Journal/Conference : ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Year(published year): 2022
Author: Itai Gat, Hagai Aronowitz, Weizhong Zhu, Edmilson Morais, Ron Hoory
Subject: Speech emotion recognition, speaker normalization, self-supervised learning
Speaker Normalization for Self-Supervised Speech Emotion Recognition
Summary
- The paper proposes a method for speech emotion recognition that normalizes speaker characteristics to improve generalization capabilities of the model.
- The proposed method uses a pre-trained deep neural network for speech representation learning, called HuBERT, as the upstream model.
- The authors proposed two training strategies for their method: speaker normalization projector and train all parameters. They showed that the latter approach outperforms the former and achieves state-of-the-art results in speech emotion recognition.
- The authors evaluated their proposed method on both speaker-independent and speaker-dependent setups using various training set sizes and showed that their method outperforms the current state-of-the-art results for both setups.
- The proposed method has potential applications in various fields, such as human-robot interaction, virtual assistants, and mental health monitoring.
Introduction
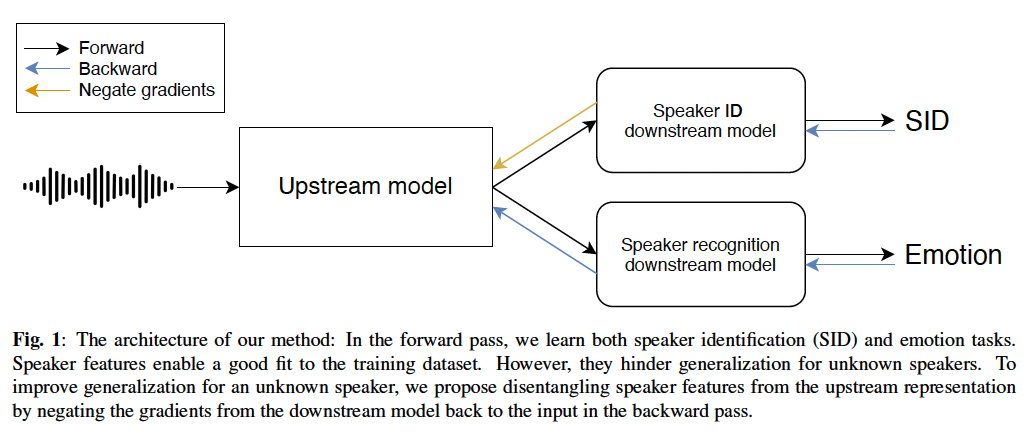
The classic self-supervised learning process relies on a representation trained on a large unlabeled dataset, and a downstream task trained on a relatively small labeled dataset. Generally, our method enhances a downstream task performance by using a third dataset with labels different from the downstream task labels. For example, in this work, for speaker emotion recognition, our method normalizes undesired characteristics from the self-supervised representation to improve performance on the speech emotion recognition task. We carry this out by learning a feature representation that excels at speech emotion recognition while being robust enough for speaker characteristics (see Fig. 1). Our proposed method outperforms the current state-of-the-art results for both speaker-dependent and speaker-independent settings.
In summary, we propose a general framework for speaker characteristics normalization from a self-supervised representation. We address the small dataset settings issue and propose a framework for it on the IEMOCAP benchmark. Through extensive experiments, we show that our method outperforms the current speech emotion recognition state-of-the-art results on several setups.
기존의 self-supervised learning process는 레이블이 지정되지 않은 대규모 데이터 세트에서 학습된 표현과 상대적으로 작은 레이블이 지정된 데이터 세트에서 학습된 downstream task에 의존합니다. 일반적으로 이 방법은 downstream task label과 다른 레이블을 가진 세 번째 데이터 세트를 사용하여 다운스트림 작업의 성능을 향상시킵니다. 예를 들어, 이 연구에서는 화자 감정 인식의 경우, self supervised representation에서 원하지 않는 특성을 정규화하여 음성 감정 인식 작업의 성능을 개선합니다. 이를 위해 화자 특성에 대해 충분히 robust하면서도 음성 감정 인식에 탁월한 feature representation을 학습하여 이를 수행합니다(그림 1 참조). 우리가 제안한 방법은 speaker-dependent and speaker-independent settings에서 현재의 최신 결과보다 성능이 뛰어납니다.
요약하면, 우리는 self supervised representation에서 speaker characterisitcs normalization를 위한 일반적인 프레임워크를 제안합니다. 작은 데이터 세트 설정 문제를 해결하고 이를 위한 프레임워크를 IEMOCAP benchmark에서 제안합니다. extensive experiment을 통해 이 방법이 여러 설정에서 현재 음성 감정 인식의 최신 결과보다 성능이 우수하다는 것을 보여줍니다.
Related Work
Self-supervised trained models
음성 처리에서 사용되는 대부분의 self-supervised techniques은 세 가지 범주로 나뉩니다. 첫 번째 범주에서는 constuctive InfoNCE loss과 결합된 다양한 아키텍처가 사용됩니다. 두 번째 범주는 마스킹 된 토큰 분류를 기반으로 합니다. 세 번째 범주는 future frame 생성 및 입력의 마스크 된 부분을 재구성하는 인코더-디코더 접근 방식과 같은 다양한 기법을 사용하여 재구성 손실을 사용합니다.
Feature normalization
Nagrani et al. [17] suggest using a ”confusion loss,” which is a cross-entropy loss computed by comparing the prediction to a uniform distribution. Ganin et al. [18] use extra knowledge regarding the data-domain to tackle a domain adaptation problem. They propose to normalize domain features by negating gradients of a loss that predict the domain label. In contrast to those methods, we normalize cues based on a task rather than a domain. Additionally, our method focuses on the self-supervised representation framework.
Nagrani 등[17]은 다음과 같이 계산된 교차 엔트로피 손실인 “혼동 손실”을 사용할 것을 제안합니다.
예측을 균일 분포와 비교하여 계산되는 교차 엔트로피 손실입니다. Ganin 등[18]은 데이터 도메인에 관한 추가 지식을 사용하여 도메인 적응 문제를 해결합니다. 이들은 도메인 레이블을 예측하는 손실의 기울기를 음수화 하여 도메인 특징을 정규화 할 것을 제안합니다. 이러한 방법과 달리, 우리는 도메인이 아닌 작업을 기반으로 단서를 정규화 합니다. 또한, 우리의 방법은 자기 지도 표현 프레임 워크에 중점을 둡니다.
Emotion Recognition
음성 감정 인식은 발화를 기반으로 감정을 예측합니다. 음성 감정 인식에서 가장 널리 사용되는 벤치마크는 대화형 감정 다이나믹 모션 캡쳐 데이터베이스(IEMOCAP). 음성 감정 인식을 위해 초기 E2E 방식은 CNN과 LSTM을 결합합니다. 이후 attention based model은 다음과 같은 이유로 CNN과 LSTM 조합보다 성능이 뛰어났습니다. 최근 몇 년 동안 self-supervised learning model은 레이블이 지정되지 않은 데이터로부터 high quality representations을 학습할 수 있는 능력으로 인해 음성 처리 연구에서 큰 관심을 불러일으키고 있습니다. 이를 반영하여 Yang 등[25]은 벤치마크에서 self supervised model이 감정 인식에서 최첨단 결과를 생성한다는 것을 입증했습니다. 본 논문에서는 self supervised model과 normalization of speaker characteristics를 결합하여 음성 감정 인식을 향상시키는 방법을 제시합니다.
Method
In the following, we propose an approach for learning a task while normalizing cues from a
different task (possibly from another dataset) in an upstream downstream architecture.
Speaker Normalization
Upstream - Downstream 접근 방식을 사용하면 단일 Upstream model보다 하나의 task 이상을 할수 있습니다. 예를 들어 화자 식별과 감정 인식 과제를 모두 해결할 수 있습니다. 이 방법에는 세가지 discriminative learners를 고려합니다. 첫번째는 upstream model $h_w$, 두번째는 emotion recognition learner $g_{w_{er}}$, 그리고 세번째는 speaker identification classifier $g_{w_{id}}$.
감정 Downstream 작업에서 원치 않는 화자 특성을 활용하지 못하도록 Upstream 표현에서 이를 정규화하여 감정 분류기가 이러한 단서를 활용할 수 없도록 할 것을 제안합니다. 이를 위해 speaker identification task 과 관련하여 Upstream 모델의 gradients를 음수화(negating)할 것을 제안합니다. 간단하게 설명하기 위해 stochastic gradient descent(SGD)을 사용하는 방법을 설명하지만, 모든 최적화 알고리즘에 쉽게 적용할 수 있습니다.
접근 방식은 두 단계로 구성됩니다. 첫번째 단계는 standard gradient-based optimization. SGD 알고리즘을 사용하는 standard gradient-based learning에서 Upstream 및 Downstream 가중치 업데이트 단계는 다음과 같습니다.
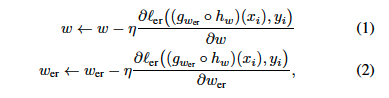
여기서 $\eta$는 학습률이고 $l_{er}$은 감정인식 손실(예: 교차 엔트로피 손실)입니다.
두번째 단계 에서는 Upstream 모델의 화자 ID 특징을 다음과 같이 정규화 합니다.
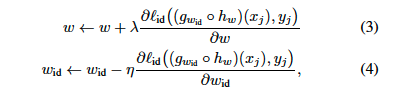
여기서 $\lambda$는 화자 ID 손실에 대해 Upstream 모델에 대해서 gradient ascent 단계를 수행하여 Upstream 모델의 화자 특징을 어느정도 정규화할지 설정하는 파라미터 입니다. 그림1에 방법을 설명해 두었습니다. 이 단계는 independent 하기 때문에 감정인식에 사용되는 데이터에 화자 식별 레이블을 지정할 필요가 없으며 그 반대의 경우도 마찬가지입니다.
Training Strategies
Self-supervised upstream model은 많은 파라미터가 있습니다. HuBERT Large 모델에는 3억 1700만개의 파라미터가 있으며 HuBERT X-Large에는 거의 10억개의 파라미터가 있습니다. 따라서 이러한 네트워크를 fine tuning하는 것은 어려울수 있습니다. 그래서 두 가지 training procedure를 제안합니다:
- Speaker Normalization projector: 매개변수 $\hat{w}$가 있는 새로운 비선형 레이어를 도입합니다. $\hat{w}$은 Upstream과 Down Stream 모델 사이의 게이트 입니다. 감정인식 단계에서 upstream model을 최적화 하기 위해 $\hat{w}$을 추가합니다. 반면 speaker identification 작업에는 수식(3)을 수정하여 $\hat{w}$을 단독으로 최적화 합니다. 이렇게 하면 upstream의 최적화 단계를 건너뛸 수 있으므로 speaker ID 단계에서 gradient computation overhead를 줄일 수 있습니다.
- 모든 파라미터를 훈련합니다: 이 접근방식에서는 위에서 설명한 내용에 따라 up stream, down stream 파라미터 모두를 훈련합니다.
다음 섹션에셔는 다양한 훈련 세트 크기를 사용하여 화자 independent 설정과 dependent 설정에 대한 두가지 훈련 전략에 대해서 설명합니다.
Experiments
이 섹션에서 우리는 우리의 접근 방식을 소개하고 이전 연구와 비교합니다.
Experimental setup
IEMOCAP 데이터셋을 사용했습니다. 감정 클래스는 중립, 행복, 슬픔, 분노 네 가지를 사용합니다. Upstream 모델에는 HuBERT 기본 모델과 large 모델을 모두 사용했습니다. Downstream 모델의 경우 HuBERT의 temporal dimension에서 비선영 projection을 사용했습니다. $\lambda$의 하이퍼 파라미터 범위는 [0.01, 0.0001]로 잡았지만 결국 가장 좋은 결과를 내는 것은 $\lambda$ = 0.001일때 였습니다. 따라서 우리는 모든 실험에 이 $\lambda$ 값을 사용했습니다.
Emotion Recognition
speaker-independent, 두 화자의 발화를 테스트에 사용하고 다른 8명의 발화를 각 화자의 훈련 및 검증에 사용하는 5 fold cross validationㅇㄹ 수행했습니다. stopping criteria는 speaker out of distribution evaluation에서도 중요한 역할을 합니다. validation 세트에서 가장 좋은 epoch를 기준으로 테스트 세트의 정확도를 보고합니다.
이 작업에서는 unknown speaker에 대한 generalization capabilities를 조사합니다. 따라서 speaker independent setup에 초점을 맞춥니다. 그럼에도 불구하고 우리의 방법은 speaker dependent setup도 개선합니다. 그 설정은 train test split이 랜덤이고 train과 test 세트에 모든 화자가 포함되어 있습니다.
표1에는 speaker dependent(SD) 설정과 independent(five-fold) 설정의 결과가 나와있습니다. speaker independent 경우 두번째 훈련 절차가 SOTA 결과를 달성했습니다. 이러한 개선은 HuBERT Large and Base 모두에서 일관되게 나타났습니다. 또한 이 방법은 speaker dependent 설정에서 SOTA결과에서 0.5% 개선했습니다.
Upstream model에서 speaker information을 정규화하는 방법의 ability를 평가했습니다. speaker identification을 위해 고정된 업스트림(즉, 업스트림 모델을 미세 조정하지 않고) HuBERT Large에 대해 분류기를 두 번 훈련시켰습니다. 먼저 speaker normalization method 이전에 HuBERT에 대해 down stream 모델을 훈련시켰습니다. 60.7%의 정확도를 얻었습니다. 그런 다음 제안한 방법으로 훈련된 고정된 HuBERT에 대해 additional speaker ID down stream model을 훈련했습니다. 그 결과 45.9%의 정확도를 얻었습니다. 따라서 원하는 대로 우리의 방법은 Upstream 모델의 화자 ID 특징에 해를 끼쳤습니다.
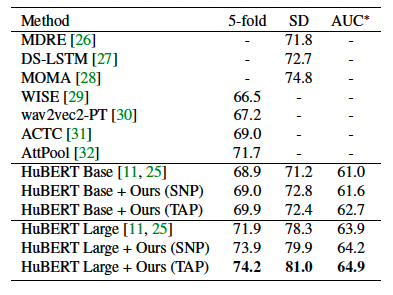
표 1: 5 fold cross validation을 위해 오디오 기능만 사용한 speaker independent 설정과 랜덤 train test split을 사용한 speaker dependent 설정에 대한 IEMOCAP의 최신 결과. 5-fold 및 SD 설정의 경우 weighted accuracy(WA) metric을 보고합니다. speaker noramalization projector(SNP)와 Train All Parameters(TAP)는 Training strategies 에 설명된 훈련 전략 입니다. 우리의 방법을 사용하면 현재 speaker independent SOTA 보다 2.3% 개선되었고 speaker dependent SOTA 보다는 0.5%가 개선되었습니다. 추가적으로 HuBERT Base and Large Models에서 둘다 개선된 우리의 접근 방법인 low resource 설정의 AUC를 제시합니다.
Small data settings
적은 리소스로 음성 감정 인식을 테스트 하기 위해 훈련 세트의 클래스당 샘풀 수를 늘릴것을 제안합니다. 결과를 stabilize 하기 위해 우리는 각 단계를 서로 다른 random split으로 다섯번 실행하고 각 단계의 mean을 계산합니다. 마지막으로 주어진 방법의 전반적 성능을 정량화 하기 위해 Fig2의 AUC를 계산합니다. 직관적으로 AUC 점수는 평가하는 각 설정에 대한 점수의 평균을 반영합니다.
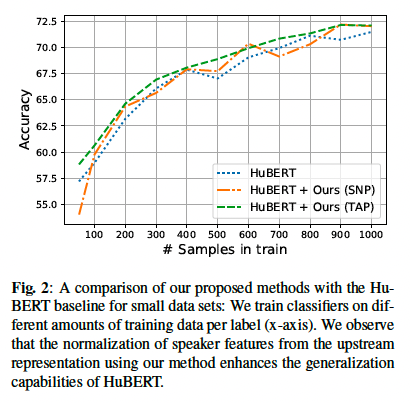
그림 2는 우리가 제안한 low-source 설정에 대한 결과를 보여줍니다. 각 단계에서 우리는 HuBERT Large model을 우리의 방법을 사용한것과 사용하지 않은것으로 훈련했습니다. 우리는 각 method에 대한 AUC를 표1에 보고했습니다. 우리의 방법을 사용하여 기본과 대형 HuBERT 모델을 모두 개선할 수 있었습니다. 그림 2에서 우리의 방법은 모들 설정에서 HuBERT 정확도를 향상 시킨다는 것을 알 수 있습니다.
Conclusion
이 논문에서는 self-supervised feature representation에서 speaker characteristics normalization를 위한 프레임워크를 제시했습니다. 우리의 접근 방식은 한 과제에 대한 판별 학습과 다른 과제에 대한 적대적 학습을 결합합니다. 또한, 이 방법은 각 과제마다 다른 데이터 세트를 사용할 수 있습니다. 다양한 모델을 대상으로 테스트한 결과 음성 감정 인식에서 강력한 최첨단 결과를 얻었습니다. 또한 수정된 버전의 IEMOCAP을 사용하여 리소스가 적은 환경에서 연구할 것을 제안하고 그 결과 우리 방법이 성공적임을 보여주었습니다.