Journal/Conference : ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Year(published year): 2022
Author: Yuan Gao, Shogo Okada, Longbiao Wang, Jiaxing Liu, Jianwu Dang
Subject: Speech Emotion Recognition, Domain Adaptation, Center Loss
Domain Invariant Feature Learning for Cross Corpus Speech Emotion Recognition
Summary



I. Introduction
연구의 필요성
기존 SER의 접근 방식은 동일한 데이터 셋에서 훈련 및 테스트 됨.
자연환경에서 대규모 주석이 달린 감정 발화를 수집하는 것은 시간이 오래 걸리기 때문에 기존 데이터 세트에는 적은 수의 음성 샘플이 포함되어 있어 강력한 딥러닝 모델을 훈련하기에는 충분하지 않음.
또한 실제 환경에서 음성의 감정 정보는 도메인 정보의 변화로 인해 학습하기 어려움.
따라서 SER 시스템을 미지의 데이터 세트에 적용할 경우에는 인식 성능이 크게 저하되는 경우가 많음.
실제 어플리케이션을 다루기 위해 다양한 데이터 세트를 사용하여 모델을 평가해야 함.
최근 연구에서는 연구자들이 cross corpus SER에서 CNN, RNN, 및 attention의 성능을 평가하기도 함[11,12]
contribution
SER의 일반화 능력을 더욱 향상 시키기 위해 adversarial domain adaptation 방법을 사용하여 학습 데이터와 테스트 데이터 간의 도메인 차이를 줄였음.
구체적으로 adversarial training을 통해 latent representation의 화자, 코퍼스 및 기타 도메인 정보를 제거함.
domain adaptation은 feature extractor와 domain classifier 사이의 gradient를 역전시킴으로써 이루어지며 이를 통해 모델은 비감정적 정보의 학습 손실을 최대화 할 수 있음.
또한 기존 연구에서 일반적으로 사용되는 감정 분류기는 softmax 손실함수를 사용하여 decision boundary를 찾고 감정을 구분함.
feature representation에 차별성을 두기 위해 center loss를 통합함, 그리고 그것은 feature extractor를 위한joint supervision처럼 feature representation과 해당 클래스 center의 거리를 최소화 하기 위해 훈련되었음.
II. Adversarial Domain Adaptation For Feature Extraction
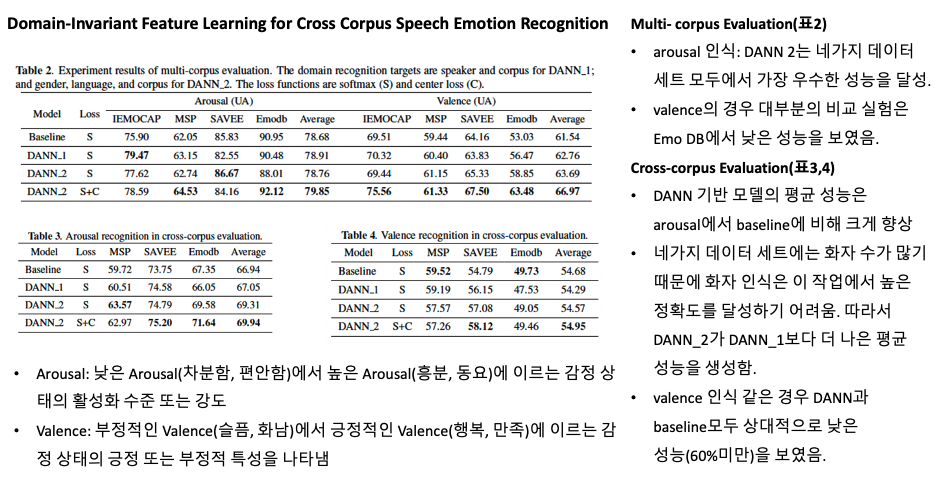
Fig 1에서 볼 수 있듯이, 우리는 특징 추출을 위해 deep CNN과 BLSTM layer을 사용하며, 이 layer의 parameter는 [13]에서 쓰인것과 유사함.
우리는 Domain Adversarial Neural Network(DANN)으로 feature extractor를 조정하였음.
또한 feature representation의 intra-class 변화를 줄이기 위해 center loss를 사용했음.
DANN과 center loss 둘다 domain divergence를 해결할수 있음.
Domain Adversarial Training
이 연구에서는 비감정적인 정보를 제거하기 위해 특징 추출기에 DANN을 통합했음.
DANN은 multi-task learning 모델
DANN의 recognition target은 emotion classifier(LE), domain classifier(LD)이다.
본 연구에서 LD의 domain recognition target은 코퍼스, 언어, 성별이다.
하나의 training과정 안에서 domain adaptation과 feature representation 학습을 달성하기 위해 [14]는 domain classifier과 feature extractor 사이에 gradient reversal layer(GRL)을 두었음.
GRL은 역전파 과정에서 특정 음의 상수를 도메인 분류 작업의 기울기에 곱할수 있음.
소스 도메인과 타겟 도메인에서 학습한 feature distribution이 우리 모델과 구별되지 않도록 DANN 학습을 시킴.
이렇게 GRL을 통해 domain invariant representation을 추출하여 코퍼스 간 감정인식을 위한 일반화 능력을 향상할수 있음.
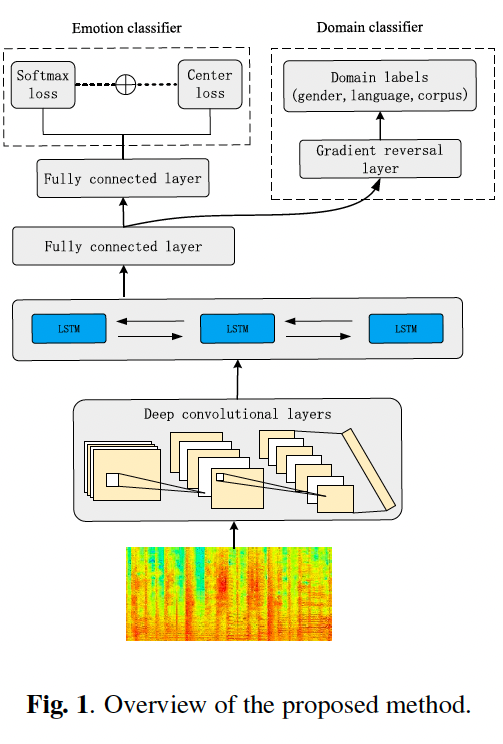
제안된 feature extraction 모델의 objective function은 다음과 같음.
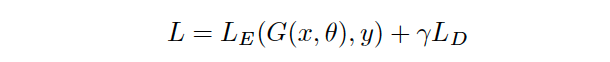
LE: center loss와 softmax loss를 결합한 emotion classifier의 loss function(자세한 내용은 Center Loss)
이 특정 작업에서는 앞서 언급한 비감정적인 정보를 feature extractor G(x, $\theta$)가 학습하지 않도록 $\gamma$를 0.3으로 설정 했음.
DANN 학습을 통해 모델은 feature distribution의 domain shift를 제거할 수 있음.
domain classifier의 손실함수는 다음과 같이 표현됨
Lg, Ll, Lc는 성별, 언어, 말뭉치의 loss function
LE를 최소화 하고 LD를 최대화 하는 안정점을 찾아냄으로써 우리가 제안한 feature extractor는 emotion classifier의 input에서 domain divergence를 크게 줄일 수 있음.
Center Loss
제안된 feature extractor외에도 softmax loss와 center loss[15]를 joint supervision으로 emotion classifier LE에추가적으로 적용함.
softmax loss function은 SER에서 다양한 감정의 decision boundary를 찾기 위해 일반적으로 사용됨.
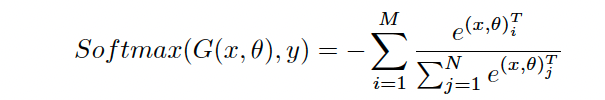
M: 미니 배치의 크기, N: emotion class의 개수.
본 연구에서는 training sample과 test sample에 대해 동일한 emotion annotation을 정의했지만, 서로 다른 데이터 세트의 feature distribution이 분리 가능한 cluster로 나타나지 않았음. 그리고 그것은 cross corpus SER이 일반적인 close-set identification 작업보다 더 어렵게 만듦.
이 문제를 해결하기 위해서 center loss를 도입하여 각 감정 카테고리에 대한 class center c를 학습함으로써 feature distribution의 클래스 내(intra-class) 거리를 줄였음.
이 loss function은 input feature와 해당 class center 사이의 유클리드 거리로 계산됨.
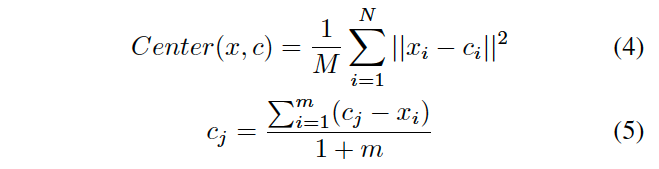
Class center c를 보다 효율적으로 업데이트 하기 위해 loss function은 각 미니배치에 대해서 학습되었음.
5번 식에서 m은 새 미니배치에 있는 클래스 i의 샘플 개수.
감정 분류기 전체의 objective function은 다음식으로 정의됨
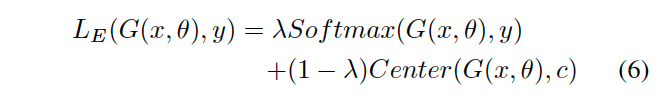
각 loss term의 가중치를 control하기 위해 $\lambda$를 0.5로 설정.
center loss와 softmax loss를 결합하여 모델을 동통으로 최적화 함으로써 cross corpus SER 작업을 위한 robust한 feature representation을 추출할 수 있음.
III. Experimental Setup
Emotional Speech Dataset
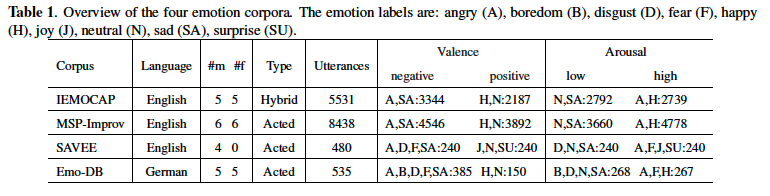
네가지 감정 코퍼스를 사용해 모델을 평가합니다: IEMOCAP, MSP-IMPROV, SAVEE, Emo-DB
IEMOCAP: 오디오, 비디오, 얼굴 모션 정보를 포함한 12시간 분량의 시청각 데이터와 10명의 화자와 텍스트 필사본이 포함되어 있음. 실험에는 스크립트 데이터와 즉흥 데이터 모두 5531 발화를 사용. 행복, 슬픔, 분노, 중립의 감정이 기록돼 있음.
MSP-IMPROV: 다이나믹 세션에서 상호작용하는 배우로부터 기록된 다중모드 감정 데이터 베이스. 12명의 배우러부터 녹음된 8438개의 감정 문장 발화로 구성되어 있음. 행복, 슬픔, 분노, 중립의 감정 카테고리
SAVEE: 남성 피험자 4명의 audio-visual 녹음을 포함하고 있음. 480개의 원어민 영어 발화로 구성되어 있고 행복, 슬픔, 혐오, 분노, 지루함, 두려움인 6가지 감정에 대해서 60개, 중립에 대해 120개의 발화가 포함됨
Emo-DB: 10명의 전문 배우가 녹음환경에서 연기. 배우들은 각 문장을 7가지 감정 상태(중립, 지루함, 혐오, 슬픔, 분노, 행복, 두려움)로 표현함. 총 535개 발화
Experimental Settings
두가지 검증 체계를 사용하여 모델을 평가
- cross-corpus evaluation: 모델은 IEMOCAP에 대해서만 훈련하고 나머지는 세개의 말뭉치에서 테스트
- Multi-corpus evaluation: 네개의 데이터 세트를 모두 train set(80%)와 test set(20%)으로 나누고 각 코퍼스의 테스트 데이터를 사용하여 모델을 평가. train set과 test set은 화자가 겹치지 않음.
optimizer로는 adadelta를 사용했으며 미니배치사이즈는 128.
전처리 과정에서 모든 데이터는 16kHz로 다운샘플링 하였음.
input feature로는 spectrogram을 사용하였고 input 발화는 265ms로 분할되며 각 세그먼트에 대해 25ms의 프레임 size로 input spectrogram이 계산됨.
input spectrogram의 time X frequency는 32 X 129.
IV. Results and Analysis
Unweighted Accuracy(UA)를 평가기준으로 선택
baseline: CNN + BLSTM의 조합.
제안된 두개의 DANN-based approaches 들을 비교
- DANN_1: domain classifier의 인식 대상이 화자와 corpus
- DANN_2: speaker classification이 언어와 성별 인식으로 대체
C: center loss, S: softmax loss
multi corpus 실험 결과, domain recognition 대상은 DANN 1의 경우 화자와 코퍼스이고 DANN 2의 경우 성별, 언어, 말뭉치.
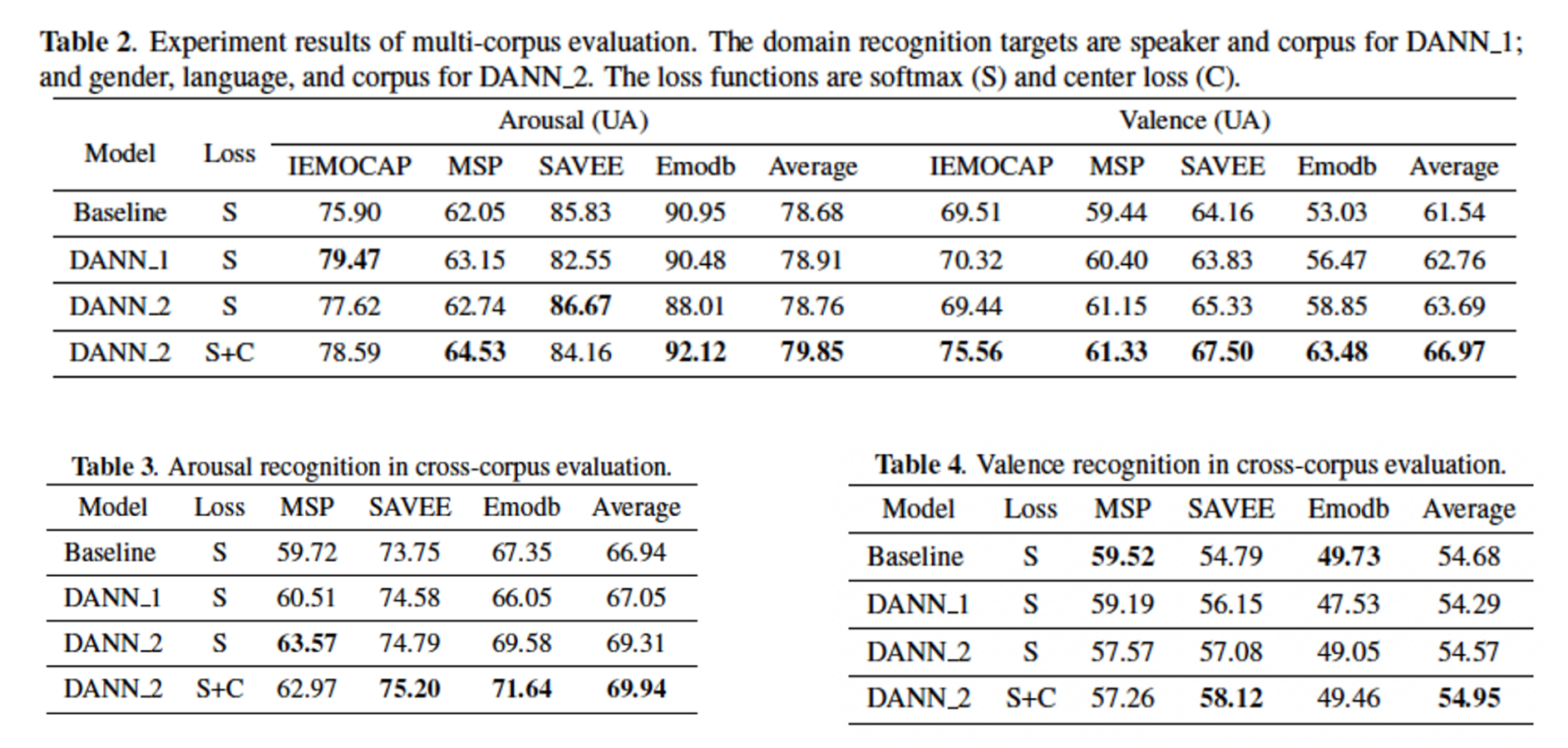
Multi- corpus Evaluation
표2에서 다중 코퍼스 평가 결과를 제시. arousal 인식의 경우 DANN 2는 비교 실험보다 작지만 꾸준한 개선으로 네가지 데이터 세트 모두에서 가장 우수한 성능을 달성.
valence의 경우 대부분의 비교 실험은 Emo DB에서 낮은 성능을 보였음.
EmoDB 훈련세트는 주로 negative input으로 이루어져 있음. 또한 EmoDB와 다른 데이터 세트의 언어 불일치로 인해 이 데이터세트의 인식 성능은 상대적으로 낮음.
이러한 상황임에도 불구하고 모델은 positive, negative에 대해 비교적 동등한 인식 정확도를 보였고 UA를 10.45%나 향상 시켰음.
또한 제안된 center loss는 모델이 더 많은 discriminative feature representation을 추출하고 평균 정확도를 3.28%나 향상 시킴.
결과는 제안된 모델이 데이터 세트 전반에서 감정 정보를 일반화 할 수 있음을 보여줌
Cross-corpus Evaluation
교차 코퍼스 평가결과는 제안된 모델의 효과를 입증함.
표3과 4에서 볼수 있듯이 DANN 기반 모델의 평균 성능은 arousal에서 baseline에 비해 크게 향상된 것으로 나타났음.
또한 네가지 데이터 세트에는 화자 수가 많기 때문에 화자 인식은 이 작업에서 높은 정확도를 달성하기 어려움. 따라서 DANN_2가 DANN_1보다 더 나은 평균 성능을 생성함.
그러나 valence 인식 같은 경우 DANN과 baseline모두 상대적으로 낮은 성능(60%미만)을 보였음.
Emo DB의 valence인식의 경우 언어 불일치로 인해 네가지 비교 실험 인식 성능이 확률 수준(chance level) 이하임.
이러한 결과는 DANN 학습이 Valence 인식의 경우에 더 달성하기 어렵다는 것을 나타내며 이는 [20]에도 자세하게 나와있음.
V. Conclusion
이 논문에서 cross corpus SER 시스템의 일반화 능력을 높이기 위한 adversarial domain adaptation 과 center loss에 대해 조사했음.
SER의 domain invariant feature learning의 단계로 특징 추출을 DANN으로 수정하고 다른 데이터 세트에서 도메인 차이를 줄였음.
또한 감정인식을 위한 discriminative feature representation을 학습하기 위해 center loss와 softmax loss function을 통합함.
실험 결과에 따르면
- arousal에 비해 deep learning 모델은 valence information을 일반화 시키는게 더 어려움.
- 제안된 모델은 기존의 딥러닝 기반 모델보다 더 유명한 평균 결과를 달성하여 효과를 입증함.