Course
Data Label
Collecting Data

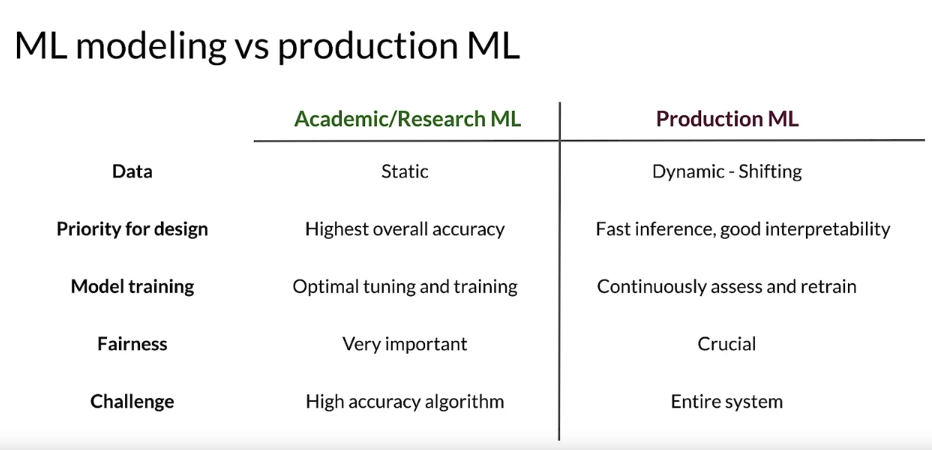
- You need to make sure that your data covers the same region of your feature space as the prediction request that you’ll get your training data and you want to make sure that you’ve really maximize the predictive signal in that data. And you need to worry about the data quality not just at the beginning but throughout the life of the application. So part of that is making sure that your sourcing data responsibly and you’re thinking about things like bias and fairness.
- One of the key aspects of collecting data is to make sure that you’re collecting it responsibly and paying attention to things like security, privacy and fairness.
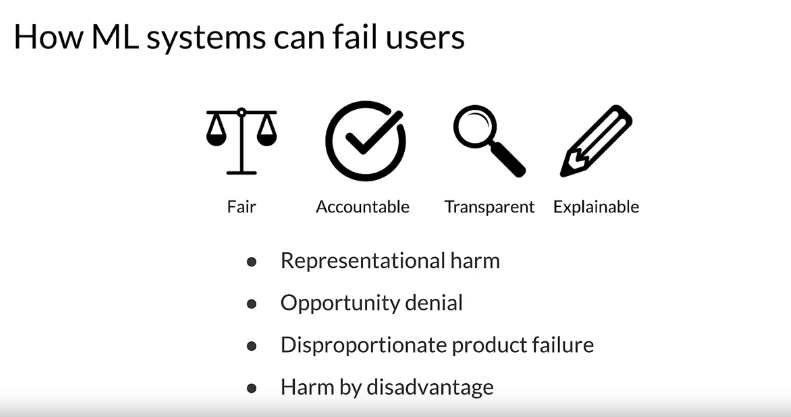

- key points, first of all, always account for fair Raters and fair representation in your data set to avoid potential biases. And take into account who those labelers are and what their incentives are, because if you design the incentives incorrectly, you could get a lot of garbage in your data. The cost is certainly always going to be an important consideration. So if you can find a way to do it with a high level of quality but at less cost, that’s great. But you need enough data. You need to find a way to do that. It’s one of the challenges of production applications and finally data freshness too. You’re going to be working with data and depending on how the world changes around the application and the data that you have, you’re going to need to refresh that data on some regular basis and detect when you need to do that. So those are all issues you need to think about to really manage collection of data and to do it in a responsible way.
Labeling Data





- The key points of what we’re talking about here, model performance decays over time. It may decay slowly over time, in things like cats and dogs, that doesn’t change very quickly, or it may change very fast, things like markets. Model retraining will help you improve or maintain your performance. Certainly as your model performance decays, it’ll help you do that. Data labeling, assuming you’re doing supervised learning, which is pretty common, data labeling is a key part of that. You really need to think about how you’re going to approach that in your particular problem, in your particular domain and with the systems that you have available to you.
Validating Data

- Just to wrap up, this week, you saw differences between ML modeling in academic or research environments and production ML systems. We discussed responsible data collection and how to really approach building a fair production ML system. We learned about process feedback and direct labeling and also human labeling. We looked at some of the issues that you can have with data and how to identify and detect those issues.
Feature
Preprocessing
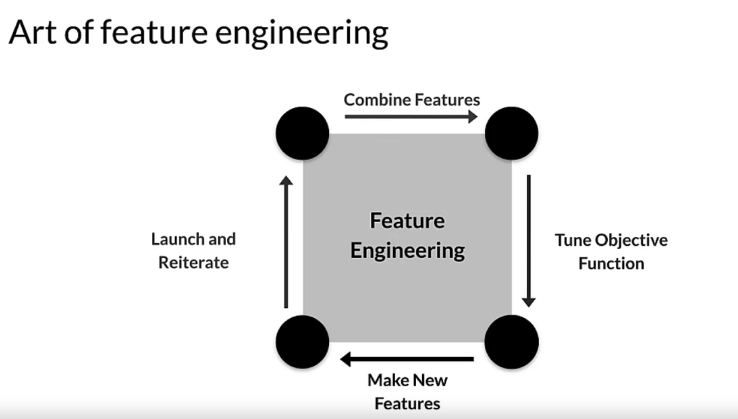
- The art of feature engineering tries to improve your model’s ability to learn while reducing if possible, the compute resources it requires, it does this by transforming and projecting, eliminating and or combining the features in your raw data to form a new version of your data set. So typically across the ML pipeline, you incorporate the original features often transformed or projected to a new space and or combinations of your features. Objective function must be properly tuned to make sure your model is heading in the right direction and that is consistent with your feature engineering. You can also update your model by adding new features from the set of data that is available to you unlike many things in ML, this tends to be an iterative process that gradually improves your results as you iterate or you hope it does. You have to monitor that and if it’s not improving, maybe back up and take another approach.

- To review some key points, as the quote from Andrew Ng demonstrates, feature engineering can be very difficult and time consuming but it is also very important to success. You want to squeeze the most out of your data and you do that using feature engineering, by doing that, you enable your models to learn better. You also want to make sure that you concentrate predictive information, your data into as few features as possible to make the best and least expensive use of your compute resources. And you need to make sure that you apply the same feature engineering during serving as you applied during training.
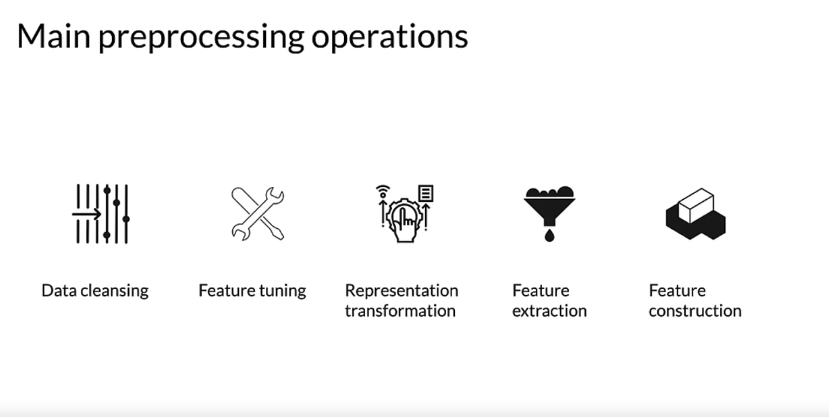
- Here’s some of the main Preprocessing Operation. One of the most important Preprocessing Operations is Data cleansing, which in broad terms consists in eliminating or correcting erroneous data. You’ll often need to perform transformations on your data, so scaling or normalizing your numeric values, for example. Since models, especially neural networks, are sensitive to the amplitude or range of numerical features, data preprocessing helps Machine Learning build better predictive Models. Dimensionality reduction involves reducing the number of features by creating lower dimension and more robust data represents. Feature construction can be used to create new features by using several different techniques, which we’ll talk about some of them.

- Key points. Data preprocessing is a technique that’s used to transform raw data into useful data for training the Model. Feature Engineering consists in mapping raw input data and creating a feature vector from it using different techniques with different kinds of data. It can also include things like mapping data from one space into a different space, which depending on the characteristics of a Model, say a linear Model versus a neural network can have a big difference in how well the Model can learn from it.
feature engineering

- Key points for this particular section, feature engineering. It’s going to prepare and tune and transform and extract and construct features where we’re going to work with features and change them starting with our raw data through to the data that we’re going to give to our model. Feature engineering is very important for model refinement. Really, it can make the difference between successfully modeling something and not. Feature engineering really helps with ML Analysis and really developing that intuitive understanding of our data.
feature crosses

- What are Feature crosses? Well, they combine multiple features together into a new feature. That’s fundamentally what a feature across. It encodes non-linearity in the feature space, or encodes the same information and fewer features. We can create many different kinds of feature crosses and it really depends on our data.
- Feature Crossing as a way to create synthetic features, often encoding non-linearity in the features space. We’re going to transform both categorical and numerical. We could do that in, into either continuous variables or the other way around.
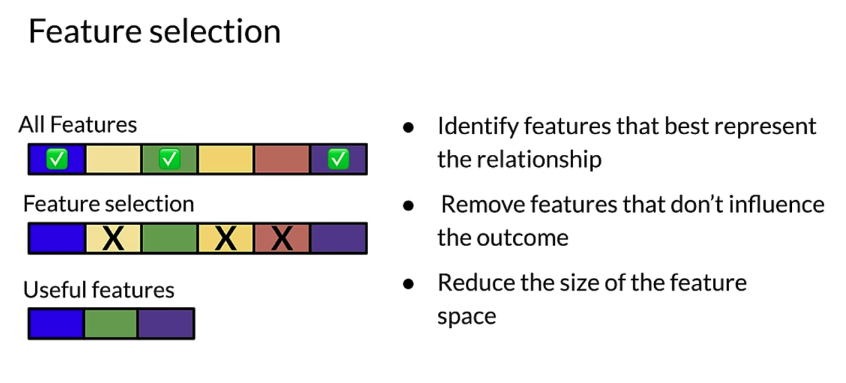
Feature selection
- feature space: a feature space is defined by the n dimensional space that your features defined. So if you have two features, a feature space is two dimensional. If you have three features, its three dimensional and so forth, it does not include the target label.


filter methods
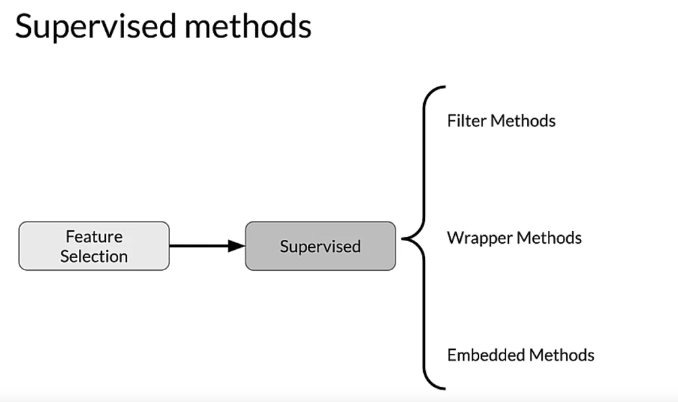
- for filter methods, we’re primarily using correlation to look for the features that contain the information that we’re going to use to predict our target.

- we are going to start with all of the features and we’re going to select the best subset and we’re going to give those to our model and that’s going to give us our performance for the model with this subset of our features.
wrapper method
- It stores supervised method, but we’re going to use this with a model and there’s different ways to do it. But basically you’re iterating through, it’s a search method against the features that you have using a model as the measure of their effectiveness. We can do it through forward elimination and we’ll talk about this in a second. Forward elimination, backward elimination or recurrent feature elimination.
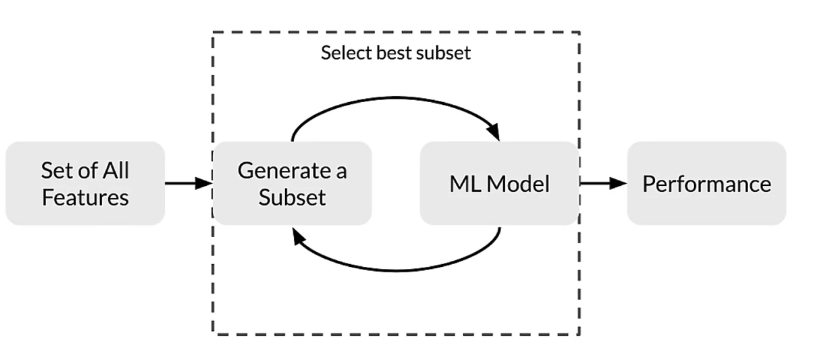
- We start with all of our feature, regenerate a subset of those features, and we’ll talk about how that gets generated, that gets given to our model. The results that is generated from that model is then used to generate the next subset. That becomes this feedback loop to select the best subset of our features using our model as a measure. That gives us the performance of the final best subset that is selected.
Embedded method(feature importance)
- L1 or L2 regularization is essentially an embedded method for doing feature selection. Feature importance is another method. Both of these are highly connected to the model that you’re using. So these both L1 regularization and feature importance really sort of an intrinsic characteristic of the model that you’re working with.\
Data Storage
MLMD(ML meta data)
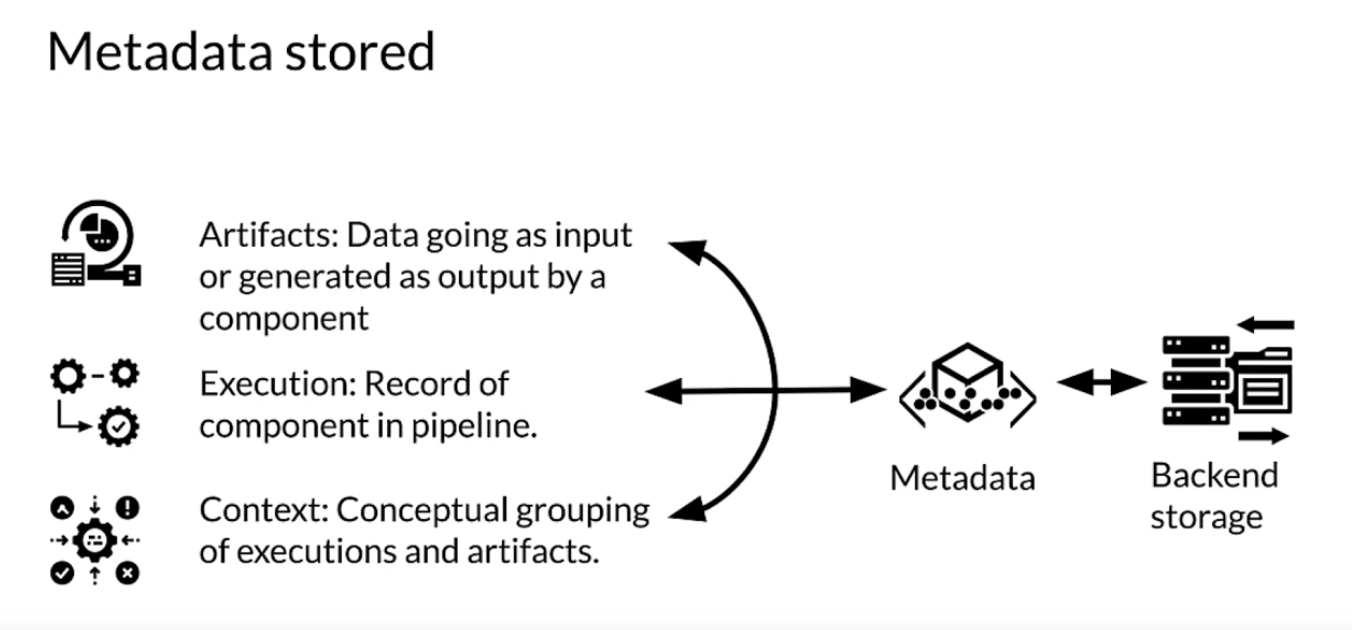
- ML metadata stores a wide range of information about the results of the components and execution runs of a pipeline.

- You learned a lot about the architecture and nomenclature of ML metadata or MLMD and the artifacts and entities which it contains. This should give you some idea of how you can leverage MLMD to track metadata and the results flowing through your pipeline to better understand your training process, both now and in previous training runs of your pipeline.
Data Warehouse
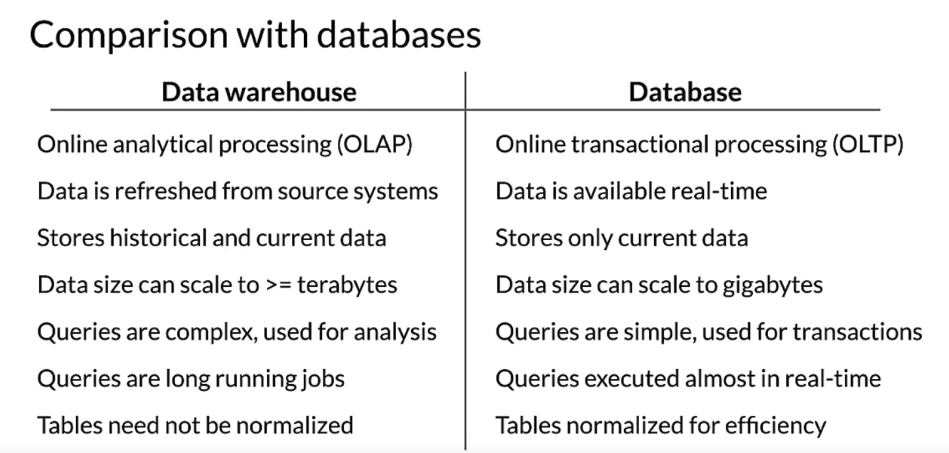
- Data warehouses are meant for analyzing data, whereas databases are often used for transaction purposes. Inside a data warehouse, there may be a delay between storing the data and the data getting reflected in the system. But in a database, data is usually available immediately after it’s stored. Data warehouses store data as a function of time, and therefore, historical data is also available. Data warehouses are typically capable of storing a larger amount of data compared to databases. Queries in data warehouses are complex in nature and tend to run for a long time. Whereas queries in database are simple and tend to run in real time. Normalization is not necessary for data warehouses, but it should be used with databases.
Data Lake
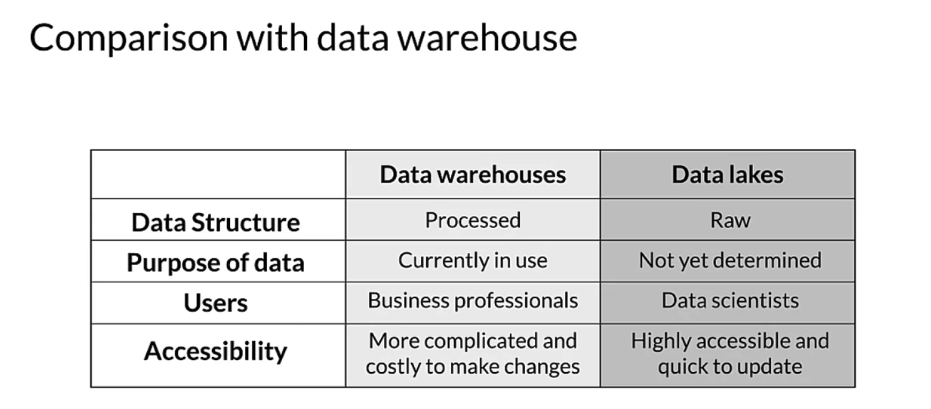
- The primary difference between them is that in a data warehouse, data is stored in a consistent format which follows a schema, whereas in data lakes, the data is usually in its raw format. In data lakes, the reason for storing the data is often not determined ahead of time. This is usually not the case for a data warehouse, where it’s usually stored for a particular purpose. Data warehouses are often used by business professionals as well, whereas data lakes are typically used only by data professionals such as data scientists. Since the data in data warehouses is stored in a consistent format, changes to the data can be complex and costly. Data lakes however are more flexible, and make it easier to make changes to the data.
