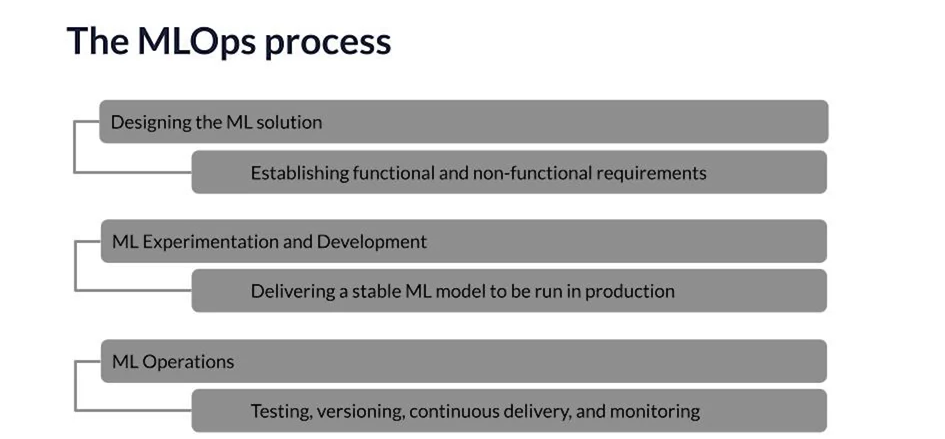
Course
Overview
the key steps involved in a typical machine learning project.
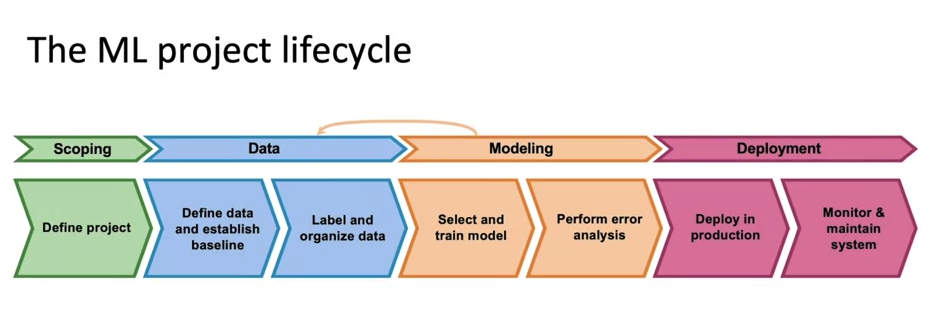
- It starts with scoping, where the project goals and variables (X and Y) are defined. Data collection follows, including establishing a baseline, labeling, and organizing the data. The next phase is model training, which involves selecting and training the model, as well as conducting error analysis. Iteration is emphasized, with the possibility of updating the model or collecting more data based on error analysis. Before deployment, a final check or audit is recommended to ensure system performance and reliability. Deployment involves writing the necessary software, monitoring the system, and maintaining it. Maintenance may involve further error analysis, model retraining, and incorporating live data feedback to improve the system. The script emphasizes that deployment is not the end but rather the start of ongoing learning and improvement for the system.
Example: Speech recognition
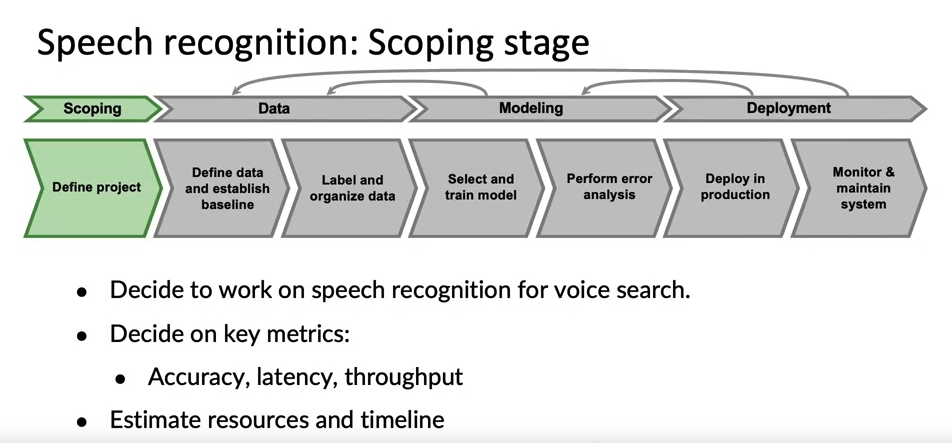
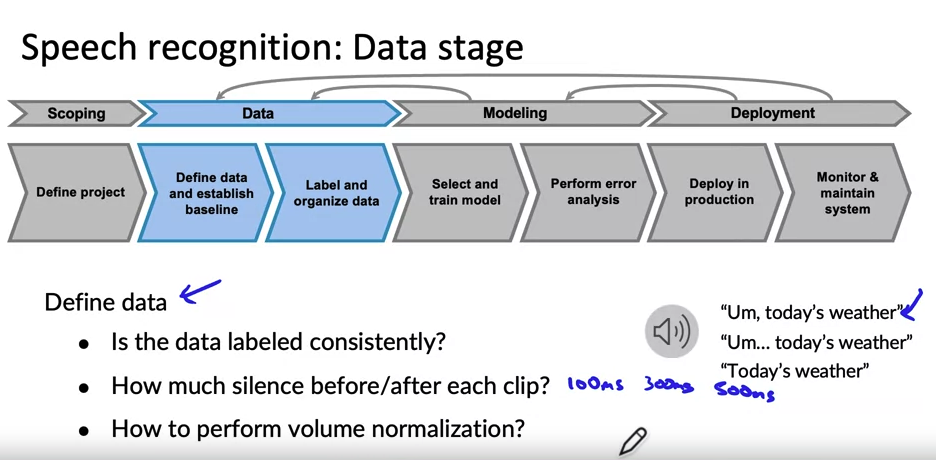
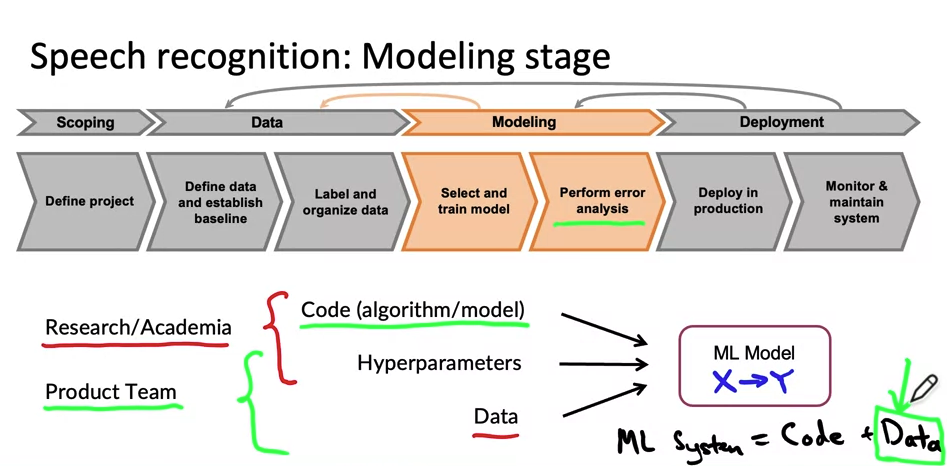
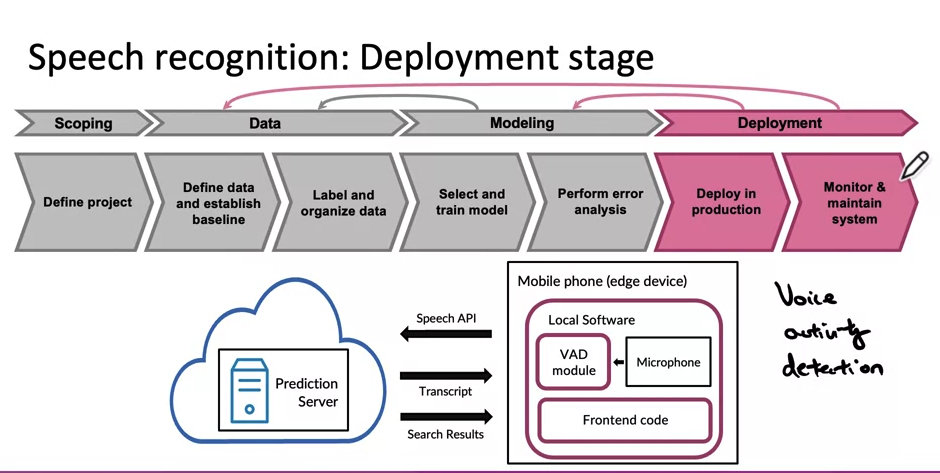
The challenges and considerations involved in deploying a machine learning model
- It highlights two major categories of challenges: machine learning/statistical issues and software engineering issues. It addresses the concept of concept drift and data drift, which refer to changes in the data distribution and the desired mapping between inputs and outputs. The script also touches upon various software engineering decisions, such as real-time vs batch predictions, cloud vs edge deployment, resource allocation, latency and throughput requirements, logging, and security/privacy considerations. It emphasizes the importance of monitoring system performance and adapting to changes in data. Finally, it mentions that the deployment process is ongoing and requires continuous maintenance and updates.
Deploy patterns
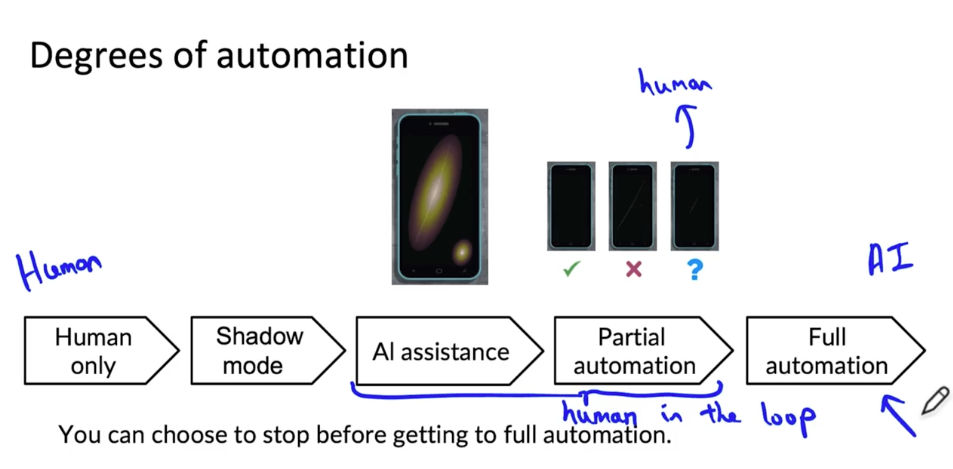
- One of the most useful frameworks I have found for thinking about how to deploy a system is to think about deployment not as a 0, 1 is either deploy or not deploy, but instead to design a system thinking about what is the appropriate degree of automation. For example, in visual inspection of smartphones, one extreme would be if there’s no automation, so the human only system. Slightly mode automated would be if your system is running a shadow mode. So your learning algorithms are putting predictions, but it’s not actually used in the factory. So that would be shadow mode. A slightly greater degree of automation would be AI assistance in which given a picture like this of a smartphone, you may have a human inspector make the decision. But maybe an AI system can affect the user interface to highlight the regions where there’s a scratch to help draw the person’s attention to where it may be most useful for them to look. The user interface or UI design is critical for human assistance. But this could be a way to get a slightly greater degree of automation while still keeping the human in the loop. And even greater degree of automation maybe partial automation, where given a smartphone, if the learning algorithm is sure it’s fine, then that’s its decision. It is sure it’s defective, then we just go to algorithm’s decision. But if the learning algorithm is not sure, in other words, if the learning algorithm prediction is not too confident, 0 or 1, maybe only then do we send this to a human. So this would be partial automation. Where if the learning algorithm is confident of its prediction, we go the learning algorithm. But for the hopefully small subset of images where the algorithm is not sure we send that to a human to get their judgment. And the human judgment can also be very valuable data to feedback to further train and improve the algorithm. I find that this partial automation is sometimes a very good design point for applications where the learning algorithms performance isn’t good enough for full automation. And then of course beyond partial automation, there is full automation where we might have the learning algorithm make every single decision.
- So there is a spectrum of using only human decisions on the left, all the way to using only the AI system’s decisions on the right. And many deployment applications will start from the left and gradually move to the right. And you do not have to get all the way to full automation. You could choose to stop using AI assistance or partial automation or you could choose to go to full automation depending on the performance of your system and the needs of the application.
Train
- focused on modeling
Establish a baseline
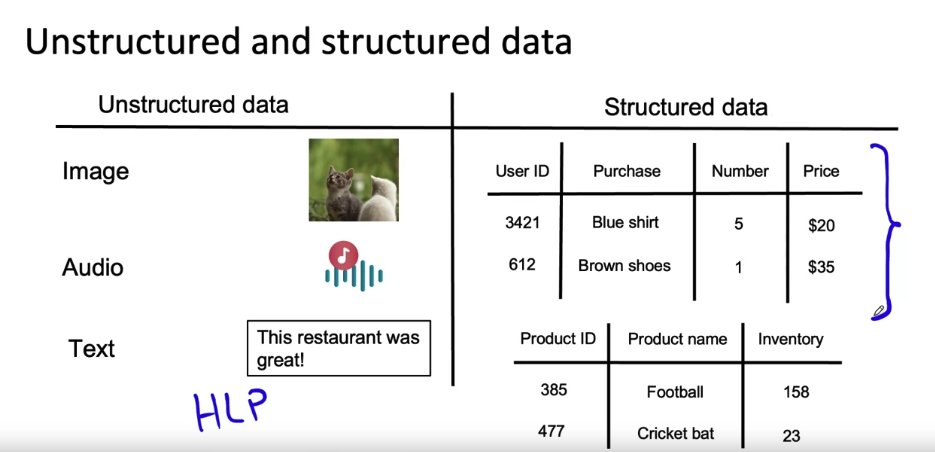
- unstructured data and structured data: unstructured data has good Human Level Performance(HLP), while structured data doesn’t and relies on Dictionary data set

Prioritizing what to work on

To summarize, when prioritizing what to work on, you might decide on the most important categories to work on based on, how much room for improvement there is, such as, compared to human-level performance or according to some baseline comparison. How frequently does that category appear? You can also take into account how easy it is to improve accuracy in that category. For example, if you have some ideas for how to improve the accuracy of speech with car noise, maybe your data augmentation, that might cause you to prioritize that category more highly than some other category where you just don’t have as many ideas for how to improve the system. Then finally, how important it is to improve performance on that category. For example, you may decide that improving performance with car noise is especially important because when you’re driving, you have a stronger desire to do search, especially search on maps and find addresses without needing to use your hands if your hands are supposed to be holding the steering wheel.
skewed dataset
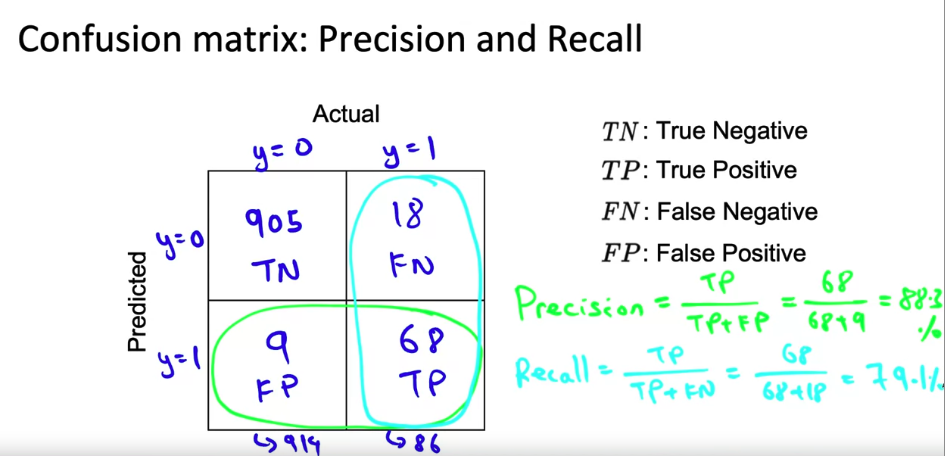
The learning algorithm with some precision, even the high value of precision is not that useful usually if this recall is so low.

here’s a common way of combining precision and recall using this formula, which is called the F_1 score. One intuition behind the F_1 score is that you want an algorithm to do well on both precision and recall, and if it does worse on either precision or recall, that’s pretty bad. F_1 is a way of combining precision and recall that emphasizes whichever of P or R precision or recall is worse. In mathematics, this is technically called a harmonic mean between precision and recall, which is like taking the average but placing more emphasis on whichever is the lower number. If you compute the F_1 score of these two models, it turns out to be 83.4 percent using the formula below here. Model 2 has a very bad recall, so its F_1 score is actually quite low as well and this lets us tell, maybe more clearly that Model 1 appears to be a superior model than Model 2.
Performance auditing

What is good data?
