Journal/Conference : IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing,(HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS)
Year(published year): 2019
Author: Han, Zhijie, Huijuan Zhao, and Ruchuan Wang
Subject: transfer learning, speech emotion recognition, domain adaption, cross-domain
Transfer Learning for Speech Emotion Recognition
Summary
- 이 논문은 감정이 인간의 커뮤니케이션에서 중요한 역할을 하는 것을 고려하여, transfer learning의 이론과 주요 범주를 조사하고 speech emotion recognition에서의 적용을 연구하며, 이를 통해 감정 인식 모델의 성능을 개선하는 방법을 제안합니다.
- 감정 인식을 위한 레이블 데이터를 수집하는 것은 어려울 수 있지만, 전이 학습은 다른 분야에서 학습된 지식을 활용하여 감정 인식 모델의 성능을 향상시키는 데 사용할 수 있습니다.이렇게 하면 레이블 데이터에 대한 의존도를 낮추고 감정 인식 모델의 성능을 향상시킬 수 있습니다.
I. Introduction
- 음성 감정 인식의 복잡성으로 인해, 고성능의 강력한 인식은 여전히 매우 어려운 과제입니다.
Due to the complexity of the speech emotion recognition, high performance and robust recognition is still very challenging. - 주된 이유는 다음과 같습니다:
- 인간의 오디오 생성은 말하는 장면, 말하는 방식, 화자의 나이, 성별, 말하기 습관 등 말하기의 맥락과 직접적으로 관련이 있습니다[11].
human audio generation is directly related to the context of speech, such as the speaking scene, the way of speaking, and the age, gender, and speaking habits of the speaker [11]. - 음성 데이터 수집은 복잡하며 백그라운드 노이즈를 처리해야 합니다.
The collection of speech data is complex, and need deal with the back ground noise. - 감정은 주관적이며 공식적인 감정 정의가 없습니다.
Emotion is subjective, and there is no formal emotion definition. - 데이터에 레이블을 지정하는 사람의 감정 인식 능력은 감정 데이터의 주석에 영향을 미칩니다[12]. annotations은 완전한 음성 정보 표현에 의존하므로 주석 작업에 시간이 많이 걸리므로 주석이 달린 공공 음성 감정 코퍼스의 수가 제한되어 있습니다.
The emotional perception ability of the person who labels the data affects the annotation of the emotion data[12]. Annotation relies on the complete speech information presentation, so the annotation work is time consuming.Therefore, the number of the annotated public speech emotion corpora is limited.
- 인간의 오디오 생성은 말하는 장면, 말하는 방식, 화자의 나이, 성별, 말하기 습관 등 말하기의 맥락과 직접적으로 관련이 있습니다[11].
- 현재 머신러닝 연구는 훈련 세트와 테스트 세트가 동일한 특징공간에 속하고 동일한 분포를 갖는다는 전제하에 이루어지고 있습니다. 그러나 실제 어플리케이션에서 훈련데이터와 테스트 데이터는 일반적으로 이 조건을 충족하지 않습니다. 감정인식은 일반적으로 도메인 간 또는 심지어 언어 간에 이루어 집니다.
At present, the research of machine learning is on the premise that train sets and test sets belong to the same feature space and have the same distribution. However, train and test data generally do not meet this condition in practical applications. Emotion recognition is usually cross-domain, or even cross-language. - 전이 학습은 한 도메인에서 학습한 지식을 다른 유사한 분야에 적용하여 학습 작업을 줄일 수 있습니다. 한편, annotation에 대한 의존도를 줄여 음성 감정 인식의 성능을 더욱 향상시킬 수 있습니다.
Transfer learning uses the knowledge learned in one domain and apply to another similar field, which can reduce the training work. Meanwhile, reduce the dependence on the annotation data, which can better promote the performance of speech emotion recognition.- annotation data: Annotation data는 감정 인식을 위해 레이블링된 데이터를 의미합니다. 즉, 사람들이 어떤 감정을 표현하고 있는지를 미리 알려준 데이터를 말합니다. 이러한 데이터는 대규모로 수집하기 어렵기 때문에, transfer learning은 이러한 annotation data에 대한 의존도를 낮추면서 성능을 향상시키는 방법으로 제안되었습니다.
- 감정 인식을 위해 레이블링 된 데이터를 수집하는 것은 매우 어렵고 시간이 많이 소요되는 작업입니다. 이러한 데이터를 수집하고 레이블링하는 것은 감정 인식 모델의 성능을 향상시키는 데 중요하지만, 이러한 데이터가 부족하거나 잘못된 레이블링으로 인해 모델의 성능에 부정적인 영향을 미칠 수도 있습니다. 따라서 transfer learning은 다른 유사한 분야에서 학습된 지식을 활용하여 감정 인식 모델의 성능을 향상시키는 방법으로 제안되었습니다. 이를 통해 annotation data에 대한 의존도를 낮추면서도 감정 인식 모델의 성능을 개선할 수 있습니다.
II. Related Work
Transfer Learning
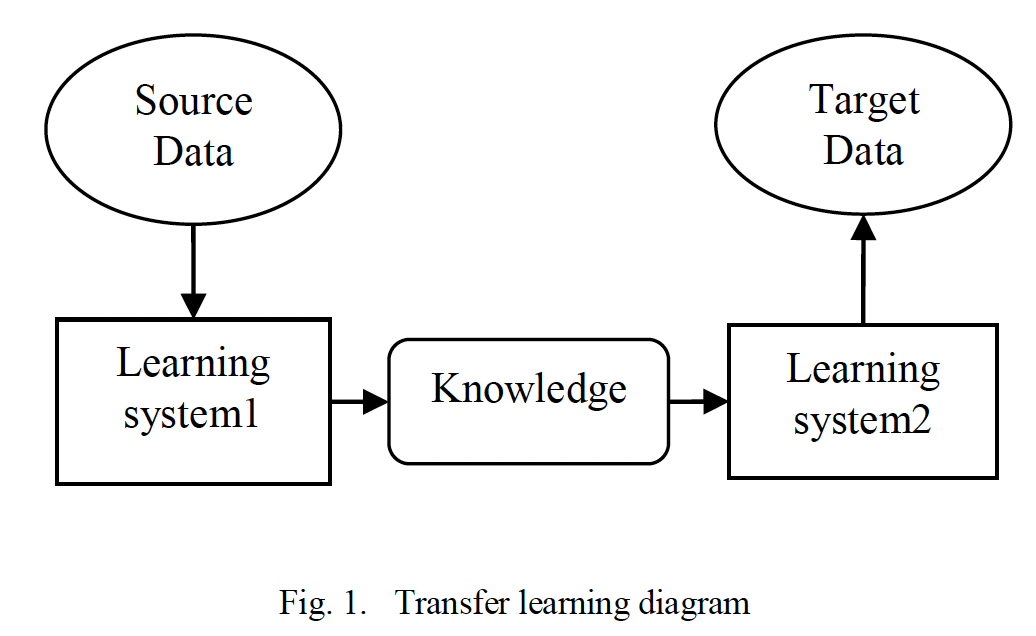

- 전이 학습은 데이터, 과제, 모델에서 두 과제의 유사성을 활용하여 특정 분야에서 학습한 모델을 새로운 분야의 학습 과정에 적용하는 것을 말합니다[14]. 일반적으로 도메인과 태스크는 과제를 설명하는 두 가지 개념입니다. 도메인은 데이터와 데이터 distribution라는 두 가지 구성 요소로 구성됩니다. 또한 태스크에는 레이블 공간과 예측 함수의 두 가지 구성 요소가 있습니다. 함수는 그림 1과 같이 머신러닝을 통해 얻어지며, 지식은 소스 데이터를 사용하여 모델을 학습함으로써 학습됩니다.
Tansfer learning refers to apply a model learned in a certain field to a learning process in a new field utilizing the similarities of two task in data, tasks and models [14]. Usually, Domain and task are two concepts to describe the tasks. A domain consists of two components: data and data distribution. The task also has two components: label space and prediction function. The function is got through machine learning, as shown in Fig.1, the knowledge is learned through training the model using the source data.- 여기서 말하는 데이터 distribution이란, 데이터가 어떻게 분포되어있는지를 의미합니다.
- 예를들어 어떤 회사에서 고객들의 구매 기록을 수집하고 있다고 가정해 봅시다. 이 회사가 보유한 데이터는 고객의 구매 내역, 지불 방법, 배송지 등이 있을 것 입니다.
- 고객의 구매 내역은 상품의 가격, 수량, 카테고리 등으로 이루어져 있으며 이러한 데이터를 일반적으로 연속형 변수로 표현됩니다. 반면에 지불 방법은 신용카드, 현금, 모바일 결제 등으로 이루어져 있으며 범주형 변수로 표현됩니다. 또한 배송지는 지역별로 다른 분포를 가질 수 있으며 이러한 데이터는 지리적인 정보를 포함하므로 공간 데이터로 분류가 될 수 있습니다.
- 이러한 데이터들은 각각 다른 특성과 분포를 가지고 있으며 이러한 특성과 분포를 파악하여 적절한 모델만들어야 합니다.
- Domain은 데이터가 수집된 환경이나 상황을 의미하며, task는 데이터를 이용하여 수행하고자 하는 작업을 의미합니다. 예를 들어, 자율주행 자동차의 경우 도로 주행(domain)과 장애물 회피(task)와 같은 다양한 작업이 있습니다.
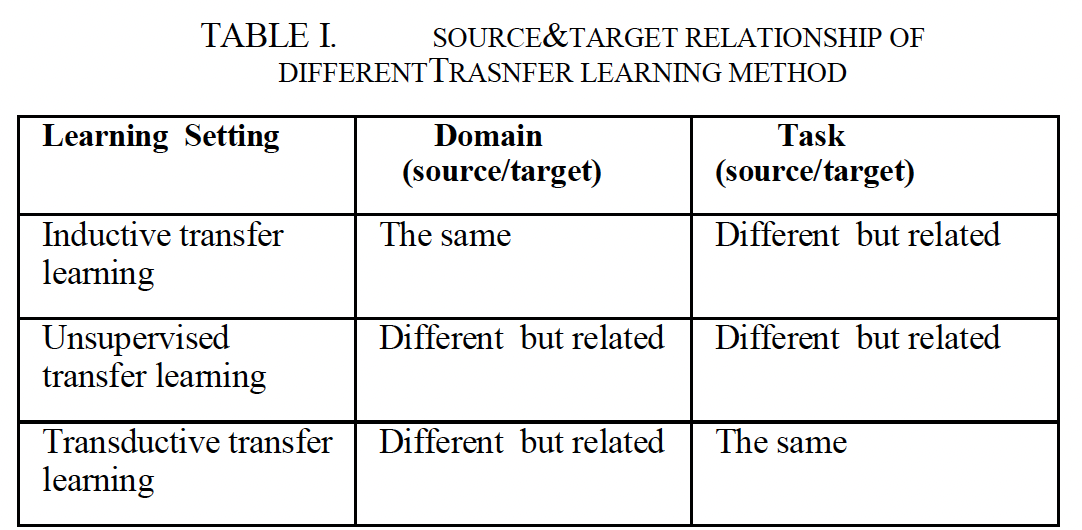
- 목표 과제에 레이블이 지정된 데이터인지 여부에 따라 전이 학습은 귀납적 전이 학습, 전이적 전이 학습 및 비지도 전이 학습의 세 가지 범주로 나눌 수 있습니다.
According to whether the data labeled in the target tasks, transfer learning can divided into the following three categories: inductive transfer learning, transductive transfer learning and unsupervised transfer learning. - Source data: 전이 학습에서 모델을 학습하는 데 사용되는 초기 데이터 세트입니다. 이 데이터 세트는 일반적으로 대규모 데이터 세트에서 가져옵니다.
- Source domain: 소스 데이터가 가져온 도메인입니다. 예를 들어, 소스 데이터가 자연어 처리(NLP) 분야의 텍스트 데이터라면, 소스 도메인은 NLP 분야입니다.
- Source task: 소스 데이터로 수행하는 작업입니다. 예를 들어, 소스 데이터가 감정 분석 작업에 사용된다면, 소스 작업은 감정 분석입니다.
- Target data: 전이 학습에서 새로운 작업을 수행하기 위해 사용되는 추가적인 데이터 세트입니다.
- Target domain: 타겟 데이터가 가져온 도메인입니다. 예를 들어, 타겟 데이터가 의료 분야의 이미지라면, 타겟 도메인은 의료 이미지 분야입니다.
- Target task: 전이 학습에서 수행하려는 새로운 작업입니다. 예를 들어, 타겟 작업이 의료 이미지에서 질병을 감지하는 것이라면, 타겟 작업은 질병 감지입니다.
- target data, target domain, target task는 각각 다른 개념입니다.
- 예를 들어, 소스 도메인은 음악 데이터이고 소스 작업은 음악 장르 분류입니다. 이 경우, 타겟 도메인은 영화 데이터이고 타겟 작업은 영화 장르 분류일 수 있습니다. 여기서 타겟 데이터는 영화 데이터 세트 자체를 의미합니다. 따라서 전이 학습에서는 소스 도메인과 작업에서 학습한 지식을 사용하여 타겟 도메인과 작업에 대한 모델을 구축하고 조정합니다.
- 즉, 전이 학습에서 “target data”는 새로운 데이터 세트를 의미하며 “target domain”은 해당 데이터가 속한 분야 또는 도메인을 나타내며 “target task”는 새로운 작업 또는 문제를 나타냅니다.
- 따라서, 전이 학습에서는 소스 데이터와 소스 도메인에서 모델을 학습한 후, 타겟 데이터와 타겟 도메인에서 모델을 조정하여 새로운 작업을 수행합니다. 이를 위해 finetune 방법과 같은 기술이 사용됩니다.
- 세 전이 학습 모두 source domain에서 학습한 모델을 target domain으로 전이시켜 새로운 task를 수행하는 방법입니다.
- Label space는 모델이 예측하려는 결과값의 집합입니다. 예를 들어, 이메일 분류 모델에서 label space는 “스팸”과 “스팸이 아님”과 같은 두 가지 값으로 구성됩니다.
- Inductive transfer learning은 source domain과 target domain이 서로 다른 label space를 가지고 있을 때 사용됩니다. Inductive transfer learning은 target domain에서 labeled data가 적거나 없는 경우에 유용합니다.
- Transductive transfer learning은 source domain과 target domain이 동일한 label space를 가지고 있을 때 사용됩니다. Transductive transfer learning은 target domain에서 labeled data가 있는 경우에 유용합니다.
- Unsupervised transfer learning은 source domain과 target domain이 동일한 label space를 가지고 있지 않을 때 사용됩니다. Unsupervised transfer learning은 target domain에서 labeled data가 없는 경우에 유용합니다.
- Transfer approach에 따라 네가지 유형의 방법이 있습니다.
- instance-transfer learning: source domain과 target domain이 동일한 feature space를 가지고 있지만, 데이터 분포가 다른 경우에 사용됩니다. 이 방법은 source domain에서 학습한 모델을 target domain으로 전이시켜 새로운 task를 수행하는 방법입니다. 데이터 분포가 다른 경우에도 잘 작동할 수 있습니다.
- The data in the train set will have different weight to show the similarity between source task and target task.
- train set의 데이터는 source task와 target task 간의 유사성을 나타내기 위해 서로 다른 가중치를 가집니다. 이는 source domain과 target domain이 동일한 feature space를 가지고 있지만, 데이터 분포가 다른 경우에 사용되며, 이러한 가중치는 데이터 분포의 차이를 보상하기 위해 사용됩니다.
- feature-representaion transfer learning: source domain과 target domain이 다른 feature space를 가지고 있을 때 사용됩니다. 이 방법은 두 도메인 간의 공통된 feature를 찾아내고, 이를 이용하여 데이터 분포의 차이를 줄이는 방법입니다. 두 도메인 간의 유사성을 찾아내는 것이 중요합니다.
- The feature space of source task and target task are different, both the feature space of the source and the target task will be transformed to a shared subspace.
- 만약 source task와 target task의 feature space가 서로 다르다면, 두 feature space를 공유하는 subspace로 변환시켜야 합니다. 이를 위해 feature-representation transfer learning을 사용합니다.
- parameter-transfer learning: 모델 기반의 transfer learning 방법 중 하나입니다. 이 방법은 먼저 source task에서 모델을 학습시키고, 그 다음 target task에서 모델을 fine-tuning하여 target task에 적용합니다. 하지만 source task와 target task는 서로 다른 데이터 분포를 가지고 있기 때문에, fine-tuning이 필요합니다. 따라서 parameter-transfer learning은 source task와 target task 간의 유사성을 찾아내는 것이 중요합니다.
- Firstly, the model is trained in the source task, and then it can be used in the target task, because of the diffference of the two task, the target task will need finetune.
- relational-knowledge transfer learning: source task와 target task 간의 관계가 유사한 경우, source task에서 학습한 관계를 target task로 전달할 수 있는 transfer learning 방법입니다.
- If there is a relation in the source task is similar to the relation in the target task, then we can transfer the relation from source to target.
- instance-transfer learning: source domain과 target domain이 동일한 feature space를 가지고 있지만, 데이터 분포가 다른 경우에 사용됩니다. 이 방법은 source domain에서 학습한 모델을 target domain으로 전이시켜 새로운 task를 수행하는 방법입니다. 데이터 분포가 다른 경우에도 잘 작동할 수 있습니다.
- 모든 transfer learning 방법은 source task와 target task 간의 유사성을 기반으로 하며, 이 유사성은 feature, parameter, relationship 등 여러 가지 요소들에서 나타날 수 있습니다. 따라서 transfer learning의 핵심은 두 task 간의 유사성을 찾아내는 것입니다.
In summary, each kind of transfer method is on the basic condition, which is the similarity between source and destination task, whether they are features, parameters, or relationships. Therefore, the key to transfer learning is to find the similarities between tasks.- 유사성이 없는 경우에도 transfer learning을 할 수 있지만, 이 경우에는 transfer learning의 성능이 저하될 가능성이 높습니다. 따라서 transfer learning을 적용하기 전에 두 task 간의 유사성을 분석하고, 가능한한 유사한 task를 선택하는 것이 좋습니다.
- transfer learning과 관련하여 언급해야 할 두가지 핵심 이슈는 domain adaption과 task relateness 입니다. There are two key issues to mention about transfer learning: domain adaption and task relateness.
- Domain adaptation
- transfer learning의 한 분야로, source domain과 target domain 간의 차이를 극복하기 위한 방법입니다. 이 방법은 source domain에서 학습한 모델을 target domain에서 적용할 때 발생하는 문제를 해결하기 위해 사용됩니다. 주로 feature space와 class space 간의 차이를 줄이는 것이 목적입니다.
- transfer learning에서 domain adaptation이 필요한 이유: source domain에서는 이미 label이 있는 데이터가 존재하지만, target domain에서는 label이 없는 데이터만 존재하는 경우가 많습니다. 이 때, transfer learning을 사용하여 source domain의 데이터를 활용하여 모델을 학습시키고, 이 모델을 이용하여 target domain의 입력 데이터의 감정 카테고리를 예측하는 것이 목적입니다.
In the source domain the data have label, but the data in the target domain do not have label. Here the objective of transfer learning is to use the data from the source domain to train the model and then use the model to predict the emotion category of the input target data.
- Task relateness
- transfer learning에서 고려해야 할 또 다른 중요한 요소입니다. 이는 source task와 target task 간의 유사성을 의미합니다. 두 task가 유사할수록 transfer learning의 성능이 향상됩니다. 이러한 유사성은 feature, parameter, relationship 등 여러 가지 측면에서 나타날 수 있습니다. 따라서 transfer learning을 적용하기 전에 두 task 간의 유사성을 분석하고, 가능한한 유사한 task를 선택하는 것이 좋습니다.
- 전이 학습에서 작업 간의 유사성은 성공적인 전이를 위한 기초이며, 이 유사성을 찾아 올바르게 사용하는 방법은 핵심적인 문제입니다.
In transfer learning, the similarity between tasks is the basis for successful transfer and how to find and correctly use this similarity is a key issue.
- Domain adaptation
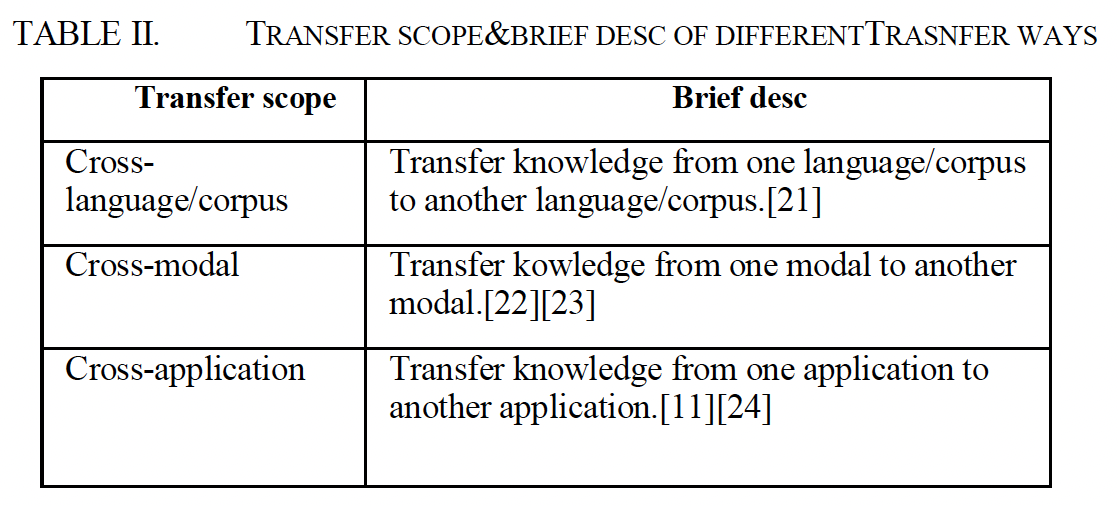
- 음성 감정 인식 연구에는 주로 언어 간, 데이터베이스 간, 모달 간, 애플리케이션 간 전이(예: 음성 인식에서 음성 감정 인식으로의 전이)가 있습니다. 표 II는 전송 범위와 다양한 전송에 대한 간략한 설명을 제공합니다.
In the research of speech emotion recognition, there are mainly cross-language, cross-database, cross-modal, cross-application transfer (for example, transfer from speech recognition to speech emotion recognition). Table II give the transfer scope and the brief description about the different transfer.
III. Transfer Learning Methods For Speech Emotion Recognition
- 음성 감정인식의 특성에 따라 이 분야에서 전이학습의 적용은 두가지 범주로 나뉩니다.
Based on the characteristics of speech emotion recognition, the application of transfer learning in this field mainly has the following two categories
A. Feature based Transfer Learning
- Feature based transfer learning은 source domain과 target domain이 동일한 feature를 공유한다는 가정에 기반하여, 두 domain 간의 차이를 줄이기 위해 feature transformation을 통해 서로 전달하는 방법입니다.
Based on the hypothesis that the source and target domain share the same features, we can use feature based transfer learning. Feature based transfer learning refers to that transfer to each other through feature transformation, to reduce the gap between the source and target domains. - 또 다른 방법으로는 source domain과 target domain의 데이터를 통합된 feature space로 변환한 후 전통적인 기계 학습 방법을 사용하여 분류하는 것입니다.
Other method is to transform the data both in source and target domains into a unified feature space and then use traditional machine learning methods for classification [25]. - Siddique는 연구에서 화자의 얼굴과 음성 간의 관계를 활용하여, 시각적인 영역(faces)에서 표현의 주석(annotation)을 음성 영역으로 전달하여, label이 없는 오디오 데이터 문제를 해결하였습니다. 이러한 방식으로 transfer learning을 적용함으로써, label이 없는 데이터에서도 유용한 정보를 추출할 수 있게 되었습니다.
- Deng는 autoencoder를 사용하여 source domain과 target domain 간에 feature를 전달하는 방법을 제안하였습니다. Autoencoder는 입력 데이터를 압축하고 재생성하는 인공 신경망 구조로, 이를 통해 source domain의 feature들을 압축하고 target domain으로 전달하여, 두 도메인 간의 차이를 줄일 수 있게 됩니다.
- Autoencoder는 입력 데이터를 압축하고 재생성하는 인공 신경망 구조입니다. 이를 통해 source domain의 feature들을 압축하고 target domain으로 전달할 수 있습니다.
- Autoencoder는 두 개의 주요 구성 요소로 이루어져 있습니다. 하나는 인코더(encoder)이고, 다른 하나는 디코더(decoder)입니다. 인코더는 입력 데이터를 저차원의 latent space로 압축하고, 디코더는 latent space에서 원래의 입력 데이터를 재생성합니다.
- 따라서, transfer learning에서 autoencoder를 사용하여 feature transfer를 수행할 때, 먼저 source domain의 데이터를 인코더에 입력하여 latent space로 압축합니다. 그리고 이렇게 압축된 feature들을 디코더를 통해 target domain으로 전달합니다. 이렇게 전달된 feature들은 target domain에서 새로운 모델을 학습하는 데 사용될 수 있습니다.
- 인코더에서 압축되기 전의 feature와 디코더에서 압축되어 나온 feature는 일반적으로 다릅니다. 인코더는 입력 데이터를 저차원의 latent space로 압축하고, 디코더는 이 latent space에서 원래의 입력 데이터를 재구성합니다. 이 과정에서, 인코더는 입력 데이터의 중요한 특징을 추출하고, 디코더는 이러한 특징을 사용하여 입력 데이터를 재구성합니다.
- 따라서, 인코더에서 추출된 feature와 디코더에서 재구성된 feature는 서로 다른 형태를 가지며, 일반적으로 차원이 다릅니다.
B. Model/Parameter based Transfer Learning
- Model based transfer learning은 source domain과 target domain이 모델 파라미터를 공유할 수 있다는 아이디어에 기반합니다. 이 방법은 주로 많은 hidden layer를 가진 딥러닝 모델에서 사용됩니다. 이 방법을 사용하면, source domain에서 학습된 모델 파라미터를 target domain에서 새로운 모델을 학습하는 데 사용할 수 있습니다.
The main idea of model based transfer learning is that the source and target domain can share the model parameters. This method is mainly used in deep learning model, which has many hidden layers [28]. - Zhao는 연령 및 성별 분류 모델을 감정 인식 작업에 전이하는 방법을 제안했습니다. 이 방법은 model based transfer learning의 한 예입니다.
Zhao proposed transfer age and gender classification model to the emotion recogntion task [11].- Zhao는 연령 및 성별 분류 모델을 감정 인식 작업에 전이하는 방법을 제안했습니다. 이 방법은 transfer learning의 한 예입니다. 이 논문에서는 hierarchical deep learning을 사용하여 대규모 음성 데이터에서 연령, 성별 및 감정 카테고리를 예측하는 모델을 학습합니다. 이 모델은 먼저 연령과 성별 속성을 추출하고, 그 다음에 감정 카테고리를 예측합니다.
- 연령과 성별은 감정 카테고리를 예측하는 데에 중요한 특징입니다. 예를 들어, 연령이 어린 사람일수록 행복한 감정을 더 많이 나타내는 경향이 있고, 여성일수록 남성보다 슬픈 감정을 더 많이 나타내는 경향이 있습니다.
- 하지만 연령과 성별만으로는 감정 카테고리를 완벽하게 예측할 수 없습니다. 따라서 이 논문에서는 hierarchical deep learning 모델을 사용하여 입력 데이터에서 다양한 특징을 추출하고, 이를 활용하여 보다 정확한 감정 카테고리를 예측하였습니다.
- 이 논문에서는 transfer learning의 개념을 활용하여, 이미 연령 및 성별 분류 작업에서 학습된 모델 파라미터를 활용하여 감정 인식 작업에 적용하는 방법을 제안합니다. 이를 통해, 적은 양의 labeled data로도 효과적인 감정 인식 모델을 학습할 수 있습니다.
IV. Deep Transfer Learning For Speech Emotion Recognition
- 딥러닝과 전이학습을 결합하면 더 나은 결과를 얻을 수 있습니다. 일반적으로 딥러닝에는 두 가지 방법이 사용됩니다. 하나는 Multi-task learning이고, 다른 하나는 finetune 입니다.
The combination of deep learning and transfer learning can achieve better results. Usually there are two methods used in deep learning. One is multi-task learning and the other is finetune.
A. Multi-Task Learning
- Multi-task learning과 Transfer learning의 차이점과 공통점
- Multi-task learning은 여러 개의 관련된 작업을 함께 학습하는 것을 의미하며, Transfer learning은 knowledge를 source domain에서 target domain으로 전달하는 과정에 중점을 둡니다.
- Multi-task learning은 Transfer learning의 한 유형으로 볼 수 있습니다. Transfer learning의 핵심 문제는 두 작업 간의 유사성을 찾는 것입니다. 이를 찾지 못하면 학습 과정에서 부정적인 영향을 미칠 수 있습니다. 반면, Multi-task learning의 핵심 문제는 related tasks를 찾는 것입니다.
- 따라서, 두 가지 방법 모두 작업 간의 유사성을 찾는 것이 중요합니다.
B. Finetuning
- 먼저 소스 데이터에 대해 모델을 학습시킨 다음, 타겟 데이터를 사용하여 모델을 조정하여 타겟 작업에 적응시키는 것입니다. 소스와 타겟 작업은 상호 연관성이 있지만, 일반적으로 작업의 데이터 분포가 동일하지 않습니다. 따라서 모델은 학습된 소스 모델에 따라 조정되어야 합니다.
- finetune 방법과 전이 학습의 장점
- Finetune 방법은 소스 데이터로부터 모델을 학습한 후, 타겟 데이터를 사용하여 모델을 조정하는 방법입니다. 이 방법은 소스 작업과 타겟 작업 간의 차이를 극복할 수 있으며, 딥 뉴럴 네트워크는 무작위 초기화 가중치보다 더 나은 성능을 보입니다. 이러한 방법은 훈련 시간을 절약하면서도 모델의 일반성과 견고성을 향상시킬 수 있습니다.
- 또한, 사전 훈련(pre-train)이 일반적으로 대규모 데이터 세트에서 수행됩니다. 이렇게 함으로써 훈련 데이터를 확장하여 모델의 일반성과 견고성을 높일 수 있습니다.
V. Conclusions
인공 지능, 사물 인터넷 및 Fog 컴퓨팅의 급속한 발전으로 인해 연구자들의 관심이 높아지고 있다는 것을 언급하며, 전이 학습(transfer learning)이 기계 학습(machine learning)의 중요한 연구 방향 중 하나임을 강조합니다. 이에 따라, 이 논문에서는 전이 학습의 기본 지식, 범주 및 기본적인 방법을 조사하고, 음성 감정 인식에 대한 전이 학습 응용을 연구합니다. 이 응용에서는 실제 작업과 데이터를 분석하여 부정적인 전이를 피하기 위해 주의해야 하며, 전이 학습을 기반으로 하는 다중 모델 감정 인식 및 도메인 적응(domain adaption)은 중요한 주제입니다.