Journal/Conference : IEEE/ACM Transactions on Audio, Speech, and Language Processing
Year(published year): 2022
Author: Cheng Lu , Yuan Zong , Member, IEEE, Wenming Zheng , Senior Member, IEEE, Yang Li , Member, IEEE, Chuangao Tang , and Björn W. Schuller , Fellow, IEEE
Subject: Domain Invariant Feature Learning(DIFL), Speech Emotion Recognition(SER)
Domain Invariant Feature Learning for Speaker-Independent Speech Emotion Recognition
Summary
- 멀티소스 UDA를 수행하기 위한 간단하면서도 효과적인 도메인 불변 학습 프레임워크를 제안합니다. 우리가 아는 한, 멀티 소스 UDA의 관점에서 화자 독립적 SER을 다룬 연구는 이번이 처음입니다.
We propose a simple, yet effective domain-invariant learning framework to carry out multi-source UDA. To the best of our knowledge, this is the first study dealing with speaker-independent SER from the perspective of multi-source UDA.
- 화자의 정체성과 감정의 혼동을 제거하기 위해 특징 추출기 블록에 계층적 분포 정렬 방법을 제안하고, 계층적 정렬 계층에 포함된 강-약 정렬 전략을 활용하여 로컬 및 글로벌 특징에 대해 각각 강-약 정렬을 구현합니다.
We propose a hierarchical distribution alignment method in the feature extractor block to remove the confusion of speakers’ identity and emotion, in which a strong-weak alignment strategy embedded in hierarchical alignment layers is utilized to realize the strong and weak alignment for local and global features, respectively.
- 화자 독립적 SER에 대한 도메인 불변 특징을 추가로 학습하기 위해 다중 판별자를 도입하여 도메인 판별자와 화자 판별자를 사용하여 화자 불변 특징을 얻고 레이블 판별자를 사용하여 감정과 관련된 판별 특징을 얻습니다.
We introduce multiple discriminators to further learn domain invariant features for the speaker-independent SER, in which the domain discriminator and speaker discriminator are used to obtain speaker-invariant features while the label discriminator is used to obtain discriminative features that are emotion-related.
I. Introduction
DIFL의 정의
- 도메인 불변 특징 학습(DIFL)은 화자 독립적인 음성 감정 인식을 다루기 위해 “화자 독립적인 음성 감정 인식을 위한 도메인 불변 특징 학습” 논문에서 제안된 방법입니다. DIFL의 기본 아이디어는 다중 소스 비지도 도메인 적응(multi-source unsupervised domain adaptation, UDA)의 관점에서 화자가 달라서 발생하는 훈련 데이터와 테스트 데이터 간의 도메인 이동을 제거하여 화자 불변 감정 특징을 학습하는 것(learn speaker invariant emotion feature)입니다.
multi-source UDA의 정의
다중 소스 비지도 도메인 적응(UDA)은 하나 이상의 소스 도메인에서 학습된 모델을 레이블이 지정된 데이터가 부족하거나 사용할 수 없는 대상 도메인에 적응시키기 위해 머신 러닝에 사용되는 기법입니다. 다중 소스 UDA에서는 모델이 여러 소스 도메인에서 동시에 학습되며, 목표는 대상 도메인에 잘 일반화할 수 있는 도메인 불변형 표현을 학습하는 것입니다. 이 기법은 여러 소스의 데이터가 서로 다른 분포와 특성을 가질 수 있는 복잡한 실제 시나리오를 다룰 때 특히 유용합니다.
다중 소스 비지도 도메인 적응은 전이 학습의 한 유형입니다. 전이 학습은 하나 이상의 소스 도메인에서 학습한 지식을 목표 도메인으로 옮기는 과정을 말합니다. 다중 소스 UDA에서는 여러 소스 도메인에서 학습한 지식을 목표 도메인으로 전송하여 목표 작업에서 모델의 성능을 개선합니다. 관련 도메인의 지식을 활용함으로써 모델이 보이지 않는 새로운 데이터에 더 잘 적응할 수 있는 보다 일반화 가능한 표현을 학습할 수 있다는 것이 이 아이디어의 핵심입니다.
→ 그러니까 이 논문에서 소스 도메인에서 타겟 도메인으로 넘어가는 과정의 화자와 관련된 특성을 제거시켜서 감정 인식이 더 잘되게 하는 방법을 제안하였음.
UDA의 정의
- 다중 소스 UDA는 비지도 도메인 적응 모델의 한 유형입니다. 비지도 도메인 적응은 대상 도메인의 레이블이 지정된 데이터를 사용하지 않고 소스 도메인에서 학습된 모델을 레이블이 지정된 데이터가 부족하거나 사용할 수 없는 대상 도메인에 적응시키는 프로세스를 말합니다. 목표는 공유된 특징 공간에서 소스 도메인과 대상 도메인의 분포를 정렬하여 대상 도메인에 잘 일반화할 수 있는 도메인 불변 표현을 학습하는 것입니다. 이는 일반적으로 공유 특징 공간에서 소스 도메인과 대상 도메인 간의 거리 또는 불일치를 최소화하면서 당면한 작업에 대한 판별 정보를 보존함으로써 달성할 수 있습니다. 다중 소스 UDA는 이 아이디어를 여러 소스 도메인으로 확장하여 모델이 대상 도메인에 잘 일반화하면서 동시에 여러 다른 소스 도메인에 적응하는 방법을 학습합니다.
- 비지도 도메인 적응은 머신 러닝에서 한 도메인에서 학습된 모델을 레이블이 지정된 데이터가 부족하거나 사용할 수 없는 다른 도메인에 적응시키는 데 사용되는 기법입니다. 목표는 공유된 특징 공간에서 소스 도메인과 대상 도메인의 분포를 정렬하여 대상 도메인에 잘 일반화할 수 있는 표현을 학습하는 것입니다. 다중 소스 UDA는 이 아이디어를 여러 소스 도메인으로 확장하여 모델이 대상 도메인에 잘 일반화하면서 동시에 여러 다른 소스 도메인에 적응하는 방법을 학습합니다.
→ UDA는 source 도메인에서 학습이 완료된 모델을 target 도메인(데이터가 부족하거나 사용할 수 없는)에 적응시키는데 사용되는 방법. 목표는 source 도메인 모델을 target 도메인이 잘 일반화 시켜서 적응 시키는 것임. multi-source UDA는 이러한 점을 보완하기 위해서 source domain의 개수를 다중으로 만들어 일반화가 더 잘되게 적응 시킴.
II. Related Work
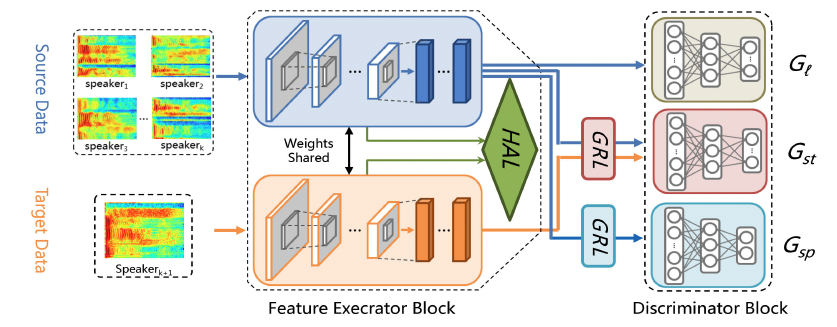
Overview of the Domain Invariant Feature Learning (DIFL) framework for speaker-independent SER, including the feature extractor block with a hierarchical alignment layer (HAL), and the discriminator block with a domain adversarial layer (DAL) consisting of a label discriminator $G_l$, source-target domain discriminator $G_{st}$, and speaker discriminator $G_{sp}$, where the GRL represents the gradient reversal layer.
A. Speaker-Independent SER
- 기존의 연구 방향: (1) feature fusion; (2) classifier enhancement; and (3) speaker normalization.
- feature fusion: The feature fusion category aims to fuse multiple hand-crafted features to obtain a discriminative feature set, which is mostly used in early works.
- classifier enhancement: to enhance the robustness of the classifier to deal with speaker-independent SER, which are usually combined with suited feature fusion based methods.
- speaker normalization: The speaker normalization category mainly utilizes speaker normalization (e. g., mean normalization, cumulative distribution mapping, factor analysis) to reduce the specific variability of speakers during the feature extraction.
B. Multi source UDA
- It mainly focuses on the situation that the source data are collected from multiple different domains [36]. Therefore, multi-source UDA not only considers the domain shift between the source and target domains, but also handles the discrepancy across multiple domains in the source data [36], [37].
- latent space transformation
- The latent space transformation based methods attempt to convert different domain features to a specific latent space, and then use the divergence-based or adversarial-based loss to align the domain shift.
- It is worth noting that the divergence-based methods are non-parametric, only depending on the selection of divergence functions and embedding position in feature layers, while the adversarial-based methods need to learn new parameters of the discriminator. In this paper, we combine these two methods in the DIFL framework to find the optimal balance among their advantages and disadvantages.
- intermediate domain generation
- intermediate domain generation strategy tries to generate the new adapted domain for each domain in the source data, where these new domains are indistinguishable from the target domain. These methods are all based on GANs [44] or auto-encoders [45], e. g., Coupled GAN [46], CycleGAN in MADAN [47], or variational auto-encoder [45], as the generator to generate the intermediate domain from the latent space.
III. Proposed Method
A. Hierarchial Representation for Emotional Speech
감정적 음성을 위한 계층적 표현은 음성 데이터를 계층적 또는 계층적 구조로 표현하는 방식을 말하며, 각 계층은 음성 데이터의 점점 더 추상적이거나 복잡한 특징을 포착합니다. 이러한 계층적 표현은 여러 개의 컨볼루션 블록과 완전 연결(FC) 블록으로 구성된 심층 컨볼루션 신경망(DCNN)을 사용하여 얻을 수 있습니다.
DCNN에서 각 컨볼루션 블록에는 컨볼루션, 일괄 정규화, ReLU 및 MaxPooling 연산이 포함됩니다. 이러한 연산은 음성 데이터에서 로컬 피처를 추출하는 데 사용되며, 이 피처는 fc 블록을 통과하여 특정 작업과 관련성이 높고 변별력이 강한 글로벌 피처를 추출합니다.
소스 데이터와 타깃 데이터의 특징 맵은 각각 소스 데이터의 경우 Cm(Xs)와 Ln(Xs), 타깃 데이터의 경우 Cm(Xt)와 Ln(Xt)로 표현됩니다. 여기서 Xs와 Xt는 각각 소스 도메인과 타깃 도메인의 원시 음성 데이터를 나타내고, Cm과 Ln은 각각 컨볼루션과 fc 블록에서 얻은 특징 맵을 나타냅니다.
계층적 표현을 사용하면 DCNN은 음성 데이터에서 보다 유익하고 차별적인 특징을 추출할 수 있으며, 이를 통해 음성 감정 인식(SER) 모델의 성능을 개선할 수 있습니다. 계층적 표현을 통해 모델은 기존의 수작업 피처로는 포착하기 어려운 복잡하고 미묘한 음성 감정의 변화를 포착할 수 있습니다.
- local feature and global feature
- 딥러닝의 맥락에서 로컬 피처는 처음 몇 개의 컨볼루션 레이어와 같은 신경망의 얕은 레이어에서 입력 데이터에서 추출되는 낮은 수준의 피처를 의미합니다. 이러한 로컬 피처는 가장자리, 모서리, 텍스처와 같은 입력 데이터의 로컬 패턴과 구조를 포착하며 다양한 작업과 도메인에 걸쳐 비교적 강력한 일반화 기능을 제공합니다.
- 반면에 글로벌 피처는 완전 연결(FC) 레이어와 같은 신경망의 심층 레이어에서 입력 데이터에서 추출되는 높은 수준의 피처를 말합니다. 이러한 글로벌 특징은 화자의 신원이나 음성에 표현된 감정 등 입력 데이터의 고차원적인 의미 정보를 포착하며, 특정 작업과 연관성이 높고 변별력이 강합니다.
- 음성 감정 인식(SER)의 맥락에서 감정적 음성의 로컬 특징은 일반적으로 포먼트의 모양과 기본 주파수의 위치와 같은 음성의 저수준 음향 특성을 포착합니다. 이러한 로컬 피처는 음성 데이터의 스펙트로그램에서 추출되며 음성 신호의 로컬 패턴과 구조를 캡처하는 데 사용됩니다.
- 반면에 감정적 음성의 글로벌 특징에는 화자의 신원이나 음성에 표현된 감정과 같은 작업별 의미 정보가 포함됩니다. 이러한 글로벌 특징은 DCNN의 FC 레이어에서 추출되며 음성 신호 2의 높은 수준의 의미 정보를 캡처하는 데 사용됩니다.
- 저수준 특징과 고수준 특징의 정렬을 결합함으로써 DCNN은 화자 독립적 SER에서 서로 다른 화자와 감정 표현의 혼동 문제를 처리하고 SER 모델 의 성능을 향상시킬 수 있습니다.
- 이 논문의 저자는 음성의 감정적 표현을 포착하기 위해 로컬 및 글로벌 특징을 모두 사용합니다. 로컬 피처는 음성 데이터의 스펙트로그램에서 추출되며 포먼트의 모양과 기본 주파수의 위치 등 음성의 저수준 음향 특성을 포착합니다. 이러한 로컬 특징은 일반적이며 다양한 작업과 도메인에 걸쳐 비교적 강력한 일반화 특성을 갖습니다.
- 반면에 글로벌 특징에는 화자의 신원이나 음성에 표현된 감정과 같은 작업별 의미 정보가 포함되어 있습니다. 이러한 글로벌 특징은 DCNN의 FC 계층에서 추출되며 음성 신호의 높은 수준의 의미 정보를 캡처합니다. 글로벌 특징은 특정 작업과 관련이 높고 변별력이 강합니다.
- 저수준 특징과 고수준 특징의 정렬을 결합함으로써 DCNN은 화자 독립적 SER에서 다양한 화자와 감정 표현의 혼동 문제를 처리하고 SER 모델의 성능을 향상시킬 수 있습니다. 로컬 및 글로벌 피처를 모두 사용하여 얻은 감정적 음성의 계층적 표현을 통해 모델은 기존의 수작업 피처로는 포착하기 어려운 복잡하고 미묘한 음성 감정의 변화를 포착할 수 있습니다.
B. Hierarchical Alignment Layer (HAL)
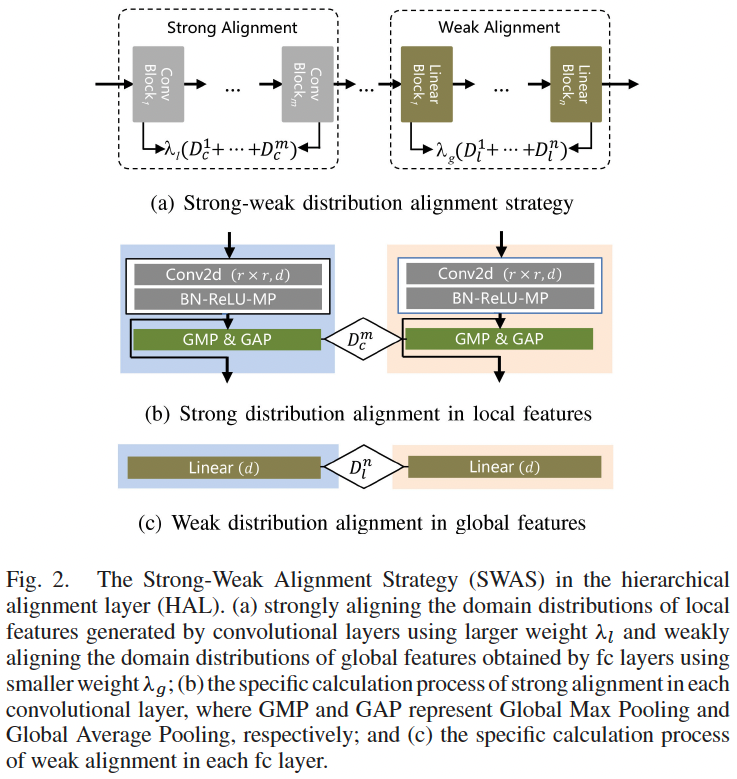
hierarchical representation을 얻을때 먼저 훈련 데이터 셋과 테스트 데이터 셋 간에 서로 다른 화자로 인해 발생하는 도메인 이동을 제거하는걸 고려해야 합니다. 이를 위해 hierarchical alignment layer(HAL)을 제안합니다.
HAL은 소스 데이터와 대상 데이터의 특징 맵을 계층적 방식으로 정렬하는 방식으로 작동합니다. 특징 맵은 각각 음성 데이터에서 로컬 및 글로벌 특징을 추출하는 DCNN의 컨볼루션 및 완전 연결(FC) 블록에서 얻습니다. 피처 맵의 계층적 정렬을 통해 모델은 기존의 수작업 피처로는 포착하기 어려운 복잡하고 미묘한 음성 감정의 변화를 포착할 수 있습니다.
HAL은 화자 독립적 SER을 위한 도메인 불변 특징 학습을 위해 제안된 방법의 핵심 구성 요소 중 하나입니다. 계층적 표현과 도메인 적대적 학습을 사용하여 제안된 방법은 소스 도메인과 타겟 도메인 간의 도메인 격차를 효과적으로 줄이고 SER 모델의 성능을 향상시킬 수 있습니다.
HAL은 SWAS(강약 정렬 전략)를 사용하여 로컬 및 글로벌 특징의 정렬을 강화하고 음성 특징의 감정 변별력을 보장합니다. SWAS는 서로 다른 가중치를 사용하여 로컬 피처는 강하게 정렬하고 글로벌 피처는 약하게 정렬합니다.
특히 강력한 특징 분포 정렬에서 스펙트로그램은 컨볼루션 레이어를 통해 로컬 특징을 얻는데, 이는 대부분 포먼트와 에너지 분포(즉, 이미지의 가장자리, 모양, 색상)의 에지 또는 모양 설명입니다. 이러한 로컬 특징은 훈련 데이터 세트와 테스트 데이터 세트 간에 서로 다른 화자로 인해 발생하는 도메인 이동을 줄이기 위해 강력하게 정렬됩니다.
약한 특징 분포 정렬에서 DCNN의 FC 레이어는 특정 작업과 관련이 높고 변별력이 강한 전역 특징을 얻습니다. 이러한 글로벌 특징은 작업별 정보를 보존하고 작업별 정보의 손실로 이어질 수 있는 과도한 정렬을 피하기 위해 약하게 정렬됩니다.
로컬 특징과 글로벌 특징의 강-약 정렬을 결합함으로써 SWAS는 HAL의 정렬을 강화하고 SER 모델의 성능을 향상시킬 수 있습니다. 또한 제안된 강-약 정렬 전략을 사용하여 화자 독립적 SER의 성능을 향상시킬 수 있습니다.
In the proposed Strong-Weak Alignment Strategy (SWAS), the strong alignment is applied to the local features obtained from the convolutional layers, while the weak alignment is applied to the global features obtained from the fully connected (fc) layers.
The strong alignment is achieved by aligning the domain distributions of local features generated by convolutional layers using a larger weight λl. The specific calculation process of strong alignment in each convolutional layer is shown in Fig. 2(b) of the paper. The strong alignment process involves applying global max pooling (GMP) and global average pooling (GAP) to the local features and then using a weighted sum of the two pooling results to obtain the aligned features.
On the other hand, the weak alignment is achieved by aligning the domain distributions of global features obtained by fc layers using a smaller weight λg. The specific calculation process of weak alignment in each fc layer is shown in Fig. 3(c) of the paper. The weak alignment process involves applying a domain adversarial loss to the global features to encourage the model to learn domain-invariant representations.
By using different weights for strong and weak alignment, SWAS can effectively align the local and global features and improve the performance of the SER model. The proposed SWAS can also reduce the domain shift caused by different speakers between the training and testing datasets and improve the generalization ability of the SER model.
C. Domain Adversarial Layer(DAL)
What is divergence?
발산은 두 확률 분포 간의 차이를 정량화하는 통계적 척도입니다. 비지도 도메인 적응(UDA)의 맥락에서 발산 측정값은 소스 도메인과 대상 도메인 간의 분포 불일치를 평가하고 두 도메인의 특징 공간 정렬을 안내하는 데 사용할 수 있습니다.
page 3에서 언급한 것처럼 최대 평균 불일치(MMD), 레니-발산, L2 거리, 모멘트 거리 등 UDA에서 사용할 수 있는 다양한 유형의 발산 측정값이 있습니다. 이러한 발산 측정값은 소스 도메인과 대상 도메인의 특징 분포 간의 불일치를 측정하고 두 도메인의 특징 공간 정렬을 유도하는 데 사용할 수 있습니다.
그러나 page 4에서 언급했듯이 발산 함수의 선택은 민감할 수 있으며 복잡하고 미묘한 음성 감정의 변화를 처리하기에 충분히 강력하지 않을 수 있습니다. 따라서 화자 독립적 음성 감정 인식(SER)에서 UDA를 위한 보다 효과적이고 강력한 솔루션으로 도메인 적대적 학습(DAL)과 같은 적대적 기반 UDA 방법이 제안되고 있습니다. DAL은 도메인 분류기를 훈련시켜 소스 도메인과 대상 도메인을 구분하는 동시에 특징 추출기를 훈련시켜 도메인 분류기를 속이는 도메인 불변 표현을 생성하는 과정을 포함합니다. 본 논문에서 제안한 방법은 DAL을 사용하여 소스 도메인과 타겟 도메인 간의 도메인 갭을 효과적으로 줄이고 SER 모델의 성능을 향상시킬 수 있습니다.
What is divergency based UDA?
2에 따르면 발산 기반 UDA는 발산 측정값을 활용하여 소스 도메인과 타겟 도메인 간의 불일치를 평가하는 비지도 도메인 적응(UDA) 방법의 한 유형을 말합니다. 발산 측정값은 두 확률 분포 간의 차이를 정량화하는 통계적 측정값입니다. UDA의 맥락에서 발산 측정값은 소스 도메인과 대상 도메인 간의 분포 불일치를 측정하고 두 도메인의 특징 공간의 정렬을 안내하는 데 사용할 수 있습니다.
화자 독립적 음성 감정 인식(SER)의 경우, 발산 기반 UDA 방법을 사용하여 소스 도메인과 목표 도메인의 특징 공간을 정렬하고 훈련 데이터 세트와 테스트 데이터 세트 간에 서로 다른 화자로 인해 발생하는 도메인 이동을 줄였습니다. 그러나 5에서 언급했듯이 발산 기반 UDA 방법은 발산 함수의 선택에 민감할 수 있으며 복잡하고 미묘한 음성 감정의 변화를 처리하기에 충분히 강력하지 않을 수 있습니다.
이 문제를 해결하기 위해 이 논문에서 제안한 방법에서는 도메인 적대적 학습(DAL)과 같은 적대적 기반 UDA 방법을 사용하여 화자 독립적 SER을 위한 보다 강력하고 효과적인 솔루션을 제공합니다. DAL은 도메인 분류기를 훈련시켜 소스 도메인과 대상 도메인을 구분하는 동시에 특징 추출기를 훈련시켜 도메인 분류기를 속이는 도메인 불변 표현을 생성하는 적대적 훈련의 일종입니다. 제안한 방법은 DAL을 사용하여 소스 도메인과 타겟 도메인 간의 도메인 갭을 효과적으로 줄이고 SER 모델의 성능을 향상시킬 수 있습니다.
Why HAL is problem using in divergency based UDA?
5에 따르면, HAL은 발산 기반 UDA를 기반으로 하며 다양한 메트릭 학습 전략을 사용하여 소스 도메인과 대상 도메인 간의 특징 분포 불일치를 측정하려고 시도합니다. 그러나 서로 다른 도메인에서 공통 정렬 공간을 설정하는 것은 선택된 발산 함수에 따라 달라지기 때문에 이 특징 공간은 많은 제약이 있고 견고성이 부족합니다.
즉, 발산 기반 UDA에서 HAL을 사용할 때의 문제점은 소스 도메인과 대상 도메인 간의 특징 분포 불일치를 측정하기 위해 통계적 가설과 발산 함수에 의존한다는 것입니다. 이 접근 방식은 발산 함수의 선택에 민감할 수 있으며 복잡하고 미묘한 음성 감정의 변화를 처리하기에 충분히 강력하지 않을 수 있습니다.
이 문제를 해결하기 위해 이 논문에서 제안한 방법은 도메인 적대적 학습(DAL)과 같은 적대적 기반 UDA 방법을 사용하여 유망한 솔루션을 제공합니다. DAL은 도메인 분류기를 훈련시켜 소스 도메인과 대상 도메인을 구분하는 동시에 특징 추출기를 훈련시켜 도메인 분류기를 속이는 도메인 불변 표현을 생성하는 적대적 훈련의 일종입니다. 제안한 방법은 DAL을 사용하여 소스 도메인과 타겟 도메인 간의 도메인 갭을 효과적으로 줄이고 SER 모델의 성능을 향상시킬 수 있습니다.
DAL과 DANN의 차이
both DANN and DAL are adversarial-based UDA methods that aim to reduce the domain gap between the source and target domains in SER. However, DANN involves training a feature extractor and domain classifier simultaneously, while DAL involves adding a domain adversarial layer to the feature extractor.
Exactly how did they use DAL to reduce the gap between source and target domain?
본 논문에서 제안한 방법에서는 화자 독립적 음성 감정 인식(SER)에서 소스 도메인과 타깃 도메인 간의 도메인 간극을 줄이기 위해 도메인 적대적 계층(DAL)을 사용했습니다. 구체적으로 심층 특징 추출기 이후 판별자 블록에 DAL을 추가하여 소스 데이터와 타깃 데이터의 음성 감정 특징을 획득함으로써 도메인 이동을 더욱 줄이고 음성의 높은 수준의 의미론적 감정 특징을 획득했습니다.
학습 과정에서 특징 추출기는 작업별 손실을 최소화하도록 학습하고, 도메인 적대 계층은 도메인 분류 손실을 최소화하여 도메인 불변 표현을 생성하도록 학습했습니다. 도메인 분류 손실은 소스 도메인과 타깃 도메인을 구분하도록 학습된 도메인 분류기의 출력을 기반으로 계산되었습니다. 도메인 분류 손실을 최소화함으로써 도메인 적대적 계층은 도메인 분류기로 구분할 수 없는 도메인 불변형 표현을 생성하는 방법을 학습했습니다.
이를 통해 DAL은 소스 도메인과 타깃 도메인 간의 도메인 갭을 효과적으로 줄이고 SER 모델의 성능을 개선했습니다. 제안된 방법은 두 개의 벤치마크 데이터 세트에서 평가되었으며, 실험 결과 화자 독립적 SER에서 여러 최신 방법보다 성능이 뛰어난 것으로 나타났습니다.
Explain how does DAL work in this paper with generator and discriminator
본 논문에서 제안한 방법에서는 화자 독립적 음성 감정 인식(SER)에서 소스 도메인과 타깃 도메인 간의 도메인 간극을 줄이기 위해 도메인 적대적 계층(DAL)을 사용했습니다. DAL은 생성기-판별기 프레임워크로 구현되었으며, 생성기는 특징 추출기, 판별기는 도메인 적대적 계층 3으로 구성되었습니다.
훈련 과정에서 제너레이터(특징 추출기)는 예측된 감정 레이블과 지상 진실 레이블 간의 교차 엔트로피 손실인 작업별 손실을 최소화하도록 훈련되었습니다. 동시에 판별자(도메인 적대 레이어)는 예측된 도메인 레이블과 기준값 도메인 레이블 간의 이진 교차 엔트로피 손실인 도메인 분류 손실을 최소화하여 도메인 불변 표현을 생성하도록 훈련되었습니다.
도메인 적대적 계층은 라벨 판별자, 소스-대상 도메인 판별자, 화자 판별자라는 세 가지 하위 판별자로 구성되었습니다. 레이블 판별기는 입력 음성 샘플의 감정 레이블을 예측하도록 훈련되었고, 소스-타겟 도메인 판별기는 소스 도메인과 타겟 도메인을 구분하도록 훈련되었습니다. 화자 판별기는 소스 도메인에서 서로 다른 화자를 구별하도록 훈련되었습니다.
생성기와 판별기가 적대적인 방식으로 훈련되도록 하기 위해 생성기와 판별기 사이에 그라디언트 반전 레이어(GRL)를 추가했습니다. GRL은 역전파 중에 기울기를 반전시켜 제너레이터가 판별기가 구별할 수 없는 도메인 불변 표현을 생성할 수 있도록 했습니다.
제너레이터와 판별기를 적대적 방식으로 훈련함으로써 DAL은 소스 도메인과 타깃 도메인 간의 도메인 갭을 효과적으로 줄이고 SER 모델의 성능을 개선했습니다. 제안된 방법은 두 개의 벤치마크 데이터 세트에서 평가되었으며, 실험 결과 화자 독립적 SER에서 여러 최신 방법보다 성능이 뛰어난 것으로 나타났습니다.
D. DIFL for Speaker Independent SER
The DIFL framework effectively combines the hierarchical representation, hierarchical alignment, and domain adversarial approach into the deep network, which can be extended to any DCNNs.
이 논문에서 제안한 DIFL(도메인 불변 특징 학습) 방법은 계층적 표현, 계층적 정렬 및 도메인 적대적 접근 방식을 심층 네트워크에 결합하여 다중 소스 UDA의 관점에서 화자 독립적 SER을 처리합니다.
DIFL 방식은 계층적 정렬 계층이 있는 특징 추출기 블록과 감정, 화자, 도메인의 여러 판별자가 있는 판별자 블록의 두 가지 주요 블록으로 구성됩니다.
특징 추출기 블록은 입력 음성 샘플에서 높은 수준의 의미적 특징을 추출하는 역할을 담당합니다. 여러 계층으로 구성된 심층 신경망으로 구성되며, 각 계층은 입력 특징의 계층적 표현을 학습합니다. 계층적 정렬 레이어가 특징 추출기 블록에 추가되어 소스 도메인과 대상 도메인을 서로 다른 추상화 수준에서 정렬합니다. 계층적 정렬 레이어는 여러 하위 레이어로 구성되며, 각 하위 레이어는 소스 도메인과 대상 도메인을 특정 추상화 수준에서 정렬합니다.
판별자 블록은 도메인 불변 특징 학습을 촉진하는 역할을 담당합니다. 감정 판별자, 화자 판별자, 도메인 판별자 등 여러 판별자로 구성됩니다. 감정 판별자는 입력 음성 샘플의 감정 레이블을 예측하도록 훈련되며, 화자 판별자는 소스 도메인에서 서로 다른 화자를 구별하도록 훈련됩니다. 도메인 판별기는 소스 도메인과 대상 도메인을 구분하도록 훈련됩니다.
도메인 불변 특징 학습을 촉진하기 위해 DIFL 방법은 최대 평균 불일치(MMD) 메트릭을 사용하여 소스 도메인과 대상 도메인 간의 거리를 측정합니다. MMD 메트릭은 소스 도메인과 대상 도메인 간의 도메인 이동을 최소화하고 적대적 도메인 적응을 촉진하는 데 사용됩니다. 도메인 및 화자 판별자는 점진적으로 도메인 독립적인 특징을 얻기 위해 활용됩니다. 또한 DIFL의 레이블 판별자는 특징의 판별 가능성도 보장할 수 있습니다.
계층적 표현, 계층적 정렬 및 도메인 적대적 접근 방식을 결합함으로써 DIFL 방법은 소스 도메인과 대상 도메인 간의 도메인 격차를 효과적으로 줄이고 SER 모델의 성능을 향상시킬 수 있습니다. 제안된 방법은 두 개의 벤치마크 데이터 세트에서 평가되었으며, 실험 결과 화자 독립적 SER에서 여러 최신 방법보다 성능이 우수한 것으로 나타났습니다.
MK-MMD
MK-MMD는 다중 커널 최대 평균 불일치의 약자입니다. 두 확률 분포 사이의 거리를 측정하는 데 사용되는 메트릭입니다. 이 논문에서는 화자 독립적 음성 감정 인식(SER) 5에서 소스 도메인과 대상 도메인의 특징 분포 간의 불일치를 측정하는 데 MK-MMD를 사용합니다.
MMD(최대 평균 불일치)는 커널 기반 메트릭으로, 고차원 커널 힐버트 공간(RKHS)에서 두 확률 분포 사이의 거리를 측정합니다. MK-MMD는 도메인 간의 불일치를 측정하기 위해 양의 반정확(PSD) 커널의 일련의 선형 조합을 사용하여 MMD를 확장합니다. 이 논문에서는 가우시안 커널(즉, RBF 커널)을 MK-MMD의 커널 함수로 사용합니다.
MK-MMD는 도메인 이동을 줄이고 적대적 도메인 적응을 촉진하기 위해 제안된 DIFL(도메인 불변 특징 학습) 방법의 특징 학습 단계에 사용됩니다. 특히 MK-MMD는 다양한 화자에 의해 발생하는 특징 분포의 거리를 측정하는 데 사용되며, 이를 통해 소스-타겟 도메인 간의 불일치를 줄이고 특징 정렬 중 감정 판별 성능 저하를 줄일 수 있습니다. 이를 통해 MK-MMD는 소스 도메인과 타겟 도메인 간의 도메인 갭을 효과적으로 줄이고 SER 모델의 성능을 향상시킬 수 있습니다.
GRL, UDA, DIFL의 관계
논문에서 제안한 DIFL(도메인 불변 특징 학습) 방법에서는 심층 신경망에서 도메인 적대적 접근 방식을 구현하기 위해 그라디언트 반전 레이어(GRL)를 사용합니다. GRL은 화자 독립적 음성 감정 인식(SER) 에서 소스 도메인과 타겟 도메인 간의 도메인 격차를 줄이는 데 사용되는 비지도 도메인 적응(UDA) 프레임워크의 핵심 구성 요소입니다.
GRL은 DIFL 방식에서 특징 추출기 블록과 판별기 블록 사이에 추가됩니다. 순방향 전파 중에 GRL은 입력을 변경하지 않고 유지하며, 역전파 중에는 기울기를 반전시켜 도메인 불변 특징 학습을 촉진합니다. GRL을 사용하면 특징 추출기 블록이 판별자 블록으로 구별할 수 없는 도메인 불변형 표현을 생성할 수 있습니다.
DIFL 방법의 UDA 프레임워크는 최대 평균 불일치(MMD) 메트릭을 사용하여 구현됩니다. MMD 메트릭은 소스 도메인과 대상 도메인의 특징 분포 사이의 거리를 측정하는 데 사용됩니다. MMD 메트릭을 최소화함으로써 DIFL 방법은 소스 도메인과 타깃 도메인 간의 도메인 갭을 줄이고 적대적 도메인 적응을 촉진할 수 있습니다.
딥 뉴럴 네트워크는 DIFL 방법에서 GRL과 UDA를 결합하여 소스 도메인과 타깃 도메인 간의 도메인 이동에 강한 도메인 불변 특징을 학습할 수 있습니다. 이를 통해 DIFL 방법은 소스 도메인과 타겟 도메인 간의 도메인 갭을 효과적으로 줄이고 SER 모델의 성능을 향상시킬 수 있습니다. 제안된 방법은 두 개의 벤치마크 데이터 세트에서 평가되었으며, 실험 결과 화자 독립적 SER에서 여러 최신 방법보다 성능이 뛰어난 것으로 나타났습니다.
IV. EXPERIMENTS
A. Speech Emotion Databases
- Emo-DB: The Berlin Database of Emotional Speech (Emo-DB) is a German-language database containing speech samples from 10 actors (5 male, 5 female) expressing 7 different emotions (anger, boredom, disgust, fear, happiness, sadness, and neutral). The database consists of 535 utterances with a total duration of approximately 1 hour.
- eNTERFACE: The eNTERFACE database is an English-language audio-visual emotion database containing speech samples from 44 subjects from different nationalities expressing 6 basic emotions (anger, disgust, fear, happiness/joy, sadness, and surprise). The database consists of 1,290 English sentences extracted from videos with a sampling rate of 48 kHz.
- CASIA: The Chinese Academy of Sciences Institute of Automation (CASIA) emotional speech database is an acted Chinese-language database containing speech samples from four actors (2 male and 2 female) expressing six different emotional states (anger, fear, happiness, neutral, sadness and surprise). The database consists of 1200 public sentences with a sampling rate of 16 kHz.
B. Experimental Setting
1) 데이터 전처리
실험에 사용된 멜-스펙트로그램은 음성 신호에 대해 512개의 샘플 포인트와 절반이 겹치는 창 길이로 STFT를 수행한 후 사람의 청각 지각에 더 근접한 멜-필터 뱅크를 통과하여 얻은 것으로, 멜-필터 번호는 80입니다. 입력 스펙트로그램의 일관성을 보장하기 위해 사용된 데이터베이스의 샘플링 속도를 16kHz로 정규화하고 단일 채널 데이터를 가져옵니다. 또한 각 데이터베이스의 음성 길이도 정규화하여 전체 훈련 세트 샘플의 평균값에 표준 편차를 더한 값을 균일한 길이로 선택하고, 길이가 부족한 각 문장은 0으로 채우고 긴 문장은 세그먼트 단위로 잘라냅니다.
2) 실험 프로토콜
제안한 방법의 성능을 평가하기 위해 [9], [11], [35]에서 제안한 바와 같이 화자 독립적 SER 실험에서 LOSO(Leave-One-Speaker-Out) 교차 검증 전략을 채택합니다. 특히, eNTERFACE 데이터베이스에는 44명의 화자가 포함되어 있지만, 6번째 샘플은 컷이 없는 동영상입니다. 따라서 본 실험에서는 6번째 샘플을 제외한 43개의 피사체와 1,287개의 비디오 클립을 사용합니다. 또한 실험과 평가를 보다 효율적으로 수행하기 위해 화자 독립적 SER [11], [56]의 두 벤치마크 연구에 따라 LOSGO(Leave-One-Speaker-Group-Out) 전략을 채택했습니다. 따라서 eNTERFACE의 화자는 5개의 화자 그룹으로 나뉘고, Emo-DB와 CASIA는 각각 10개의 화자와 4개의 화자 그룹으로 나뉘며, 또한 널리 사용되는 두 가지 평가 기준[11], 즉 가중 평균 회상(WAR)과 가중 평균 회상(UAR)을 채택하여 SER의 인식 성능을 평가하는데, WAR은 ‘정상’ 인식 정확도로 사용되는 반면 UAR은 클래스별 정확도(즉, 클래스당 회상)를 클래스 수로 나눈 값을 반영합니다. 화자와 독립적인 SER에서는 데이터베이스의 감정 카테고리가 불균형하기 때문에 UAR은 모델의 성능을 보다 가시적으로 측정합니다.
LOSO & LOSGO
LOSO는 데이터 집합을 여러 개의 하위 집합으로 나누고 교차 검증을 반복할 때마다 하나의 하위 집합을 테스트 집합으로 사용하고 나머지 하위 집합을 훈련 집합으로 사용하는 Leave-One-Speaker-Out의 약자입니다. 이 전략은 보이지 않는 스피커에서 모델의 성능을 평가하는 데 사용됩니다.
LOSGO는 Leave-One-Speaker-Group-Out의 약자로, 데이터 집합을 여러 화자 그룹으로 나누고 교차 검증의 각 반복에서 하나의 화자 그룹을 테스트 집합으로 사용하고 나머지 화자 그룹을 훈련 집합으로 사용합니다. 이 전략은 보이지 않는 화자 그룹에 대한 모델의 성능을 평가하고 화자 가변성으로 인한 편향을 줄이는 데 사용됩니다.
본 논문에서는 제안된 DIFL(도메인 불변 특징 학습) 방법의 성능을 평가하기 위해 LOSO와 LOSGO 교차 검증 전략을 모두 사용하여 eNTERFACE, Emo-DB 및 CASIA 데이터베이스에 대한 성능을 평가합니다. 그 결과 DIFL 방법이 화자 독립적 SER에서 여러 최신 방법보다 성능이 우수하다는 것을 보여줍니다.
WAR, UAR
Page 7에 설명된 대로 WAR과 UAR은 음성 감정 인식(SER) 실험에 널리 사용되는 두 가지 평가 기준입니다.
WAR은 가중 평균 회상률을 의미하며, 다중 클래스 분류 문제에 일반적으로 사용되는 지표입니다. SER에서 WAR은 ‘정상’ 인식 정확도로 사용되며, 이는 각 클래스의 샘플 수에 따라 가중치를 부여한 모든 감정 클래스의 평균 회상률입니다. WAR은 데이터 세트의 모든 감정을 인식하는 모델의 전반적인 성능을 측정합니다.
UAR은 가중치 없는 평균 회상률을 의미하며, SER 실험에 사용되는 또 다른 지표입니다. UAR은 추가된 클래스별 정확도(즉, 클래스당 회상률)를 클래스 수로 나눈 값을 반영합니다. 화자에 독립적인 SER에서는 데이터베이스의 감정 카테고리가 불균형하기 때문에 UAR은 모델의 성능을 보다 통찰력 있게 측정합니다. UAR은 각 클래스의 샘플 수를 고려하지 않고 모든 감정 클래스의 평균 리콜을 측정합니다. UAR은 과소 대표되는 감정 클래스에 대한 모델의 성능을 평가하는 데 유용한 지표입니다.
본 논문에서는 제안된 DIFL(도메인 불변 특징 학습) 방법의 인식 성능을 평가하기 위해 WAR과 UAR을 모두 사용하여 eNTERFACE, Emo-DB, CASIA 데이터베이스에 대한 인식 성능을 평가합니다. 그 결과, DIFL 방식이 여러 최신 방식과 비교하여 WAR과 UAR 모두에서 상당한 개선을 달성하는 것으로 나타났습니다.
일반적으로 WAR과 UAR이 높을수록 데이터 세트에서 감정을 인식하는 모델의 성능이 더 우수하다는 것을 나타냅니다. 그러나 WAR 및 UAR의 해석은 특정 데이터 세트와 당면한 작업에 따라 달라진다는 점에 유의해야 합니다.
예를 들어, 일부 감정 클래스가 다른 클래스보다 샘플 수가 현저히 적은 불균형 데이터 세트의 경우, 모델이 다수 클래스에 편향된 경우 높은 WAR이 반드시 좋은 성능을 나타내는 것은 아닐 수 있습니다. 이러한 경우 UAR은 각 클래스의 샘플 수를 고려하지 않고 모든 감정 클래스의 평균 리콜을 측정하여 모델의 성능을 보다 통찰력 있게 평가할 수 있습니다.
또한 평가 메트릭의 선택은 특정 애플리케이션과 작업의 요구 사항에 따라 달라집니다. 예를 들어, 일부 애플리케이션에서는 전체 WAR 또는 UAR을 최적화하는 것보다 특정 감정 클래스에 대해 높은 정밀도 또는 높은 리콜을 달성하는 것이 더 중요할 수 있습니다.
따라서 WAR과 UAR은 SER 실험에서 모델의 성능을 평가하는 데 유용한 지표이지만 데이터 세트 특성, 작업 요구 사항 및 모델의 한계와 같은 다른 요소도 고려하는 것이 중요합니다.
3) Network Parameters
이 논문에서는 음성 감정 인식(SER) 실험을 위해 제안된 DIFL(도메인 불변 특징 학습) 프레임워크의 네트워크 파라미터에 대해 설명합니다. DIFL 프레임워크는 계층적 표현을 위한 baseline 네트워크로 가벼운 VGG 네트워크를 사용하며, 논문 7에서 DIFL_VGG6이라고 합니다. DIFL_VGG6 네트워크는 4개의 컨볼루션 블록과 2개의 완전 연결(fc) 레이어로 구성됩니다. 각 컨볼루션 블록에는 컨볼루션(컨볼루션 커널은 3×3), 배치 정규화, ReLU 및 최대 풀링 연산이 포함되어 있습니다. 4개 레이어의 컨볼루션 커널 수는 각각 64, 128, 256, 512이며, fc의 차원은 4,096입니다.
이 논문에서는 DIFL_VGG6 외에도 DIFL 프레임워크를 다른 두 개의 baseline 네트워크, 즉 VGG19와 VGGish로 확장하여 각각 DIFL_VGG19와 DIFL_VGGish라고 부릅니다.
C. Experimental Results and Analysis
이 논문에서는 제안된 음성 감정 인식(SER)을 위한 DIFL 프레임워크의 실험 결과를 보고합니다. 이 논문에서는 공개적으로 사용 가능한 세 가지 데이터베이스, 즉 eNTERFACE, Emo-DB, CASIA에서 제안한 방법의 성능을 평가하고 여러 최신 방법과 비교합니다.
이 논문에서는 제안된 방법의 인식 성능을 가중 정확도(WAR)와 무가중 정확도(UAR)라는 두 가지 평가 지표를 통해 보고합니다. WAR은 모든 감정 클래스에서 모델의 평균 정확도를 측정하며, 각 클래스의 샘플 수에 따라 가중치를 부여합니다. UAR은 각 클래스의 샘플 수를 고려하지 않고 모든 감정 클래스에서 모델의 평균 정확도를 측정합니다.
그 결과, 제안된 DIFL 방식이 기준 방식에 비해 WAR과 UAR 모두에서 상당한 개선을 달성한 것으로 나타났습니다. 특히, eNTERFACE 데이터베이스에서 제안된 방법은 80.5%의 WAR과 80.3%의 UAR을 달성하여 최신 방법보다 큰 폭으로 성능이 향상되었습니다. Emo-DB 데이터베이스에서 제안된 방법은 70.6%의 WAR과 70.4%의 UAR을 달성하여 역시 최신 방법보다 우수한 성능을 보였습니다. CASIA 데이터베이스에서 제안된 방법은 70.2%의 WAR과 70.0%의 UAR을 달성하여 최신 방법과 비슷한 수준입니다.
이 논문에서는 실험 결과에 대한 자세한 분석도 제공합니다. 분석 결과, 제안된 DIFL 방법은 도메인 이동에 강하고 보이지 않는 도메인에도 잘 일반화할 수 있는 도메인 불변 특징을 학습하는 데 효과적임을 보여줍니다. 또한 분석 결과 제안된 방법은 SER 작업에서 흔히 발생하는 화자 가변성으로 인한 도메인 이동을 처리하는 데 특히 효과적이라는 것을 보여줍니다. 또한, 분석 결과 제안한 방법이 다양한 감정 클래스의 판별 정보를 포착하고 높은 인식 정확도를 달성할 수 있음을 보여줍니다.
전반적으로 실험 결과와 분석은 제안한 DIFL 프레임워크가 SER 작업에 효과적이며 최신 방법보다 우수하다는 것을 보여줍니다.
V. Conclusion
이 논문에서는 다중 소스 비지도 도메인 적응(UDA)의 관점에서 음성 감정 인식(SER)을 위한 도메인 불변 특징 학습(DIFL) 프레임워크를 제안합니다. 제안된 DIFL 프레임워크는 도메인 이동에 강하고 보이지 않는 도메인에도 잘 일반화할 수 있는 도메인 불변 특징을 학습하는 것을 목표로 합니다. 이 논문에서는 공개적으로 사용 가능한 세 가지 데이터베이스, 즉 eNTERFACE, Emo-DB, CASIA에서 제안된 방법의 성능을 평가하고 여러 최신 방법과 비교합니다.
실험 결과, 제안한 DIFL 방식이 기준 방식에 비해 가중 정확도(WAR)와 무가중 정확도(UAR) 모두에서 유의미한 개선을 달성한 것으로 나타났습니다. 실험 결과의 분석은 제안된 DIFL 방법이 도메인 이동에 강하고 보이지 않는 도메인에도 잘 일반화할 수 있는 도메인 불변 특징을 학습하는 데 효과적이라는 것을 보여줍니다. 또한 제안된 방법은 SER 작업에서 흔히 발생하는 화자 가변성으로 인한 도메인 이동을 처리하는 데 특히 효과적이라는 것을 분석 결과를 통해 알 수 있습니다.
이 논문은 실험 결과와 분석을 바탕으로 제안된 DIFL 프레임워크가 SER 작업의 도메인 이동 문제를 해결하는 데 효과적이며 공개적으로 사용 가능한 데이터베이스에서 최첨단 성능을 달성할 수 있다고 결론지었습니다. 또한 이 논문은 SER 작업에서 도메인 불변 특징 학습의 중요성을 강조하고 제안된 DIFL 프레임워크가 음성 인식, 화자 확인, 언어 식별과 같은 다른 관련 작업으로 확장될 수 있음을 제안합니다.