Journal/Conference: arXiv preprint arXiv:2105.01051
Year(published year): 2021
Author: Shu-wen Yang, Po-Han Chi, Yung-Sung Chuang, Cheng-I Jeff Lai, Kushal Lakhotia,
Yist Y. Lin, Andy T. Liu, Jiatong Shi, Xuankai Chang6, Guan-Ting Lin,
Tzu-Hsien Huang, Wei-Cheng Tseng, Ko-tik Lee, Da-Rong Liu, Zili Huang, Shuyan Dong,
Shang-Wen Li, Shinji Watanabe6, Abdelrahman Mohamed, Hung-yi Lee
Subject: Speech, Self-Supervised Learning, Representation Learning, Model Generalization, Benchmark, Evaluation
SUPERB: Speech processing Universal PERformance Benchmark
Summary
- The paper introduces SUPERB, a standardized benchmark for evaluating the generalizability of pretrained models on various speech processing tasks.
- The framework uses a universal representation encoder that is pretrained on self-supervised learning (SSL) tasks and then fine-tuned on downstream tasks with lightweight prediction heads.
- The results show that the SUPERB framework yields competitive performance compared to traditional supervised pipelines and outperforms log mel filterbank (FBANK) by a large margin, demonstrating the potential of developing powerful, generalizable, and reusable pretrained models for speech processing.
Introduction
- SSL has been explored in speech, including pretraining with generative loss [7, 8, 9, 10], discriminative loss [11, 12, 13, 14], or multi-task [15, 16].
- While these works showed promising results of SSL on various speech processing tasks, unlike CV or NLP areas, they were investigated with different datasets and experimental setups. Absence of a shared benchmark makes it hard to compare and draw insights across the techniques. Furthermore, existing works explored a limited number of tasks or require heavyweight downstream training [9, 12, 14], blurring the generalizability and re-usability of SSL models across tasks. Both factors limit the impact of SSL on speech processing in research and industry.
- SUPERB aims to 360-degree examine models’ capability and collects various tasks with limited labeled data from speech communities to align with common research interests.
- Compared to existing efforts, SUPERB targets at the direct usability of pretrained models on various popular tasks through any usage3. As finetuning pretrained models typically requires huge resources and hinders the re-usability, in this paper, we focus on investigating a simple framework solving all SUPERB tasks with a frozen, shared pretrained model, and lightweight prediction heads finetuned for each task.
Speech processing Universal PERformance Benchmark
- Tasks are designed with the following principles: (1) conventional evaluation protocols from speech communities, (2) publicly available datasets for everyone to participate, (3) limited labeled data to effectively benchmark the generalizability of models.
Content
- Four tasks are collected from ASR and Spoken Term Detection communities. The former aims to transcribe speech into text content; the latter is to detect the spoken content with minimal effort even without transcribing.
Phoneme Recognition(PR)
PR transcribes an utterance into the smallest content units. We include alignment modeling in the PR task to avoid the potential inaccurate forced alignment. LibriSpeech [23] train-clean-100/dev-clean/test-clean subsets are adopted in SUPERB for training/validation/testing. Phoneme transcriptions are obtained from the LibriSpeech official g2p-model-5 and the conversion script in Kaldi librispeech s5 recipe. The evaluation metric is phone error rate (PER).
Automatic Speech Recognition(ASR)
ASR transcribes utterances into words. While PR analyzes the improvement in modeling phonetics, ASR reflects the significance of the improvement in a real-world scenario. LibriSpeech train-clean-100/devclean/ test-clean subsets are used for training/validation/testing. The evaluation metric is word error rate (WER).
Keyword Spotting(KS)
KS detects preregistered keywords by classifying utterances into a predefined set of words. The task is usually performed on-device for the fast response time. Thus, accuracy, model size, and inference time are all crucial. We choose the widely used Speech Commands dataset v1.0 [24] for the task. The dataset consists of ten classes of keywords, a class for silence, and an unknown class to include the false positive. The evaluation metric is accuracy (ACC).
Query by Example Spoken Term Detection(QbE)
QbE detects a spoken term (query) in an audio database (documents) by binary discriminating a given pair of query and document into a match or not. The English subset in QUESST 2014 [25] challenge is adopted since we focus on investigating English as the first step. The evaluation metric is maximum term weighted value (MTWV) which balances misses and false alarms.
Speaker
Speaker Identification(SI)
SID classifies each utterance for its speaker identity as a multi-class classification, where speakers are in the same predefined set for both training and testing. The widely used VoxCeleb1 [26] is adopted, and the evaluation metric is accuracy (ACC).
Automatic Speaker Verification(ASV)
ASV verifies whether the speakers of a pair of utterances match as a binary classification, and speakers in the testing set may not appear in the training set. Thus, ASV is more challenging than SID. Vox- Celeb1 [26] is used without VoxCeleb2 training data and noise augmentation. The evaluation metric is equal error rate (EER).
Speaker Diarization(SD)
SD predicts who is speaking when for each timestamp, and multiple speakers can speak simultaneously.
The model has to encode rich speaker characteristics for each frame and should be able to represent mixtures of signals. LibriMix [27] is adopted where LibriSpeech train-clean-100/dev-clean/test-clean are used to generate mixtures for training/validation/testing. We focus on the two-speaker scenario as the first step. The time-coded speaker labels were generated using alignments from Kaldi LibriSpeech ASR model. The evaluation metric is diarization error rate (DER).
Semantics
Two tasks are collected from Spoken Language Understanding (SLU) community. While most works for these tasks are done in two stages: transcribing speech into text and predicting semantics on transcribed text, we focus on inferring high-level semantics directly from raw audio in an end-to-end fashion.
Intent Classification(IC)
IC classifies utterances into predefined classes to determine the intent of speakers. We use the Fluent Speech Commands [28] dataset, where each utterance is tagged with three intent labels: action, object, and location. The evaluation metric is accuracy (ACC).
Slot Filling(SF)
SF predicts a sequence of semantic slot-types from an utterance, like a slot-type FromLocation for a spoken
word Taipei, which is known as a slot-value. Both slot-types and slot-values are essential for an SLU system to function [18]. The evaluation metrics thus include slot-type F1 score and slotvalue CER [29]. Audio SNIPS [18] is adopted, which synthesized multi-speaker utterances for SNIPS [30]. Following the standard split in SNIPS,US-accent speakers are further selected for training, and others are for validation/testing.
Paralinguistics
Emotion Recognition(ER)
ER predicts an emotion class for each utterance. The most widely used ER dataset IEMOCAP [31] is adopted, and we follow the conventional evaluation protocol: we drop the unbalance emotion classes to leave the final four classes (neutral, happy, sad, angry) with a similar amount of data points and cross-validates on five folds of the standard splits. The evaluation metric is accuracy (ACC).
Framework: Universal Representation
- Our framework aims to explore how simple and general the solution can be. Thus, we freeze the parameters of pretrained models across tasks and extract fixed representations to be fed into each task-specialized prediction head (small downstream model). Compared to previous setups in speech representation learning [9, 12, 13], the framework puts an explicit constraint on downstream models to be as lightweight as possible for all tasks, as their parameter size and required training resources are also crucial for the framework to be simple and re-usable in various use cases. With the above principles, the pretrained model solving all SUPERB tasks in this framework would be a universal representation encoder.
Self-supervised pretrained models
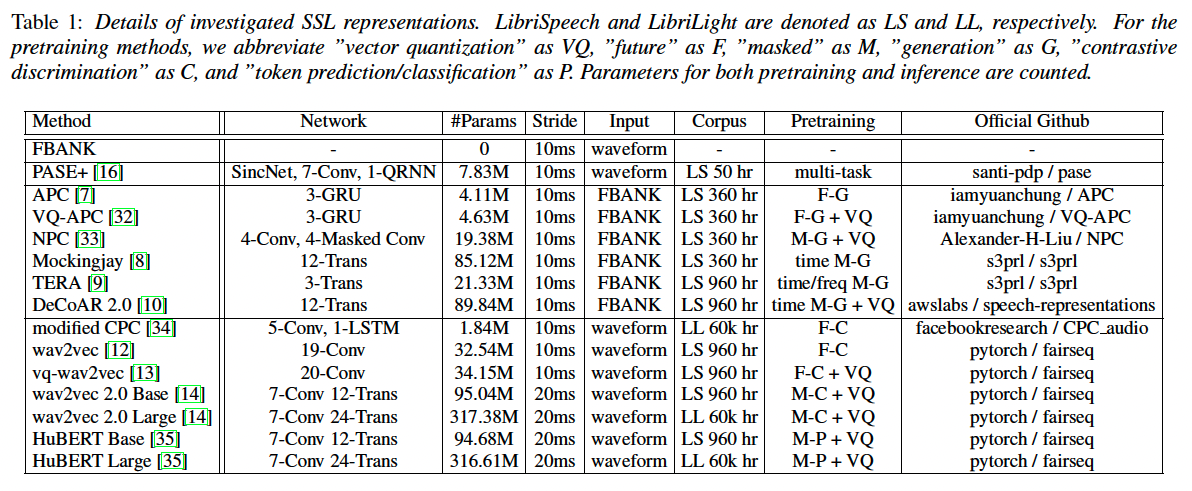
SSL models explored in this paper are summarized in Table 1 and categorized into three learning approaches: generative modeling, discriminative modeling, and multi-task learning.
음성 처리의 맥락에서 판별 모델링은 자동 음성 인식(ASR), 화자 식별, 구어 감지 등 다양한 종류의 음성을 구별하는 것이 목표인 작업에 자주 사용됩니다. 반면 생성 모델링은 원본 음성과 유사한 새로운 음성 샘플을 생성하는 것이 목표인 TTS(텍스트 음성 변환), 음성 변환, 소스 분리와 같은 작업에 자주 사용됩니다.
Generative modeling
- 생성 모델링은 입력 데이터의 확률 분포를 모델링하고 이 모델을 사용하여 원본 데이터와 유사한 새로운 데이터 샘플을 생성하는 머신 러닝의 한 유형입니다. 생성 모델은 이미지 합성, 텍스트 생성, 음성 합성과 같은 작업에 자주 사용됩니다.
- APC adopts the language model-like pretraining scheme on a sequence of acoustic features (FBANK) with unidirectional RNN and generates future frames conditioning on past frames.
- VQ-APC further applies vector-quantization (VQ) layers onto APC’s representation to make it compact and low bit-rate.
- Mockingjay adopts the BERT-like pretraining on Transformer encoders by masking the input acoustic features in time axis and re-generating the masked parts.
- TERA extends Mockingjay to further mask the frequency bins. NPC improves the inference speed upon APC by replacing RNN with CNN and changing the future generation to masked reconstruction as Mockingjay.
- De-CoAR 2.0 improves upon Mockingjay by inserting a VQ layer right before the final prediction like VQ-APC, and is trained by larger input mask, larger batch size, and more unlabeled data.
Discriminative modeling
- 판별 모델링은 입력 데이터가 주어졌을 때 출력의 조건부 확률을 모델링하는 머신 러닝의 한 유형입니다. 판별 모델은 분류, 회귀, 시퀀스 라벨링과 같은 작업에 자주 사용됩니다.
- CPC discriminates the correlated positive samples from negative samples with contrastive InfoNCE loss, which maximizes the mutual information between raw data and representations.
- Modified CPC [34] and wav2vec [12] proposed several architecture changes to improve CPC.
- vq-wav2vec introduces a VQ module to wav2vec. The module discretizes speech into a sequence of tokens after InfoNCE pretraining. Tokens are used as pseudo-text to train a BERT as did in NLP for contextualized representations.
- wav2vec 2.0 merges the pipeline of vq-wav2vec into one end-to-end training scheme by applying time masking in the latent space and replacing BERT’s token prediction with InfoNCE’s negative sampling to handle the intractable normalization on continuous speech. Motivated by DeepCluster [36],
- Hu-BERT [35] enables BERT’s token prediction via off-line clustering on representations. The clustered labels at the masked locations are then predicted.
Multi-task learning
MLT is applied in PASE+ [16], where lots of pretraining objectives are adopted: waveform generation, prosody features regression, contrastive InfoMax objectives, and more. Multiple contaminations are also applied to input speech like reverberation and additive noise.
Downstream models and policies
We design our framework to keep the downstream models and their finetuning simple, while ensuring the performance across pretrained models is comparable and the best model in each task is competitive. Since the last-layer representation is not always the best, the framework collects multiple hidden states from the pretrained model and weighted-sum them as the final representation. For a fair comparison, we also limit the space for downstream hyper-parameters tuning5. Downstream models and algorithms are summarized in the following and will be released in detail as a part of the challenge policy.
- PR,KS, SID, IC, ER are simple tasks that are solvable with linear downstream models. Hence, we use a frame-wise linear transformation for PR with CTC loss; mean-pooling followed by a linear transformation with cross-entropy loss for utterance-level tasks (KS, SID, IC, and ER). These five tasks also serve as the direct indication of representations’ quality following the conventional linear evaluation protocol.
- For ASR, a vanilla 2-layer 1024-unit BLSTM is adopted and optimized by CTC loss on characters. The trained model is decoded with LibriSpeech official 4-gram LM powered by KenLM [37] and flashlight [38] toolkit.
- We mostly follow the system proposed by GTTS-EHU for QUESST at MediaEval 2014 [39] for QbE but replace the conventional supervised phoneme posteriorgram (PPG) with SSL representations. We run Dynamic Time Warping[40] on all hidden states separately with standard distance functions and obtain a score for each query-document pair. The best distance function / hidden state pair is reported. Regarding SF, slot-type labels are represented as special tokens to wrap the slot-values in transcriptions.
- SF is then re-formulated as an ASR problem. The finetuning scheme is the same as in our ASR task, except for the pre-processing to encode slot-types into transcriptions and post-processing to decode slot-types and slot-values from hypotheses.
- As for ASV, we adopt the well-known x-vector [41] as the downstream model and change Softmax loss to AMSoftmax loss with the same hyper-parameters as [26]. The simple cosine-similarity backend is used to produce pairwise matching scores. We employ the end-to-end training scheme with permutation-invariant training (PIT) loss [42] to SD, instead of using clustering-based methods. We leverage a single-layer 512-unit LSTM for the downstream model.
Experiment
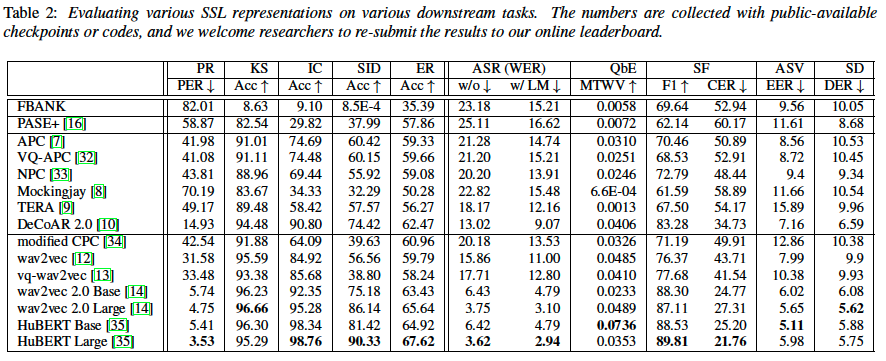
- For the tasks using linear models, FBANK cannot work on any task, while SSL representations all perform well to some degree with different specializations.
- It is a surprise that wav2vec 2.0 and HuBERT conquers PR and IC with just linear models and outperforms others by a large margin. Their results on SID and ER are also highly competitive.
- FBANK achieves competitive performance when allowing non-linear downstream models in ASR, SF, ASV, and SD, and yields better performance than some SSL representations.
Conclusion
We present SUPERB, a challenge to generally benchmark the capability of SSL pretrained models on speech processing. We demonstrate a simple framework to solve all SUPERB tasks which leverages a frozen, shared pretrained model and achieves competitive performance with minimal architecture changes and downstream finetuning. We have open-sourced the evaluation toolkit2 and will release the detailed challenge policy on the leaderboard website1. We welcome the community to participate and drive the research frontier.