Journal/Conference : ICASSP IEEE
Year(published year): 2022
Author: Edmilson Morais, Ron Hoory, Weizhong Zhu, Itai Gat, Matheus Damasceno and Hagai Aronowitz
Subject: Speech Emotion Recognition, self-supervised features, end-to-end systems
Speech Emotion Recognition Using Self-Supervised Features
Summary
- The paper proposes a modular End-to-End (E2E) Speech Emotion Recognition (SER) system based on an Upstream + Downstream architecture model paradigm.
- The proposed system uses self-supervised features extracted from speech signals and script transcriptions of the speech signals.
- The authors compare the performance of different Upstream models for speech-based feature extraction, including Wav2vec 2.0 and huBERT.
- The authors fine-tune the features extracted from these models and combine them using an aggregator to create multimodal feature vectors.
- The authors achieve state-of-the-art performance on the IEMOCAP dataset, demonstrating the effectiveness of their multimodal approach to SER.
Introduction
인간의 감정은 본질적으로 복잡하고 여전히 어려운 연구 문제 입니다. 인간은 종종 음성 특성, 언어적 내용, 표정, 신체 동작과 같은 여러가지 단서를 동시에 사용하여 감정을 표현하기 때문에 SER은 본질적으로 복잡한 multi modal 작업입니다. 또한 데이터 수집의 어려움으로 인해 공개적으로 사용 가능한 데이터 세트에는 감정 표현의 개인적 차이를 제대로 커버할 수 있는 화자가 충분하지 않은 경우가 많습니다. 그 결과 SER에 통합된 가장 일반적인 딥러닝 기술 중 일부는 transfer learning, multitask learning , multimodal system 분야와 관련 있습니다.
본 논문의 주요 목표는 다음과 같습니다: (1)다양한 self supervised feature을 쉽게 사용/통합할 수 있는 upstream + downstream 아키텍처 모델 패러다임에 기반한 모듈형 엔드투엔드(E2E) SER 시스템을 소개하고, (2)다양한 구성에서 제안된 E2E 시스템의 성능을 비교/분석하는 일련의 실험을 제시하며, (3)음성 모달리티만 사용함에도 불구하고 제안된 E2E 시스템이 음성 및 텍스트 모달리티를 모두 사용하는 멀티모달 시스템이 달성하는 SOTA 결과와 비교하여 SOTA 결과를 얻을 수 있음을 보여주는 것입니다.
Proposed Model
이 논문에서 SER의 문제점을 연속적인 음성을 불연속적인 감정 레이블로 범주화하는 것이라고 여기고 이를 공식화 합니다. 여기서 사용되는 모델은 Upstream + Downstream 모델입니다.
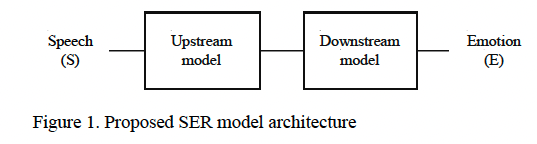
Upstream model: task-independent model, pretrained in self-supervised fashion and it works as Encoder or Front-End Model responsible for feature extraction.
- 일반적으로 Front End 모델은 입력 데이터를 처리하고 추가 처리 또는 분류를 위해 Downstream 모델에서 사용할 수 있는 관련 특징을 추출하는 역할을 담당하는 모델 유형입니다. 음성 처리의 맥락에서 Front End 모델은 일반적으로 원시 음성 신호에서 MFCC 또는 필터뱅크 에너지와 같은 음향적 특징을 추출하는 데 사용됩니다. 그런 다음 이러한 특징은 분류기나 음성 인식 시스템과 같은 Downstream 모델에 입력으로 사용됩니다.
- 반면에 인코더는 입력 데이터를 입력의 가장 중요한 특징을 포착하는 저차원 표현으로 변환하는 데 사용되는 일종의 신경망 계층입니다. 인코더는 일반적으로 입력 데이터가 고차원적이고 복잡한 이미지 또는 음성 인식과 같은 작업을 위한 딥 러닝에 사용됩니다.
- 이 논문에서 설명하는 SER 모델의 맥락에서 업스트림 모델은 프론트엔드 모델이자 인코더입니다. 입력 음성 신호를 처리하고 관련 특징을 추출한 다음 분류를 위해 다운스트림 모델에 입력으로 사용하는 역할을 합니다. 또한 업스트림 모델은 음성의 일반적인 특징을 학습하기 위해 자가 지도 방식으로 사전 학습되므로 SER 작업에 강력한 특징 추출기가 됩니다.
Downstream model: task-dependent model, responsible for final task of classifying the features generated by the Upstream model into categorical labels of emotion.
Dataset
IEMOCAP은 12시간의 multimodal 데이터로 구성되어 있습니다. 총 5개의 세션과 10명의 화자로 구성되어 있으며, 한 세션은 두 명의 독점 화자의 대화로 구성됩니다. 이전 연구와 비교할 수 있도록 ‘화난’, ‘행복’, ‘흥분’, ‘슬픔’, ‘중립’ 에 속하는 레이블만 사용했습니다. 각 감정 클래스의 크기 균형을 맞추기 위해 ‘행복’과 ‘흥분’ 클래스를 병합하여 총 5,531개의 발화(행복 1636, 화남 1103, 슬픔 1084, 중립 1708)를 산출했습니다.
leave-one-session-out 5-fold cross validation (CV) is used and the average result reported. At each fold of the 5-fold CV setup, 2 speakers are used for testing and the samples from the 8 speakers remaining are randomly split into 80% for training and 20% for validation. The splitting done here is exactly the same as the one done by SUPERB [18], which splits each of the 5 IEMOCAP folds into three subsets: a training-set, a validation-set and a test-set.
The fine-tuning of our Upstream model is performed by training it jointly with a simple Mean-Average Pooling Network followed by a Linear Classifier, as described in Figure 2.
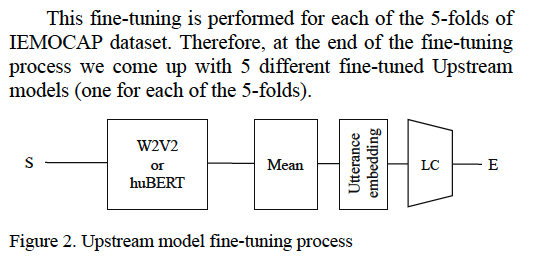
Fine-tuning of the upstream models
SER 시스템을 향상 시키기 위해 섹션에서 설명된 IEMOCAP 데이터 세트의 범주형 감정레이블을 사용하여 Upstream model을 미세 조정 하였습니다. 이 미세조정은 5 fold의 IEMOCAP dataset 각각에 대해 수행됩니다. 따라서 미세조정 프로세스가 끝나면 5개의 서로 다른 fune tuned 된 upstream model이 세션별로 생성됩니다. 2.1 Upstream model의 미세조정은 그림2에 설명된 대로 간단한 average pooling network와 Linear Classifier를 함께 훈련하여 수행합니다.
Average of checkpoints
- 딥 러닝의 맥락에서 체크포인트는 학습 중 특정 시점의 모델 매개변수(wieght and bias)에 대한 스냅샷입니다. 체크포인트는 일반적으로 훈련 중에 주기적으로 저장되며, 특정 시점부터 훈련을 재개하거나 유효성 검사 세트에서 모델의 성능을 평가하는 데 사용할 수 있습니다.
- 논문에 설명된 SER 시스템에서 저자는 체크포인트를 사용하여 훈련 중에 미세 조정된 업스트림 모델의 성능을 추적합니다. 구체적으로는 미세 조정된 업스트림 모델의 정확도를 기준으로 IEMOCAP 데이터 세트의 5배수 각각에 대해 최고의 체크포인트 5개를 유효성 검사 등 각종 세트에 저장합니다. 이러한 체크포인트는 모델 파라미터의 평균을 계산하는 데 사용되며, 이는 업스트림 모델의 출력 분산을 줄이고 SER 시스템의 전반적인 성능을 개선하는 데 도움이 됩니다.
- why should output variance be minimized?
- SER 시스템의 맥락에서 업스트림 모델의 출력 분산을 최소화하는 것은 시스템의 전반적인 성능을 개선하는 데 도움이 되기 때문에 중요합니다. 출력 분산은 동일한 입력 음성 신호가 주어졌을 때 업스트림 모델에서 생성되는 출력 특징의 변동성을 나타냅니다. 출력 분산이 높으면 다운스트림 모델이 수신하는 특징이 일관되지 않거나 노이즈가 있을 수 있으므로 입력 음성 신호를 정확하게 분류하기가 더 어려워질 수 있습니다.
- 미세 조정된 업스트림 모델의 체크포인트를 평균화함으로써 작성자는 모델의 출력 분산을 줄이고 다운스트림 모델에서 작업할 수 있는 보다 일관되고 신뢰할 수 있는 특징을 생성할 수 있습니다. 이를 통해 SER 시스템의 전반적인 정확도와 견고성을 개선하고 다양한 음성 신호와 다양한 맥락에서 우수한 성능을 발휘할 수 있습니다.
- why did they use W2V2 and huBert both in Upstream model?
- 이 논문의 저자들은 SER 시스템의 업스트림 모델에 Wav2vec 2.0(W2V2)과 huBERT를 모두 사용했는데, 이는 사전 학습된 다양한 모델을 결합하여 시스템의 성능을 향상시킬 수 있는 방법을 모색하기 위해서였습니다. W2V2와 huBERT는 모두 음성 처리를 위해 사전 학습된 최첨단 모델이며 다양한 음성 작업에서 우수한 성능을 발휘하는 것으로 나타났습니다.
- 업스트림 모델에 두 모델을 모두 사용함으로써 저자들은 각 모델의 강점을 활용하고 다운스트림 모델에서 작업할 수 있는 더욱 강력하고 정확한 기능을 생성할 수 있었습니다. 특히 W2V2는 음성 신호의 문맥화된 표현을 추출하도록 설계된 반면, huBERT는 화자별 표현을 추출하도록 설계되었습니다. 이 두 모델을 결합함으로써 저자들은 입력 음성 신호의 문맥 정보와 화자별 정보를 모두 포착하는 특징을 생성할 수 있었고, 이는 SER 시스템의 전반적인 성능을 개선하는 데 도움이 되었습니다.
Experimental Setup
Experiment for evaluation
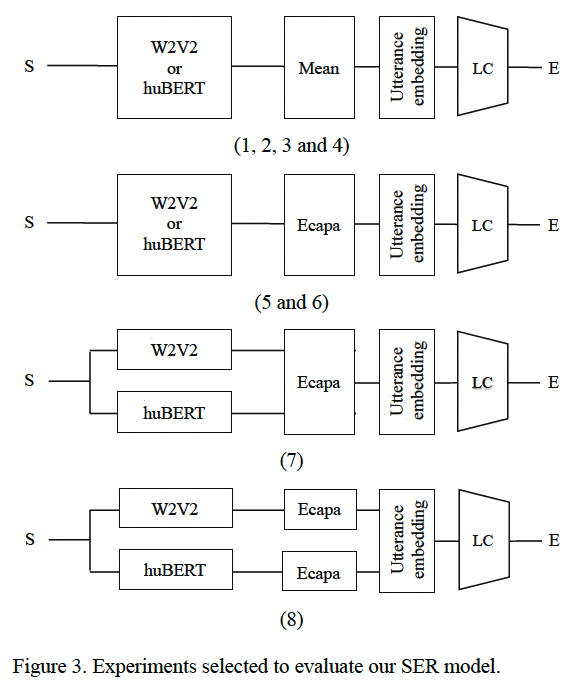
SER 모델을 사용하여 수행할 수 있는 여러 실험 중에서 그림3과 표 1의 (1.A), (1.B) 세트에 설명된 실험을 선택했습니다.
이 실험의 목표는 다음과 같습니다: (1) the importance of fine-tuning the Upstream model; (2) the importance of averaging the Upstream and Downstream Model Checkpoints; (3) how Wav2vec 2.0 and huBERT can be combined to boost SER performance and (4) the performance of the two aggregators used: Mean Pooling and ECAPA-TDNN.
- what is aggregator?
- 이 논문에서 설명하는 SER 시스템의 맥락에서 aggregator는 다운스트림 모델의 구성 요소로, 업스트림 모델의 출력 특징을 감정 인식을 위한 최종 분류기에 입력할 수 있는 단일 특징 벡터로 결합하는 역할을 담당합니다.
- 업스트림 모델은 입력 음성 신호에서 feature를 추출하는 사전 학습된 모델입니다. 그런 다음 이러한 feature는 aggregator로 전달되어 감정 인식 작업을 위해 입력 음성 신호에 대한 가장 중요한 정보를 캡처하는 single feature vector로 결합됩니다.
- SER 시스템에서 사용할 수 있는 aggregator에는 평균 풀링과 ECAPA-TDNN 등 다양한 유형이 있습니다. 서로 다른 유형의 입력 특징 또는 서로 다른 유형의 음성 신호에 더 적합한 aggregator가 있을 수 있으므로 aggregator 선택이 시스템 성능에 영향을 미칠 수 있습니다.
- 전반적으로 aggregator는 다운스트림 모델이 작업할 수 있는 강력하고 정확한 특징 벡터를 생성하는 데 도움을 줌으로써 SER 시스템에서 중요한 역할을 합니다.
Fig3에 의하면, 실험(1-4)에서 사용된 Upstream model used is either Wav2vec 2.0 or huBERT and the Downstream model is composed by a Mean Average Aggregator followed by a linear classifier.
(1-2)의 실험에서는 업스트림 모델과 다운스트림 모델 모두 평균화 하지 않았습니다.
(3-4)의 실험에서는 업스트림 모델과 다운스트림 모델 모두 평균을 냈습니다.
실험(5-6)과 (3-4)는 유사하며 유일한 차이점은 사용된 aggregator인 ECAPA-TDNN이 사용된 것입니다.
Experiment 7 and 8 in the paper describe different types of feature fusion that were used to combine the output features of the Wav2vec 2.0 and huBERT models in the Upstream component of the SER system.
실험(7)에서는 ECAPA-TDNN aggregator를 통과 하기 직전에 W2V2과 huBERT 기능 간의 early fusion을 수행합니다.
In Experiment 7, the authors used early fusion to combine the output features of the Wav2vec 2.0 and huBERT models. Early fusion involves combining the input features from two different modalities (in this case, speech and text) before they are processed by the Upstream models. Specifically, the authors concatenated the output features of the two models before passing them through the ECAPA-TDNN aggregator.
실험(8)에서는 두개의 ECAPA-TDNN이 생성한 utterance embedding을 나중에 융합했는데, 첫번째는 W2V2 가능에서 작동하고 두번째는 huBERT기능에서 작동합니다.
In Experiment 8, the authors used later fusion to combine the output features of the Wav2vec 2.0 and huBERT models. Later fusion involves combining the output features of the two models after they have been processed by the Upstream models. Specifically, the authors used two separate ECAPA-TDNN aggregators to process the output features of the two models, and then concatenated the resulting feature vectors before passing them through the final classifier.
Fusion refers to the process of combining information from multiple sources to produce a single output. In the context of the SER system described in the paper, fusion is used to combine the output features of the Wav2vec 2.0 and huBERT models in order to produce a more robust and accurate feature vector for the Downstream model to work with. By combining the strengths of the two models, the authors were able to improve the overall performance of the SER system.
Experiments to be used as baselines
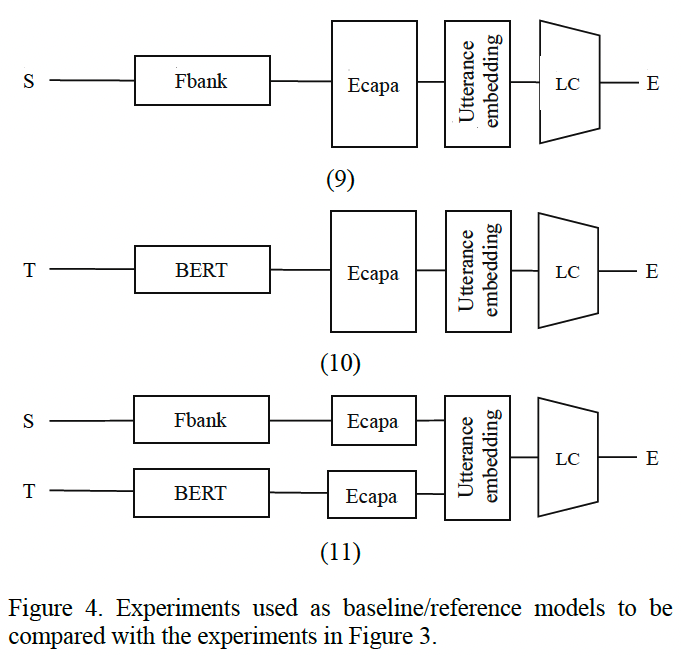
Fig 3 실험과 비교하기 위한 base line으로 음성 피처는 Fbank, 텍스트는 BERT를 사용하였습니다.
실험(9)에서는 표준 필터 뱅크가 업스트림모델로 사용되고 실험(10)에서는 BERT 모델이 업스트림 모델로 사용됩니다. 실험 (11)에서는 음성에서는 Fbank, 텍스트 feature는 BERT를 사용하여 later fusion fashion 방식으로 사용됩니다.
It is important to emphasize that the Fbank used here does not have explicit pitch information attached to it and that the fine-tuning optimization process of the BERT model may not follow the most advanced SOTA techniques available nowadays. However, despite not being as carefully prepared as it could be, these baseline models can help us to obtain insight on how powerful these fine-tuned and averaged Wav2vec 2.0 and huBERT features are.
RESULTS
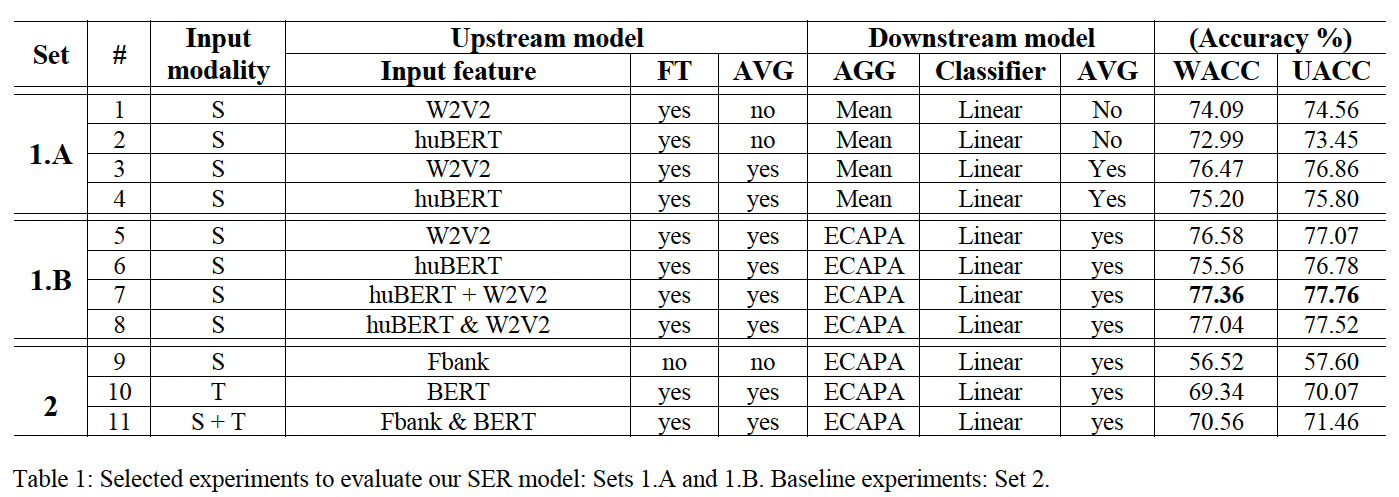
표 설명: In column 2 of Table 1, under the term (#), we indicate the number of the 11 experiments evaluated. In column 3 we indicate the input modality used in each experiment. In column 4 under the term Upstream model we can find the indication of the Input feature; if the Upstream model has been fine-tuned (FT); and if the Upstream model has been Averaged (AVG). The symbol “+” in experiment 7 (huBERT + W2V2) indicates early fusion of the features and the symbol “&” in the experiments 8 and 11 indicates later fusion of the features. In column 5 under the term Downstream model we can find the indication of the Aggregator Model used (AGG); the Classification Model (Classifier) used; and if the full Downstream Model has been averaged (AVG). Since the test sets of IEMOCAP are slightly imbalanced between different emotion categories, in column 6 of Table 1 under the term Accuracy we report both Weighted Accuracy (WACC) and Unweighted Accuracy (UACC). Finally, in column 1 of Table 1 under the term SET we have: in (1.A) the subset of experiments from Figure 3 that use Mean Pooling as Aggregator; in (1.B) the subset of experiments from Figure 3 that use ECAPA-TDNN as Aggregator and in (2) the baseline experiments described in Figure 4.