the wav2vec 2.0 large model (24 transformer blocks and 1024 embedding dimension)
- its ASR fine-tuned version.
Both base and large models are pre-trained on 960h LibriSpeech [31] data, which is also used for their ASR fine-tuning. ASR fine-tuned models for both wav2vec 2.0 and HuBERT are taken into consideration because we assume that some tasks may benefit from the ASR fine-tuning.
Pretrained HuBERT
wav2vec 2.0과 동일한 방식으로, CNN으로 인코딩된 오디오 피처는 HuBERT에서 무작위로 마스킹됩니다. HuBERT 사전 훈련의 first iteration을 위한 레이블을 생성하기 위해 39차원 MFCC 특징에 K-평균 클러스터링이 적용됩니다. 이후 반복을 위한 더 나은 타깃을 생성하기 위해 k-평균 클러스터링은 이전 반복에서 사전 학습된 HuBERT 모델에서 추출한 latent features에 대해 작동합니다. 클러스터 레이블을 예측하기 위해 트랜스포머 블록 위에 projection layer가 추가됩니다.
Cross-entropy loss is computed over masked timestamps, which can be defined as:
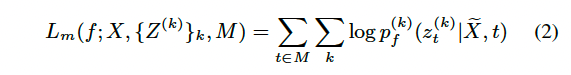
- $M \subset [T]$ denotes the set of indices to be masked for a length- $T$ sequence $X$
- $\tilde{X} = r(X;M)$ denotes a corrupted version of $X$ where $x_t$ is replaced with a mask embedding $\tilde{x}$ if $t \in M$.
- A masked prediction model $f$ takes as input $\tilde{X}$and predicts a distribution over the target indicies at each timestep $p_f(\cdot | \tilde{X} ; t)$.
- To improve target quality, cluster ensembles are utillized in case that an individual clustering model performs badly, $Z^(k)$ then denotes the target sequences generated by the $k$-th clustering model.
HuBERT pre-training uses the same optimizer and learning rate scheduler as wav2vec 2.0. For ASR fine-tuning, the projection layer is removed and replaced by a randomly initialized softmax layer, then the CTC loss is optimized. For more details of the pre-training of HuBERT, please refer to [11].
Like wav2vec 2.0, we compare three released HuBERT pretrained models
- the HuBERT base model (12 transformer blocks and 768 embedding dimension, of which no ASR fine tuned version is released)
- the HuBERT large model (24 transformer blocks and 1024 embedding dimension)
- its ASR fine-tuned version.
The HuBERT base model is pre-trained on 960h LibriSpeech data, while the large model is pre-trained on 60k hours Libri-Light [32] data. The ASR fine-tuning is also based on 960h LibriSpeech data.
Fine-tuning
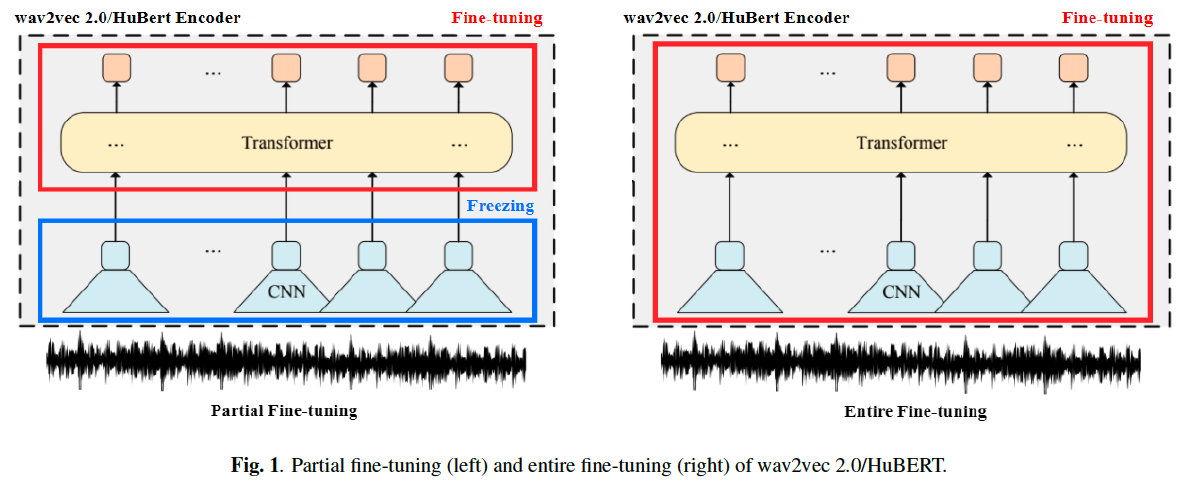
- Partial fine-tuning: the CNN based feature encoder and the transformer-based contextualized encoder.
- We froze the CNN-based feature encoder, fixing all the parameters of these CNN blocks, and only fine-tuned the parameters of the transformer blocks.
- Partial fine-tuning can be understood as a domain adaptation training for the top level, which aims to prevent interference and damage to the bottom CNN layers that already have an expressive ability.
- Entire fine-tuning: the CNN and Transformer modules are both fine-tuned during the downstream training process.
- By training general features at the bottom level, entire fine-tuning allows higher-level expressions to be more complete and more targeted.
Then we directly added simple downstream adaptors (classifier/decoder) to wav2vec 2.0/Hu-BERT without adding another heavy and redundant encoder. The downstream adaptors for each task are presented as below.
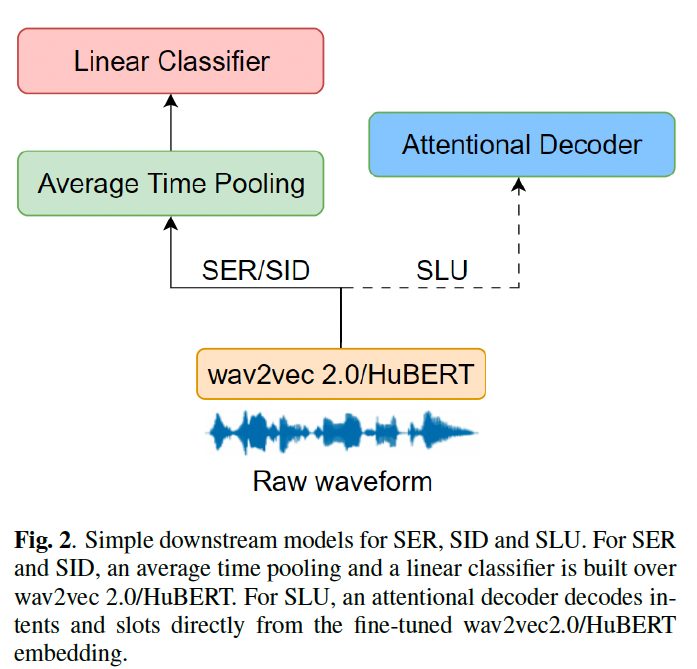
- For SER, an average time pooling and one linear layer are added as a simple downstream classifier (Fig.2). The average time pooling compresses variant time lengths into one, then the linear layer effectuates an utterance-level classification minimizing the cross-entropy loss.
- For SV, a Speaker Identification (SID) task is first implemented using the same downstream framework as SER. Pairwise cosine-similarity scores are then produced for SV on the pre-trained
SID embeddings before the linear classification layer.
Experiments
Datasets
The three most widely used and most representative datasets were chosen in our experiments, which are IEMOCAP for SER, VoxCeleb1 for SV and SLURP for SLU.
- IEMOCAP: The Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset has approximately 12 hours of data and consists of scripted and improvised dialogues by 10 speakers. In order to form a contrast in this work, we used 4 emotional classes as in SUPERB: anger, happiness, sadness and neutral, following the work of [34]. The evaluation metric is weighted accuracy (WA) and the experiments were carried out on two different split settings: Speaker-Dependent (SD) setting and Speaker-Independent (SI) setting. For SD, the results were averaged on 5 different random seeds for train-validation-test split. For SI, a 10-fold cross-validation was performed with a leave-two- speaker-out strategy (one for validation and one for test).
- 약 12시간 분량의 데이터로 구성되어 있으며, 10명의 화자가 대본에 따라 즉흥적으로 연기한 대화로 구성되어 있습니다. 이 작업에서 대비를 형성하기 위해 [34]의 연구에 따라 분노, 행복, 슬픔, 중립의 4가지 감정 클래스를 SUPERB에서와 같이 사용했습니다. 평가 지표는 가중 정확도(WA)이며 실험은 두 가지 다른 분할 설정에서 수행되었습니다: 화자 의존적(SD) 설정과 화자 독립적(SI) 설정입니다. SD의 경우, 훈련-검증-테스트 분할을 위해 5개의 서로 다른 무작위 시드에 대한 결과를 평균화했습니다. SI의 경우, 2명의 스피커를 제외하는 전략(하나는 검증용, 하나는 테스트용)을 사용하여 10배 교차 검증을 수행했습니다.
- VoxCeleb1: 1,251명의 화자로부터 나온 10만 개 이상의 발화, 총 351시간 분량의 오디오가 포함되어 있습니다. 먼저 speaker identification 작업을 구현하여 모델이 1211개의 서로 다른 보이스 프린트를 구별하는 방법을 학습하도록 했습니다. 그런 다음 사전 학습된 speaker identification 모델의 임베딩에서 코사인 유사도를 계산하여 40명의 화자로 구성된 vox1-o 테스트 세트에 대한 검증을 수행했습니다. 실험에서는 VoxCeleb2와 노이즈 증강을 사용하지 않았습니다. 평가 지표로 동일 오류율(EER)을 사용했으며, 훈련-검증 분할을 위해 5개의 서로 다른 시드에서 결과를 평균했습니다.
Fine-tuning settings
We rename the models we compare with a method as below.
- EF/PF/Frozen: Entirely Fine-tuned/Partially Fine-tuned/Not fine-tuned
- w2v/hbt: wav2vec 2.0/HuBERT based model
- base/large: base/large pre-trained model
- -/960h: with/without ASR fine-tuning using 960h LibriSpeech data
EF-w2v-base : an entirely fine-tuned wav2vec 2.0 base model
PF-hbt-large-960h : a partially fine-tuned HuBERT large model with an ASR fine-tuning.
For more detailed parameters of released pre-trained wav2vec 2.0/Hu-BERT models, please refer to [10] and [11].
During the fine-tuning process, we applied two different schedulers to respectively adjust the fine-tuning learning rate of the wav2vec 2.0/HuBERT encoder and the learning rate of the downstream model. Both the schedulers use an Adam Optimizer and linearly anneal the learning rates according to the performance of validation stage. For SER and SV, the initialized fine-tuning learning rate and the downstream learning rate are set to $10^{-5}$ and $10^{-4}$.
Results and discussion
Speech Emotion Recognition & Speaker Verification
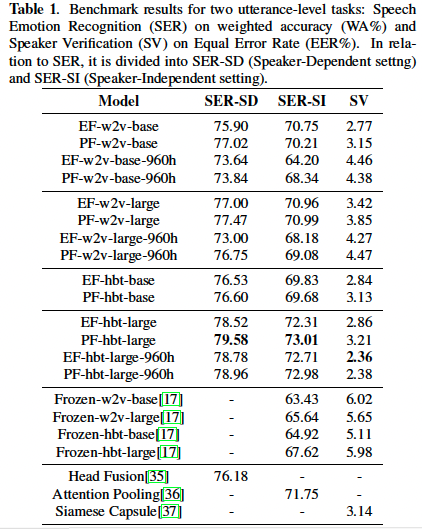
- [17]: SUPERB’s results as a non-fine-tuned baseline
- state-of-the-art baselines
- Head-Fusion ACNN [35] for SER-SD (Speaker-Dependent setting)
- Attention Pooling based representation [36] for SER-SI (Speaker-Independent setting) and
Siamese Capsule network [37] for SV
- SER: 전체 미세 조정보다 부분 미세 조정이 더 나은 미세 조정 방법인 것으로 나타났습니다. IEMOCAP은 데이터가 12시간밖에 되지 않는 작은 데이터 세트이므로 너무 많은 파라미터를 학습시키면 과적합이 쉽게 발생할 수 있습니다. 또한 ASR 미세 조정이 다운스트림 SER 작업에 도움이 되지 않는 것으로 나타났는데, 이는 ASR 미세 조정 중에 prosodic information가 손실되었음을 시사합니다.
CONCLUSIONS
In this work we explored different fine-tuning methods on two of the most powerful self-supervised models (wav2vec 2.0 and HuBERT), then benchmarked their performance on Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding tasks. State-of-the-art results were achieved for all the three tasks, proving the excellent generalizability of wav2vec 2.0/HuBERT on learning prosodic, voice-print and semantic representations. We hope to show the broad prospects of self-supervised learning and also provide some useful insights for its industrial applications.