Journal/Conference : IEEE
Year(published year): 2016
Author: Florian Eyben, Klaus R. Scherer, Bjorn W. Schuller, Johan Sundberg, Elisabeth Andre, Carlos Busso, Laurence Y. Devillers, Julien Epps, Petri Laukka, Shrikanth S. Narayanan, and Khiet P. Truong
Subject: Acoustic Parameter Set, eGeMAPS
Summary
- 이 논문은 음성 특징 추출을 위한 최소한의 매개 변수 세트를 제안합니다.
- 제안된 매개 변수 세트는 다양한 감정 분류 작업에서 높은 성능을 보입니다.
- binary arousal 및 binary valence 분류에 대한 요약 결과가 Table 2에 나와 있습니다.
- FAU AIBO를 제외한 모든 데이터베이스와 9개의 최고 SVM 복잡도(C=0.0025)에서 UAR(Unweighted Average Recall)을 평균화합니다.
- 각 화자에 대한 표준화와 균형 잡힌 훈련 세트를 위해 인스턴스 업샘플링이 수행됩니다.
88개 파라미터 정리
기본 GeMAPS, 62개 파라미터
- Pitch
- Jitter
- Formant 1 frequency
- Formant 2 frequency
- Formant 3 frequency
- Formant 1
- Shimmer
- Loudness
- Harmonics-to-noise ratio (HNR)
- Alpha Ratio
- Hammarberg Index
- Spectral Slope 0-500 Hz
- Spectral Slope 500-1500 Hz
- Formant 1 relative energy
- Formant 2 relative energy
- Formant 3 relative energy
- Harmonic difference H1-H2
- Harmonic difference H1-A3
- 위 18개의 산술평균과 변동계수를 적용 -> 36개 + loudness 8가지 함수 추가 적용 파라미터+ pitch 8가지 함수 추가 적용 파라미터 -> 52개
- Alpha Ratio의 산술평균
- Hammarberg Index의 산술평균
- 0-500 Hz 스펙트럼 기울기의 산술평균 (무성음 구간 전체)
- 500-1500 Hz 스펙트럼 기울기의 산술평균 (무성음 구간 전체)
- the rate of loudness peaks
- continuously voiced regions의 평균 길이(F0 > 0)
- continuously voiced regions의 표준편차(F0 > 0)
- unvoiced regions (approximating pauses)의 평균 길이(F0 = 0)
- unvoiced regions (approximating pauses)의 표준편차(F0 = 0)
- continuous voiced regions의 초당 개수 (pseudo syllable rate)
extended GeMAPS(eGeMAPS), 추가 26개 파라미터
- 7개의 LLD에 대해 산술평균과 변동계수 적용 -> 14개의 discriptor 추가
- MFCC 1 (MFCC의 첫번째 계수)
- MFCC 2
- MFCC 3
- MFCC 4
- Spectral flux
- Formant 2 bandwidth
- Formant 2 bandwidth
- 11개의 discriptor가 추가
- 무성영역에서만 spectral flux의 산술 평균
- 유성영역에서만 spectral flux의 산술 평균
- 유성영역에서만 spectral flux의 변동 계수
- 유성 영역에서만 MFCC 1의 변동 계수
- 유성 영역에서만 MFCC 2의 변동 계수
- 유성 영역에서만 MFCC 3의 변동 계수
- 유성 영역에서만 MFCC 4의 변동 계수
- 유성 영역에서만 MFCC 1의 산술 평균
- 유성 영역에서만 MFCC 2의 산술 평균
- 유성 영역에서만 MFCC 3의 산술 평균
- 유성 영역에서만 MFCC 4의 산술 평균
- equivalent soud level
- 이렇게 하면 확장된 파라미터에는 14+11+1 26개의 파라미터가 추가 됨
- 7개의 LLD에 대해 산술평균과 변동계수 적용 -> 14개의 discriptor 추가
0.abstract
- GeMAPS는 음성과 감정 컴퓨팅 분야에서 사용되는 기본 표준 음향 파라미터 세트입니다.
- 이 세트는 다양한 자동 음성 분석 영역에 적용될 수 있습니다.
- GeMAPS는 감정적 생리적 변화를 색인화하는 데 잠재력이 있습니다.
- 이전 연구에서 입증된 가치와 이론적 중요성을 가지며, 자동 추출 가능합니다.
- GeMAPS는 미래 연구 평가의 공통 기준을 제공하고, 다른 파라미터 세트 또는 동일한 파라미터의 다른 구현으로 인한 차이를 제거하기 위해 만들어졌습니다.
1. Introduction
- 이 단락에서는 다양한 감정 상태의 음성 표현에 대한 관심이 오랫동안 지속되어 왔으며, 다양한 분야의 연구자들이 이 주제에 대해 연구해 왔다고 설명합니다.
- 정신과 의사는 감정 상태를 진단하기 위해 노력해 왔으며, 심리학자와 커뮤니케이션 연구자들은 감정의 신호를 전달하는 목소리의 능력을 탐구해 왔습니다.
- 언어학자와 음성학자들은 언어 생산과 지각에서 정서적 실용적 정보의 역할을 발견해 왔습니다.
- 최근에는 컴퓨터 과학자와 엔지니어들이 화자의 태도와 감정을 자동으로 인식하고 조작하여 인간 사용자가 정보 기술에 더 쉽게 접근하고 신뢰할 수 있도록 하려는 시도를 하고 있습니다.
- 이러한 연구의 대부분은 음성 신호에서 음향 매개변수를 추출하여 다양한 감정과 기타 정서적 성향이 발성 패턴을 통해 어떻게 표현되는지 이해하는 방법을 사용합니다.
- 기본 이론적 가정은 정서적 과정으로 인한 자율신경 흥분과 근육 긴장의 변화를 음향 파형의 다양한 파라미터로 추정할 수 있다는 것입니다.
- GeMAPS는 음성과 감정 컴퓨팅 분야에서 사용되는 기본 표준 음향 파라미터 세트로, 이전 연구에서는 다양한 파라미터들이 사용되었지만 일관된 방식으로 추출되지 않았습니다. 따라서 GeMAPS는 다양한 자동 음성 분석 영역에 적용될 수 있는 기본 표준 세트로서, 감정적 생리적 변화를 색인화하는 데 잠재력이 있으며, 이전 연구에서 입증된 가치와 이론적 중요성을 가지고 있습니다.
2.Related Work
- CEICES는 더 엔지니어링 중심적인 “수집기(collector)” 접근 방식으로, 분류 실험에서 성공적인 파라미터들을 모두 포함합니다. 반면, GeMAPS는 다양한 출처의 교차학제적 증거와 이론적 중요성 또는 몇 가지 파라미터를 기반으로 하는 최소한의 파라미터 세트를 합의하는 보다 교차학제적인 시도입니다.
- 초기 조사[15]와 최근 개요[17]는 정서적 음성 연구에 관한 수십 년간의 심리학 문헌을 잘 요약하고 있으며, 제시된 경험적 데이터를 통해
- 강도(음량)
- F0(기본 주파수) 평균
- 변동성 및 범위
- 음성 신호의 고주파 콘텐츠/에너지가 스트레스(강도, F0 평균)
- 분노 및 슬픔(모든 매개변수)
- 지루함(F0 변동성 및 범위)과 같은 전형적인 음성 정서 표현과 상관관계를 보인다는 결론을 내렸습니다.
- speech와 articulation rate은 감정표현에 영향을 미치지 않는다는 것으로 나타났습니다.
- [16]은 F0 및 스펙트럼 분포와 관련된 매개변수가 감정적 발화 내용에 대한 중요한 단서임을 확인함
- [17]과 같이 대부분의 연구는 청각적 감정분석을 다루며 accoustic arousal에 대한 단서인 상당히 일관된 매개변수를 보고함
- [24]에 보면, 그냥 음량을 측정하는거보다 다양한 주파수 대역의 신호에너지에 human-hearing’s frequency sensitivity에 따라 가중치를 부과하면 vocal affect dimension과 더 많은 상관관계가 있는 것으로 나타났음. 또한 spectral flux가 단일 피처에 대해 전반적으로 가장 높은 상관관계를 보였음.
- [17],[25] : particular valence(감정의 긍정성 또는 부정성을 나타내는 지표)
- [25]에서는 LOI(Level of Interest, 대화 참여자의 관심 수준을 나타내는 지표입니다. LOI는 boredom(지루함), overneutral(중립), joyful interaction(즐거운 상호작용)으로 구분) 같은 경우 MFCC의 중요성이 크다는 것을 보여줌, lower order MFCC는 스펙트럼 전체범위(first coefficient, 첫번째 계수) 또는 다양한 작은 sub-bands(second and higher coefficient, 두번째 및 상위계수)에서 어느정도 spectral tilt(slope)를 측정합니다.
- spectral slope(Spectral slope는 주파수 대역에서 파워 스펙트럼의 기울기를 나타내는 지표입니다. 이 논문에서는 0-500 Hz 및 500-1500 Hz 대역에서의 스펙트럼 기울기를 계산하는 방법에 대해 설명하고 있습니다. 이러한 스펙트럼 기울기는 음성 특징 추출 및 음성 감정 인식과 같은 다양한 연구 분야에서 사용됩니다.)
- 이 연구의 목표는 이전의 관련 연구 결과에 따라 관련 파라미터를 선택하는 것
- 많은 automatically extracted brute-force 파라미터 세트는 formant 파라미터를 안정적으로 추출하기 어렵기 때문에 이를 무시하지만, voice research and automatic classification를 위해서는 formant 파라미터가 매우 중요.
- formant는 다양한 형태의 감정과 정신상태에 민감한 것으로 나타났으며 거의 sota 수준의 cognitive load classification result[27]와 우울증 인식 및 평가 결과[31],[38]를 제공하며 다른 시스템의 feature dimension에 비해 훨씬 적은수의 formant로도 경쟁력 있는 감정인식 성능을 제공할수 있기 때문
- cognitive load: 인간의 인지 능력이 처리해야 하는 정보의 양과 복잡성에 따라 발생하는 정신적인 부담을 의미
- 그래서 이 논문에 제안된 파라미터세트에는 formant도 포함되어 있음.
- fundamental frequency(기본 주파수[6])와 진폭/강도의 중요성이 입증되었기 때문에, 강력한 fundamental frequency 측정과 pseudo-auditory loudness(유사 청각적 음량) 측정이 제안된 세트에 포함되어 있습니다.
- 분포 변화를 포착하기 위해 시간에 따른 다양한 통계가 두 매개변수에 적용됩니다.
- 고주파 콘텐츠와 스펙트럼 밸런스를 강력하게 표현하기 위해 alpha 비율, Hammerberg 지수, 스펙트럼 기울기를 설명자로 고려합니다.
- Alpha Ratio는 음성 신호의 저주파 대역과 고주파 대역 간의 에너지 비율을 나타내는 지표입니다. 이 논문에서는 Alpha Ratio가 50-1000 Hz와 1-5 kHz 대역에서의 에너지 합의 비율로 정의되며, Hammarberg index와 유사한 방식으로 계산됩니다.
- Hammarberg index는 음성 신호의 저주파 대역과 고주파 대역 간의 에너지 비율을 나타내는 지표입니다. 이 논문에서는 Hammarberg index가 0-2 kHz와 2-5 kHz 대역에서 가장 큰 에너지 피크 간의 비율로 정의되며, 고정된 pivot point인 2 kHz를 기준으로 계산
- vocal timbre(보컬 음색)은 MFCC로 인코딩되고, F0의 period-to-period jitter와 shimmer를 사용하여 음성 발화 신호의 질을 평가.
- Vocal timbre는 음성의 톤 색깔이나 음색을 나타내는 용어
- F0의 period-to-period jitter와 shimmer는 음성 발화 신호의 안정성과 규칙성을 나타내는 지표입니다. Jitter는 연속된 F0 주기 간 최고점의 차이를 나타내며, shimmer는 연속된 F0 주기 간 최고점의 크기 차이를 나타냅니다. 이러한 지표들은 음성 발화 신호의 질을 평가하는 데 사용
- 모음 기반 음성 연구를 허용하고 특정 작업에 대한 관련성이 입증된 formant 파라미터도 세트에 포함되어 있습니다.
3.Acoustic Parameter Recommendation
- 여기에 제시된 권장 사항은 제네바에서 열린 음성 및 언어 과학자들의 학제 간 회의에서 고안되었으며 뮌헨공과대학교(TUM)에서 더욱 발전시켰습니다.
- 세가지 기준에 따라 매개변수의 선택이 이루어졌음
- 정서적 과정 중 음성 생성의 생리적 변화를 지표화 할수 있는 음향 매개변수의 잠재력
- voice production 과정에서 감정적 변화가 생기면서 생리학적 변화를 나타내는 음향 파라미터의 potential.
- 과거 문헌에서 해당 매개변수가 사용된 빈도 및 성공 여부(related works 참조)
- 이론적 중요성([1],[2])
- 정서적 과정 중 음성 생성의 생리적 변화를 지표화 할수 있는 음향 매개변수의 잠재력
- 두가지 버전의 acoustic parameter set가 권장됨
- 저자의 이전 연구에서 가장 중요한 것으로 밝혀진 prosodic, excitation, vocal tract, and spectral descriptors를 구현하는 최소한의 파라미터 세트
- 문학([40])에서 pure prosodic 및 스펙트럼 마라미터 세트보다 automatic affect recognition의 정확도를 높이는 것으로 일관되게 알려진 소량의 cepstral descriptors를 포함하는 최소한의 세트에 대한 확장
- 제안하는 음향 파라미터 세트: 여기서는 두 가지 버전의 음향 파라미터 세트를 제안하고 있습니다. 첫 번째는 저자들의 이전 연구에서 가장 중요하다고 판단된 prosodic, excitation, vocal tract 및 spectral descriptors를 구현한 최소한의 파라미터 세트입니다. 두 번째는 최소한의 파라미터 세트에 cepstral descriptors를 추가한 확장된 버전입니다. 이러한 cepstral descriptors는 [40]과 같은 literature에서 자주 언급되며, 순수한 prosodic 및 spectral parameter set보다 자동 감정 인식의 정확도를 높이는 것으로 알려져 있습니다.
- 자동 파라미터 선택에 대한 연구 결과와 MFCCs의 기본 함수에 대한 설명, [23], [24]와 같은 자동 파라미터 선택에 관한 연구들은, 감정 및 언어적 음성 분석 작업에서 낮은 차수의 MFCCs가 더 중요하다는 것을 시사합니다. MFCCs를 계산할 때 사용되는 이산 코사인 변환(DCT-II) 기본 함수를 살펴보면, 낮은 차수의 MFCCs가 스펙트럼 기울기와 스펙트럼 에너지의 전체 분포와 관련이 있다는 것이 분명합니다. 높은 차수의 MFCCs는 보다 정교한 에너지 분포를 반영하며, 음성 속성(non-verbal voice attribute)보다는 음운 내용(phonetic content)을 식별하는 데 더 중요할 것으로 추정됩니다.
3.1 Minimalistic Parameter Set
- 18개의 Low-Level descriptors
- Frequency related parameters
(1~6):- Pitch, logarithmic F0 on a semitone frequency scale, starting at 27.5 Hz (semitone 0).
- 피치, 27.5Hz(반음 0)에서 시작하는 반음 주파수 스케일에서 로그 F0입니다.
- 이 문장은 F0 값에 대한 설명입니다. F0 값은 음성 신호에서 기본 주파수를 나타내며, 이 값은 세미톤 주파수 스케일에서 로그함수로 변환됩니다. 이 스케일은 27.5 Hz (세미톤 0)에서 시작하며, 각 세미톤 간의 주파수 차이는 2^(1/12)로 계산됩니다. 따라서, 예를 들어, 세미톤 1은 29.136 Hz이고, 세미톤 2는 30.868 Hz입니다. 이러한 변환을 통해 F0 값을 보다 직관적으로 이해할 수 있습니다.
- Jitter, deviations in individual consecutive F0 period lengths.
- 지터는 개별 연속 F0 주기 길이의 편차입니다.
- 이 문장은 음성 파라미터 중 하나인 Jitter에 대한 설명입니다. Jitter는 연속적인 F0 주기의 길이에서 발생하는 변동을 나타내는 지표입니다. 즉, F0 주기의 길이가 일정하지 않고 변동이 크면 Jitter 값이 높아집니다. 이러한 변동은 음성 신호에서 발생하는 국소적인 성대 운동 불규칙성으로 인해 발생할 수 있습니다. Jitter 값은 음성 장애 진단 및 감정 분석 등에 사용됩니다.
- Formant 1 frequency,
- Formant 2 frequency,
- Formant 3 frequency, centre frequency of first, second, and third formant
- 1,2,3 번째 formant의 중심 주파수
- Formant 1, bandwidth of first formant.
- 첫번째 formant의 중심 파라미터
- Pitch, logarithmic F0 on a semitone frequency scale, starting at 27.5 Hz (semitone 0).
- Energy/Amplitude related parameters
(7~9):- Shimmer, difference of the peak amplitudes of consecutive F0 periods.
- 쉬머는 연속된 F0 기간의 피크 진폭의 차이입니다.
- 이 문장은 음성 파라미터 중 하나인 Shimmer에 대한 설명입니다. Shimmer는 연속적인 F0 주기에서 peak amplitude의 차이를 나타내는 지표입니다. 즉, F0 주기에서 peak amplitude의 차이가 크면 Shimmer 값이 높아집니다. 이러한 변동은 음성 신호에서 발생하는 국소적인 성대 운동 불규칙성으로 인해 발생할 수 있습니다. Shimmer 값은 음성 장애 진단 및 감정 분석 등에 사용됩니다.
- Loudness, estimate of perceived signal intensity from an auditory spectrum.
- 청각 스펙트럼에서 감지된 신호강도의 estimate
- Harmonics-to-noise ratio (HNR), relation of energy in harmonic components to energy in noise-like components.
- Harmonics 대 잡음비(HNR)는 Harmonics 성분의 에너지와 잡음 성분의 에너지를 고조파 성분의 에너지와 잡음 성분의 에너지의 관계입니다.
- 이 문장은 음성 파라미터 중 하나인 Harmonics-to-noise ratio (HNR)에 대한 설명입니다. HNR은 음성 신호에서 harmonic components와 noise-like components 간의 에너지 비율을 나타내는 지표입니다. 즉, HNR 값이 높을수록 음성 신호에서 harmonic components의 비중이 높아지고, HNR 값이 낮을수록 noise-like components의 비중이 높아집니다. 이러한 지표는 음성 신호에서 발생하는 잡음과 왜곡 등을 분석하고, 음성 장애 진단 및 감정 분석 등에 사용됩니다.
- Shimmer, difference of the peak amplitudes of consecutive F0 periods.
- Spectral (balance) parameters
(10~18):- Alpha Ratio, ratio of the summed energy from 50-1000 Hz and 1-5 kHz
- 50-1000Hz, 1-5kHz에서 합산된 에너지의 비율
- 음성 신호의 저주파 대역과 고주파 대역 간의 에너지 비율을 나타내는 지표
- Alpha Ratio는 저주파 영역과 고주파 영역의 에너지 비율을 나타내는 파라미터입니다. 구체적으로, 50-1000 Hz와 1-5 kHz에서의 총 에너지 비율을 나타냅니다.
- Alpha Ratio는 음성 신호의 성질을 분석하는 데 사용됩니다. 예를 들어, Alpha Ratio가 높은 경우 저주파 성분이 많은 음성 신호일 가능성이 높습니다. 이러한 정보는 음성 질환 진단 및 치료에 유용하게 사용될 수 있습니다.
- Hammarberg Index, ratio of the strongest energy peak in the 0-2 kHz region to the strongest peak in the 2–5kHz region.
- 0-2kHz 영역에서 가장 강한 에너지 피크와 2-5kHz 영역에서 가장 강한 피크의 비율
- 이 문장은 음성 파라미터 중 하나인 Hammarberg Index에 대한 설명입니다. Hammarberg Index는 음성 신호에서 0-2 kHz 영역과 2-5 kHz 영역에서 가장 강한 에너지 peak 간의 비율을 나타내는 지표입니다. 즉, Hammarberg Index 값이 높을수록 0-2 kHz 영역에서의 에너지 peak가 높아지고, Hammarberg Index 값이 낮을수록 2-5 kHz 영역에서의 에너지 peak가 높아집니다. 이러한 지표는 음성 신호에서 발생하는 고음과 저음 등을 분석하고, 음성 장애 진단 및 감정 분석 등에 사용됩니다.
- Spectral Slope 0-500 Hz
- Spectral Slope 500-1500 Hz, linear regression slope of the logarithmic power spectrum within the two given bands.
- 0-500 Hz 과 500-1500 Hz, 주어진 두 대역 내에서 로그 파워 스펙트럼의 선형 회귀 기울기
- 이 문장은 음성 파라미터 중 하나인 Spectral Slope 0-500 Hz and 500-1500 Hz에 대한 설명입니다. Spectral Slope는 주어진 두 개의 주파수 범위 (0-500 Hz 및 500-1500 Hz) 내에서 로그 스케일의 파워 스펙트럼의 선형 회귀 기울기를 나타내는 지표입니다. 즉, Spectral Slope 값이 높을수록 파워 스펙트럼이 빠르게 감소하고, Spectral Slope 값이 낮을수록 파워 스펙트럼이 천천히 감소합니다. 이러한 지표는 음성 신호에서 발생하는 저역대와 고역대의 에너지 분포를 분석하고, 음성 장애 진단 및 감정 분석 등에 사용됩니다.
- 파워 스펙트럼은 시간 도메인의 신호를 주파수 도메인으로 변환한 것입니다. 즉, 파워 스펙트럼은 주파수별로 신호의 에너지를 나타내는 그래프입니다. 파워 스펙트럼을 계산하면 주파수 영역에서 신호의 성분을 분석할 수 있습니다. 이러한 분석은 음성 인식, 음성 합성, 음성 변조 및 음성 감정 분석 등에 사용됩니다.
- Formant 1 relative energy
- Formant 2 relative energy
- Formant 3 relative energy, as well as the ratio of the energy of the spectral harmonic peak at the first, second, third formant’s centre frequency to the energy of the spectral peak at F0.
- Formant 1, 2, 3 상대 에너지는 첫 번째, 두 번째, 세 번째 포먼트의 중심 주파수에서 spectral harmonic peak의 에너지와 F0에서 spectral peak의 에너지의 비율입니다.
- Harmonic difference H1-H2, ratio of energy of the first F0 harmonic (H1) to the energy of the second F0
harmonic (H2).- 첫 번째 F0 Harmonic(H1)의 에너지와 두 번째 F0 Harmonic(H2)의 에너지 둘 사이의 비율입니다.
- Harmonic difference H1-A3, ratio of energy of the first F0 harmonic (H1) to the energy of the highest
harmonic in the third formant range (A3).- Harmonic 차이 H1-A3은 첫 번째 F0 harmonic(H1)의 에너지와 세 번째 formant 범위(A3)에서 가장 높은 harmonic의 에너지의 비율입니다.
- 첫 번째 F0 harmonic(H1)와 세 번째 formant 에너지(A3) 비율을 계산
- Alpha Ratio, ratio of the summed energy from 50-1000 Hz and 1-5 kHz
- Frequency related parameters
- LLD(Low-Level Descriptors)는 음성 신호에서 추출된 저수준 특징을 나타내는 지표입니다.
- 이러한 지표들은 시간에 따라 변화하므로, 3 프레임 길이의 대칭 이동 평균 필터(symmetric moving average filter*)*를 사용하여 시간적으로 smoothing(평활화)됩니다.
- smoothing은 발성 영역 내에서만 수행되기 때문에 pitch, jitter 및 shimmer와 같은 경우, 0(무성음)에서 0이 아님으로의 전환은 smoothing하지 않습니다.
- Smoothing은 시계열 데이터에서 잡음이나 불규칙성을 제거하고, 데이터의 전반적인 추세를 부드럽게 만드는 기술입니다. 이를 위해 대표적으로 이동 평균 필터와 같은 필터링 기법이 사용됩니다. 이동 평균 필터는 일정한 길이의 윈도우를 설정하고, 해당 윈도우 내의 데이터들의 평균값을 구하여 각각의 데이터에 대해 적용하는 방식으로 smoothing을 수행합니다.
- 이러한 LLD에 대해 산술평균(arithmetic mean)과 변동 계수 (coefficient of variation, 표준 편차를 산술 평균으로 정규화 한 것)가 모든 18개의 LLD에 대해 적용되어
36개의 파라미터가 생성됩니다.- 음성 파라미터 추출 과정에서 LLD에 대한 통계적인 지표 계산 방법
- 산술평균은 각 LLD의 값들을 모두 더한 후, LLD의 개수로 나누어 평균값을 구하는 것입니다.
- 변동 계수는 표준 편차를 산술 평균으로 정규화하여, 데이터의 변동성을 상대적으로 비교할 수 있는 지표입니다.
- 이러한 산술평균과 변동 계수를 각각 18개의 LLD에 대해 적용하여, 36개의 파라미터가 생성됩니다.
- 음성 파라미터 추출 과정에서 LLD에 대한 통계적인 지표 계산 방법
- 음량과 피치에는 20번째, 50번째, 80번째 백분위수, 20~80번째 백분위수 범위, 상승/하강 신호 부분의 기울기 평균과 표준편차 등
8가지 함수가 추가로 적용됩니다.- 이 문장은 음성 파라미터 추출 과정에서 음량과 피치에 대해 적용되는 추가적인 함수들에 대한 설명입니다. 이러한 함수들은 20번째, 50번째, 80번째 백분위수, 20~80번째 백분위수 범위, 상승/하강 신호 부분의 기울기 평균과 표준편차 등 총 8가지 함수로 구성됩니다. 이러한 함수들은 음성 신호에서 추출된 저수준 특징을 더욱 상세하게 분석하기 위해 사용됩니다. 예를 들어, 백분위수는 데이터의 분포를 파악하는 데 사용되며, 상승/하강 신호 부분의 기울기 평균과 표준편차는 음성의 강도나 높낮이 변화를 분석하는 데 사용됩니다. 이러한 파라미터들은 음성 인식 및 감정 분석 등 다양한 분야에서 활용됩니다.
- 20,50,80 번째 백분위수: 각각 전체 데이터의 20%, 50%, 80%에 해당하는 값을 의미합니다. 예를 들어, 만약 어떤 데이터 집합에서 50번째 백분위수가 10이라면, 이는 해당 데이터 집합에서 중간값(median)이 10이라는 것을 의미합니다. 이러한 백분위수들은 데이터의 분포를 파악하고, 대표값을 추정하는 데 사용됩니다. 따라서 음성 신호에서 추출된 파라미터들에 대해 적용되는 백분위수들은 해당 파라미터들의 분포를 파악하고, 대표값을 추정하는 데 사용
- 상승/하강 신호 부분의 기울기 평균과 표준편차: 음성 신호에서 추출된 파라미터들 중 하나로, 음성의 강도나 높낮이 변화를 분석하는 데 사용됩니다. 이러한 파라미터는 상승/하강 신호 부분에서의 기울기를 계산하여, 해당 구간에서의 음성 변화 정도를 나타내는 지표입니다. 기울기 평균은 해당 구간에서의 기울기 값들을 모두 더한 후, 구간 길이로 나누어 평균값을 구하는 것이며, 표준편차는 해당 구간에서의 기울기 값들의 흩어진 정도를 나타내는 지표입니다. 이러한 파라미터들은 음성 인식 및 감정 분석 등 다양한 분야에서 활용
- 상승/하강 신호 부분의 기울기 구하는 방법: 상승/하강 신호 부분의 기울기는 일반적으로 미분을 통해 구합니다. 음성 신호에서는 일반적으로 Short-Time Energy(STE) 또는 Zero Crossing Rate(ZCR)와 같은 저수준 특징을 사용하여, 상승/하강 신호 부분을 검출한 후, 해당 구간에서의 기울기를 계산합니다. 예를 들어, STE를 사용하여 음성 신호에서 상승/하강 신호 부분을 검출한 후, 해당 구간에서의 기울기를 계산하기 위해서는 해당 구간 내 STE 값들의 차이를 계산하여, 이를 구간 길이로 나누어 기울기 값을 얻을 수 있습니다.
- loudness에 적용되는 함수들을 제외한 모든 함수는 음성영역(F0가 0이 아닌것)에서만 적용됨.
- 이렇게
36개 파라미터 + loudness 8가지 함수 추가 적용 파라미터 + pitch 8가지 함수 추가 적용 파라미터 = 52개의 파라미터가 최종 - 또한 모든 무성음 세그먼트에 대한 알파 비율의 산술 평균, 하마버그 지수, 0-500Hz 및 500-1500Hz의 스펙트럼 슬로프가 포함되어
총 56개의 파라미터가 있습니다. 또한 6개의 시간적 특징이 포함되어 있습니다.- Alpha Ratio의 산술평균
- Hammarberg Index의 산술평균
- 0-500 Hz 스펙트럼 기울기의 산술평균 (무성음 구간 전체)
- 500-1500 Hz 스펙트럼 기울기의 산술평균 (무성음 구간 전체)
- 음성 신호에서 voiced 또는 unvoiced 구간의 최소 길이가 정해져 있지 않으므로 이러한 구간이 한 프레임만큼 짧을 수도 있다. 그러나 F0 contour의 Viterbi-based smoothing은 에러로 인해 단일 voiced frame이 누락되는 것을 효과적으로 방지합니다.
- the rate of loudness peaks: 음성 신호에서 초당 loudness peak의 수를 나타내는 파라미터
- continuously voiced regions의 평균 길이(F0 > 0),
- continuously voiced regions의 표준편차(F0 > 0),
- unvoiced regions (approximating pauses)의 평균 길이(F0 = 0),
- unvoiced regions (approximating pauses)의 표준편차(F0 = 0),
- continuous voiced regions의 초당 개수 (pseudo syllable rate)
- 음성 신호에서 연속적으로 발생하는 voiced 구간의 개수를 초당 단위로 나타내는 파라미터입니다. 이러한 파라미터는 음성 신호에서 발생하는 언어적인 정보를 추출하는 데 사용
- 파라미터들은 음성 신호에서 발생하는 pause나 강세 등과 같은 다양한 정보를 추출하는 데 사용
3.2 Extended Parameter Set
- 3.1의 파라미터에는 cepstral parameter나 dynamic parameter가 거의 들어가지 않음
- Cepstral parameter는 음성 신호의 주파수 특성을 분석하는 데 사용되는 파라미터입니다. 이러한 파라미터는 Mel-Frequency Cepstral Coefficients (MFCCs)와 같은 변환을 통해 추출됩니다. MFCCs는 음성 신호를 일련의 주파수 대역으로 분할하고, 각 대역에서 적절한 계수를 추출하여 구성됩니다. 이러한 계수들은 음성 신호의 주파수 특성을 잘 나타내며, 음성 인식 및 감정 인식과 같은 다양한 어플리케이션에서 유용하게 사용됩니다.
- Dynamic parameter는 시간적인 변화를 나타내는 파라미터입니다. 이러한 파라미터는 음성 신호의 동적인 특징을 분석하는 데 사용됩니다. 예를 들어, Delta 및 Delta-Delta 계수와 같은 동적 파라미터는 MFCCs와 같은 정적 파라미터에 추가하여 사용됩니다. 이러한 동적 파라미터는 음성 신호의 빠른 변화를 잘 나타내며, 음성 인식 및 감정 인식과 같은 다양한 어플리케이션에서 유용하게 사용됩니다.
- 즉, 이 minimal Parameter Set은 Delta 회귀 계수 및 차이 특징과 같은 동적 파라미터를 포함하지 않습니다. 대신, 상승 및 하강하는 F0와 음량 세그먼트의 기울기만이 일부 동적 정보를 포함합니다.
- 즉, 이 Parameter Set에서는 두 개의 연속된 프레임 간 차이를 나타내는 파라미터가 포함되어 있지 않으며, 상승 및 하강하는 F0와 음량 세그먼트의 기울기만이 일부 동적 정보를 추출할 수 있는 파라미터로 사용됩니다.
- [23],[40],[41]에서는 affective state를 모델링하는데 cepstral 파라미터가 매우 성공적인 것으로 입증되었다.
- 따라서 확장된 set에서는 minimalistic set에 추가로
7개의 LLD를 포함하는 것으로 제안함- Spectral (balance/shape/dynamics) parameters:
- MFCC 1 (MFCC의 첫번째 계수)
- MFCC 2
- MFCC 3
- MFCC 4, Mel-Frequency Cepstral Coefficients 1-4.
- MFCC는 여러 개의 계수로 구성됩니다. 일반적으로 MFCC는 12개에서 40개까지의 계수를 사용합니다. 이러한 계수는 음성 신호에서 추출된 특징을 나타내며, 일반적으로 음성 인식, 감정 인식 및 화자 인식과 같은 작업에 사용됩니다. 더 낮은 순서의 MFCC는 주파수 스펙트럼의 기울기와 전체 스펙트럼 에너지 분포와 관련이 있으며, 더 높은 순서의 MFCC는 보다 세부적인 에너지 분포를 나타냅니다. 이러한 다양한 계수를 조합하여 음성 처리 작업에서 보다 정확한 결과를 얻을 수 있습니다.
- Spectral flux, difference of the spectra of two consecutive frames.
- Spectral flux는 음성 신호의 스펙트럼 변화를 측정하는 파라미터 중 하나입니다. 이 파라미터는 연속된 프레임 간 스펙트럼 차이의 제곱합을 계산하여 구합니다. 이러한 계산은 음성 신호의 주파수 성분이 얼마나 빠르게 변화하는지를 나타내며, 음성 신호의 에너지 분포가 어떻게 변화하는지를 추적할 수 있습니다. Spectral flux는 음성 인식 및 감정 인식과 같은 다양한 어플리케이션에서 유용하게 사용
- Frequency related parameters:
- Formant 2 bandwidth
- Formant 3 bandwidth, added for completeness of
Formant 1-3 parameters.- Formant 1-3 파라미터의 완성도를 위해 Formant2,3 대역폭이 추가
- Spectral (balance/shape/dynamics) parameters:
- 함수로써 산술평균과 변동계수는 이 7가지 추가 LLD에 모두 적용됨. 세그먼트(유,무성 모두)를 포함하여 유성영역에만 함수가 적용되는 대역폭은 제외됨. → 최종적으로
14개의 discriptor가 추가가 됨 - 또한 무성 영역에서만 spectral flux의 산술 평균, 유성영역에서만 spectral flux의 산술 평균과 변동 계수 및 MFCC 1-4가 포함됨. → 이 결과
11개의 discriptor가 추가됨. - 추가적으로 equivalent soud level이 포함됨.
- Equivalent sound level (LEq)은 프레임당 RMS 에너지의 평균값을 로그 스케일로 변환하여 계산됩니다. 이를 통해 음성 신호의 평균적인 에너지 레벨을 측정할 수 있습니다. LEq는 주로 소음 및 음향 관련 어플리케이션에서 사용되며, 음성 감정 인식과 같은 분야에서도 유용하게 사용됩니다.
- RMS (Root Mean Square) 에너지 평균값은 음성 신호의 에너지를 측정하는 방법 중 하나입니다. 이 값은 각 프레임에서 음성 신호의 진폭 값을 제곱한 후, 평균을 구한 값입니다. RMS 에너지는 음성 신호의 전체적인 에너지 레벨
- 이렇게 하면 총
26개의 추가 파라미터가 생성 - 결과적으로 extended Geneva Minimalistic Acoustic Parameter Set(eGeMAPS)는 88개의 파라미터가 포함되어 있음.
4.Baseline Evaluation
- 위에서 제안된 두가지 파라미터세트는 각각 binary arousal와 binary valence dimensions에서 자동 인식 작업을 수행하기 위해 평가되었습니다. 이를 위해, 여러 가지 감정적인 음성 데이터베이스에서 제공된 원래 라벨을 binary dimensional labels (Arousal/Valence)로 매핑하여 사용하였습니다.
- Binary arousal와 binary valence dimensions는 감정 인식 분야에서 사용되는 두 가지 이진 차원입니다. Arousal 차원은 감정의 활성화 수준을 나타내며, 낮은 수준의 활성화는 침착하고 집중력이 높은 상태를 나타내고, 높은 수준의 활성화는 흥분하거나 공포와 같은 강한 감정을 나타냅니다. Valence 차원은 감정의 긍정성/부정성 정도를 나타내며, 긍정적인 감정은 높은 valence 값을 가지고 부정적인 감정은 낮은 valence 값을 가집니다. 이러한 이진 차원들을 사용하여 음성 신호에서 특정한 감정을 자동으로 인식하는 작업이 가능합니다.
- 원래 데이터 세트에 라벨링 된 감정
- TUM AVIC 데이터베이스의 Levels of Interest
- Geneva Multimodal Emotion Portrayals (GEMEP) corpus 및 German Berlin Emotional Speech database (EMO-DB)
- professional opera singers의 노래에서 나타난 감정 (GeSiE)
- FAU AIBO corpus의 어린이들의 발화에서 나타난 valence
- German talk-show recordings (Vera-am-Mittag corpus)에서 나타난 실제 감정
- 제안된 minimal set은 INTERSPEECH 2009 Emotion Challenge, INTERSPEECH 2010 Paralinguistic Challenge, INTERSPEECH 2011 Speaker State Challenge, INTERSPEECH 2012 Speaker Trait Challenge 및 INTERSPEECH 2013 Computational Paralingusitics ChallengE (ComParE)와 같은 대규모 brute-forced baseline acoustic feature set과 비교되었습니다.
4.1 Database
- 4.1.1 FAU AIBO: FAU AIBO는 세계 최초의 국제 감정 챌린지의 공식 말뭉치로 사용되었습니다. 이 데이터베이스는 Sony 애완동물 로봇 Aibo와 상호작용하는 어린이들의 발화 녹음을 포함하고 있습니다. 따라서 spontaneous 하며, 감정적으로 색칠된 독일어 발화를 포함합니다. 어린이들은 Aibo 로봇이 방향에 대한 목소리 명령에 반응한다고 알려졌지만, 실제로 로봇은 때로는 불복종적으로 행동하여 어린이들로부터 강한 감정 반응을 유도하기 위해 인간 조작자에 의해 제어되었습니다. 이 녹음은 MONT와 OHM이라는 두 개의 학교에서
총 51명의 어린이 (10-13세, 21명 남성, 30명 여성)으로부터 수집되었으며, 쉬는 시간을 제외하고 약 9.2시간의 발화가 포함되어 있습니다. - 4.1.2 TUM Audiovisual Interest Corpus (TUM-AVIC): TUM Audiovisual Interest Corpus (TUM-AVIC)는 spontaneous한 affective interactions을 포함하는 audiovisual 녹음을 담고 있는 데이터베이스입니다. 이 데이터베이스는 INTERSPEECH 2010 Paralinguistics Challenge를 위한 데이터셋으로 사용되었습니다. 이 데이터셋은 제품 프레젠터가 대상자를 상품 프레젠테이션을 통해 안내하는 과정에서 수집되었습니다.
사용된 언어는 영어이지만, 대부분의 제품 프레젠터는 독일어 원어민입니다. 대상자들은 주로 유럽 및 아시아 국적입니다. 이 데이터베이스에는 21명의 대상자 (여성 10명)의 녹음이 포함되어 있습니다.- LOI는 각 sub-turn마다 (화자 turn의 수동적인 pause 기반 sub-division을 통해 찾아낸) 세 가지 라벨로 표시됩니다. 이 세 가지 라벨은
boredom (대상자가 대화나 주제에 지루함을 느끼며 매우 수동적이며 대화를 따르지 않음; loi1로도 알려짐), over neutral (대상자가 대화를 따르고 참여하지만 주제에 관심이 있는지 아니면 무관심한지 판단할 수 없음; loi2로도 알려짐), joyful interaction (대상자가 대화하고 주제에 대해 더 배우고 싶어하는 강한 욕구를 보여주며, 즉, 그/그녀는 토론에 큰 관심을 가짐; loi3으로도 알려짐)입니다. 이 평가에서는 [47]의3,002개의 구문(sub-turns)이 사용되었습니다. 이는 예를 들어 [46]에서 사용된 high interlabeller agreement를 가진 996개의 구문보다 더 많습니다.- high interlabeller agreement는 서로 다른 라벨러들이 동일한 라벨을 부여하는 정도를 나타내는 지표입니다. 즉, 서로 다른 라벨러들이 동일한 구문에 대해 동일한 라벨을 부여하는 경우, 그 구문은 high interlabeller agreement를 가진다고 할 수 있습니다. 이것은 데이터셋의 신뢰성과 일관성을 보장하기 위해 중요한 지표 중 하나입니다.
- LOI는 각 sub-turn마다 (화자 turn의 수동적인 pause 기반 sub-division을 통해 찾아낸) 세 가지 라벨로 표시됩니다. 이 세 가지 라벨은
- 4.1.3 Berlin Emotional Speech Database: Berlin Emotional Speech Database 또는 EMO-DB는 자동 감정 분류의 효과를 테스트하기 위해 매우 잘 알려져 있고 널리 사용되는 데이터베이스입니다. 이 데이터베이스는 Levels of Emotion Annotation Space (LEAS)와 함께 개발되었습니다.
EMO-DB에는 10명의 배우가 7가지 감정(분노, 경멸, 두려움, 기쁨, 슬픔, 수치심, 중립)을 나타내는 독일어 단어 및 문장을 발화한 녹음이 포함되어 있습니다. 이 데이터베이스에는 대략5시간의 오디오 녹음이 포함되어 있습니다. - 4.1.4 The Geneva Multimodal Emotion Portrayals: The Geneva Multimodal Emotion Portrayals(GEMEP)은
10명의 프랑스어 배우가 연기한 1,260개의 멀티모달 감정 표현을 수집한 데이터베이스입니다. 이 데이터베이스는 얼굴 표정, 음성, 제스처 등 다양한 모달리티를 사용하여 감정을 나타냅니다. GEMEP 데이터베이스는 많은 연구에서 사용되며, 이 연구에서도 사용되었습니다. 구체적으로는 12가지 감정이 있으며 총 24개러 분류 된다. - 4.1.5 Geneva Singing Voice Emotion Database(GeSiE): 3명의 가수가 녹음한 감정적인 노래를 수집한 데이터베이스입니다. 이 데이터베이스는 5명의 전문 오페라 가수가 추가로 녹음한 것으로 확장되었습니다.
총 8명의 가수들이 10가지 감정 범주에서 세 가지 다른 구절과 음계를 부르며 녹음되었습니다. 이 데이터베이스는 많은 연구에서 사용되고 있습니다. - Vera-Am-Mittag: 독일 TV 쇼 “Vera am Mittag”에서 추출한
947개의 감정적인 발화로 구성되어 있습니다. 이 쇼에서 주인공인 Vera는 게스트들 간의 토론을 주관합니다. 이 데이터베이스는 매우 자발적이고 감정적으로 매우 다양한 상태를 포함하고 있습니다. 이 데이터베이스의 감정은 활성화, 가치 및 지배력/권력 세 가지 차원으로 설명됩니다.비디오로 구성된 데이터베이스입니다. 이 쇼에서 주인공인 Vera는 게스트들 간의 토론을 주관합니다. 이 데이터베이스는 많은 연구에서 사용되고 있습니다.- 이 부분에서는 EmoReact 데이터베이스의 주석 방법에 대한 정보가 제공됩니다. 주석자들은 각각의 감정 차원에 대해 다섯 개의 이미지 중 하나를 선택할 수 있는 아이콘 기반 방법을 사용했습니다. 주석자들은 먼저 수동으로 분할된 발화를 듣고, 그 발화에서 가장 잘 설명하는 감정 차원에 대한 아이콘을 선택해야 했습니다. 이 아이콘의 선택은 후에 각 차원마다 [-1;1] 범위 내에서 균등하게 분포된 다섯 가지 범주로 매핑되었으며, 주석자의 확신도를 고려하는 가중치 함수를 적용하여 평균값을 계산했습니다. 비교적 평가를 가능하게 하기 위해 연속적인 가치와 활성화 라벨은 네 개의 클래스로 이산화되었으며, 이는 activation-valence 공간의 네 사분면(q1:positive-active, q2:positive-passive, q3:negative-passive, and q4:negative-active)을 나타냅니다.
4.2 Common Mapping of Emotions
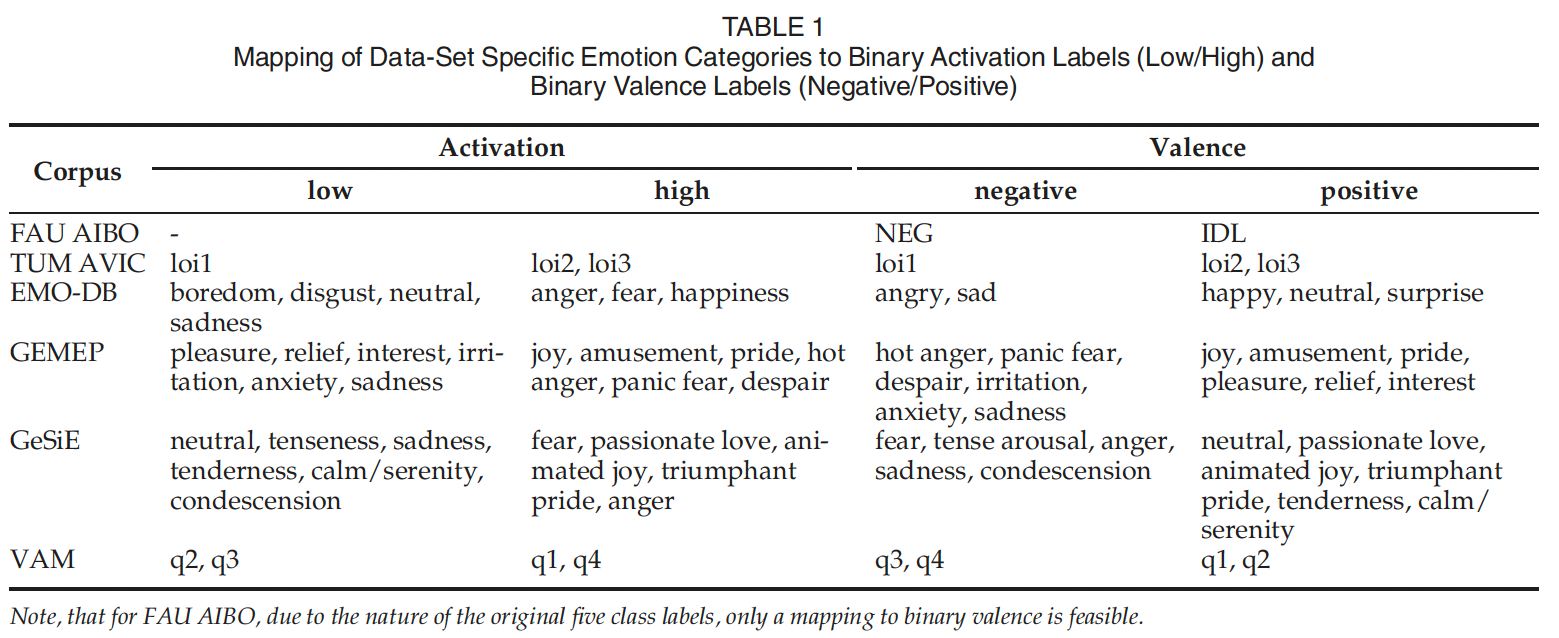
- 이 부분에서는 모든 데이터셋에서 결과와 특징 집합의 성능을 비교할 수 있도록 하기 위해, 각각의 데이터셋에 대한 특정한 감정 라벨을 공통적 binary arousal and valence representation으로 매핑했다는 것을 설명합니다. 이 매핑은 [43], [47], [49] (GEMEP의 경우)에서 제안된 대로 [53]를 참고하여 수행되었습니다. GeSiE의 경우 GEMEP에서 사용된 절차와 유사하게 매핑이 수행되었습니다. Table 1은 감정 범주를 바이너리 활성화 및 가치 라벨로 매핑한 결과를 보여줍니다.
- Note, that for FAU AIBO: 원래 5개의 클래스 레이블 특성상 binary valence에 대한 매핑만 가능
4.3 Experimental Protocol
- AIBO에 대한 실험을 제외한 모든 실험은 LOSO(Leave-One-Speaker(Group)-Out) 교차 검증을 사용하여 수행됩니다.
- LOSO는 “Leave-One-Speaker-Out”의 약어로, 각 실험에서 하나의 화자를 제외한 모든 화자 데이터를 사용하여 모델을 학습하고, 나머지 화자의 데이터를 사용하여 모델을 평가하는 교차 검증 방법입니다. 이 방법은 모델이 다른 화자들에 대해서도 일반화될 수 있는지 확인하기 위해 사용됩니다. 즉, 각각의 테스트 세트는 한 명의 화자에 대한 데이터만 포함하며, 이러한 방식으로 모든 화자에 대한 평가가 수행됩니다. (교차검증의 일종)
- GeSiE 데이터셋처럼 화자 수가 8명 이하인 경우, 각 화자의 데이터를 하나의 교차 검증 폴드로 처리합니다. 그러나 8명 이상인 경우, 화자 ID가 무작위로 8개의 그룹으로 나누어지고, 이에 따라 데이터가 8개의 폴드로 분할됩니다. 그런 다음 교차 검증은 각각 7개 폴드에서 데이터를 사용하여 8개의 다른 모델을 훈련하고, 첫 번째 모델에 대한 테스트를 위해 첫 번째 폴드를 제외하고 두 번째 모델에 대한 테스트를 위해 두 번째 폴드를 제외하는 식으로 수행됩니다. 이렇게 하면 전체 데이터셋에 대한 예측이 훈련 및 테스트 데이터 중복 없이 생성됩니다. FAU AIBO의 경우, OHM에서 학습하고 MONT에서 평가하는 방식과 MONT에서 학습하고 OHM에서 평가하는 방식으로 두 개의 교차 검증 폴드를 사용합니다.
- 교차 검증 폴드는 교차 검증에서 사용되는 데이터 세트의 하위 집합입니다. 전체 데이터 세트를 여러 개의 폴드로 나누어 각각을 테스트 세트와 학습 세트로 사용하여 모델을 반복적으로 학습하고 평가하는 방법에서, 각각의 폴드는 서로 다른 데이터를 포함하며, 전체 데이터 세트를 대표할 수 있는 크기와 분포를 가지도록 구성됩니다. 예를 들어, 10개의 폴드로 나누어 교차 검증을 수행하는 경우, 10개의 서로 다른 하위 집합으로 데이터가 분할되며, 각각의 폴드는 10%씩의 데이터를 포함합니다. 이러한 방식으로 모든 데이터가 테스트 및 학습에 사용되며, 모델이 일반화될 수 있는지 확인할 수 있습니다.
- paralinguistics 분야에서 가장 널리 사용되는 정적 분류기로서, support-vector machines(SVMs)가 선택되었습니다. SVMs는 WEKA [54]에서 구현된 순차 최소 최적화 알고리즘으로 학습됩니다. 모델 복잡도 C의 값 범위가 평가되며, 결과는 매개 변수 세트의 성능과 관련하여 더 안정적인 결과를 얻기 위해 전체 범위에서 평균화됩니다. c값의 범위는 C1=0.000025, C2=0.00005, C3=0.000075, C4=0.0001, …, C15=0.075, C16=0.1, C17=0.25으로 총 17개의 값이 평가 대상입니다. 이 범위에서 모델 복잡도를 평가하고 결과를 평균화하여 매개 변수 세트의 성능을 더 안정적으로 평가합니다.
- SVMs를 구현하는 데 필요한 데이터 균형 문제에 대해 설명하고 있습니다. SVMs를 사용할 때, 다수 클래스에 대한 사전 편향을 피하기 위해 각 클래스에 대해 동일한 수의 인스턴스가 필요합니다. 이를 위해 각각의 훈련 파티션은 균형을 맞추어야 합니다. Up-sampling은 소수 클래스의 데이터를 복제하여 다수 클래스와 동일한 수의 데이터를 생성하는 방식으로 수행됩니다. 이렇게 함으로써, 모델이 다수 클래스에 대해 사전 편향을 학습하지 않도록 하고, 소수 클래스의 정보를 더 잘 반영할 수 있도록 합니다. Up-sampling은 일반적으로 무작위로 선택된 소수 클래스 샘플을 복제하여 데이터 세트의 크기를 증가시키는 방식으로 수행됩니다.
- VMs를 수치적으로 효율적으로 만들기 위해 모든 음향 매개 변수가 공통 값 범위로 정규화되어야 함을 설명하고 있습니다. 이를 위해 z-정규화, 즉 평균이 0이고 분산이 1인 정규화가 수행됩니다. 이 논문에서는 정규화 매개 변수를 계산하고 적용하는 세 가지 다른 방법을 조사합니다. 첫째, 전체 훈련 파티션에서 평균과 분산을 계산하는 방법(std)입니다. 둘째, 각 화자에 대해 개별적으로 평균과 분산을 계산하는 방법(spkstd)입니다. 이 방법은 [55]와 유사합니다. 셋째, 훈련 및 테스트 파티션 각각에 대해 개별적으로 평균과 분산을 계산하는 방법(stdI)입니다.
4.4 Result
- 제안된 최소한의 매개 변수 세트와 Interspeech Challenges 시리즈에서 사용된 대규모 brute-forced 매개 변수 세트 간의 결과를 비교합니다. brute-forced 매개 변수 세트는 Interspeech Challenges는 2009년 [43] (InterSp09)의 감정, 2010년 [36] (InterSp10)의 연령 및 성별, 관심도 수준, 2011년 [44] (InterSp11)의 화자 상태, 2012년 [45] (InterSp12)의 화자 특성 및 2013 및 2014년 [12], [37] (ComParE)의 전산언어학에 대한 시리즈로 구성이 되어있습니다.
- binary arousal and binary valence classification의 결과
- 매개 변수 세트를 제외한 모든 변수를 제거하기 위해 결과는 다섯 개의 데이터베이스(all, FAU AIBO 제외)와 C=0.0025부터 시작하는 가장 높은 아홉 개의 SVM 복잡도 설정에서 평균화됩니다. 더 높은 복잡도 설정에서만 평균을 계산하는 결정은 작은 특징 집합의 경우 이 임계값보다 낮은 복잡도에서 성능이 크게 저하되기 때문입니다. 이러한 저하가 평균화를 편향시키기 때문입니다.
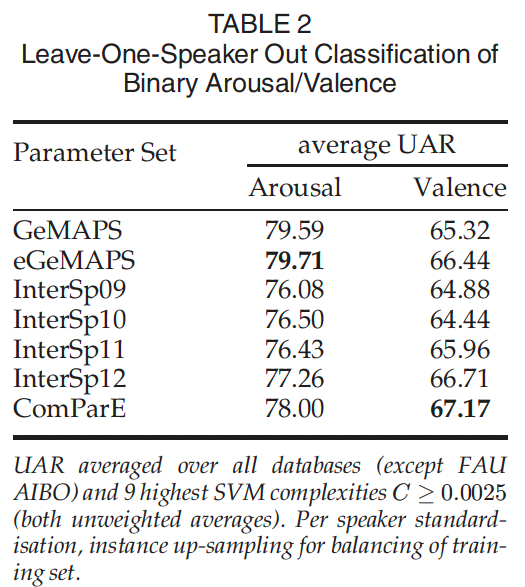
- UAR은 Unweighted Average Recall의 약자로, 각 클래스에 대한 재현율을 평균화한 값입니다. 이 부분에서는 FAU AIBO를 제외한 모든 데이터베이스와 9개의 최고 SVM 복잡도(C>=0.0025)에서 UAR을 평균화합니다. 이는 가중치가 적용되지 않은 평균입니다. 또한, 각 화자에 대한 표준화와 균형 잡힌 훈련 세트를 위해 인스턴스 업샘플링이 수행됩니다.
- 각 클래스에 대한 재현율은 분류기가 실제 양성인 샘플을 얼마나 잘 찾아냈는지를 나타내는 지표입니다. 즉, 분류기가 참 양성(True Positive)으로 분류한 샘플 수를 실제 양성(True Positive + False Negative)인 전체 샘플 수로 나눈 값입니다. 이 값은 해당 클래스의 분류 성능을 평가하는 데 사용됩니다.
- 평균 결과에서 GeMAPS 세트의 높은 효율성을 확인할수 있습니다. eGeMAPS 세트는 arousal에서 거의 80%의 UAR에 도달하여 가장 우수한 성능을 보였습니다.
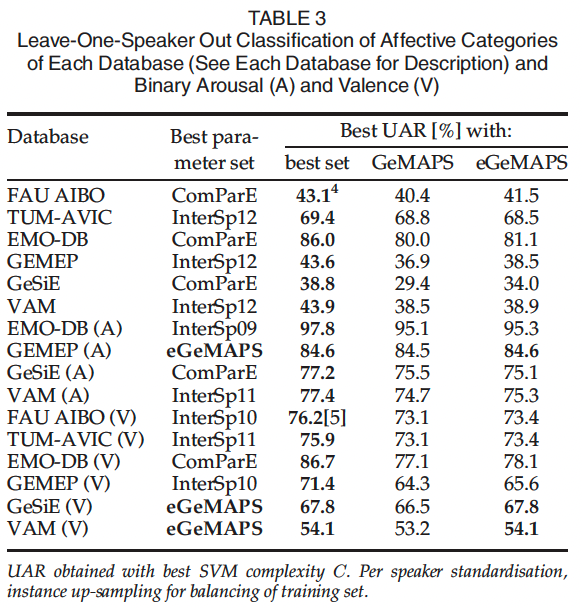
- eGeMAPS 세트는 GEMEP 데이터베이스의 이진 각성 분류와 GeSiE 데이터베이스의 이진 가치 분류에서 최상의 결과를 보입니다. eGeMAPS 세트는 항상 GeMAPS 세트보다 우수하거나 동일하며, 이는 추가 파라미터(MFCC 및 스펙트럼 플럭스 특히)의 중요성을 시사합니다. 이는 특히 가치에서 GeMAPS와 eGeMAPS 간의 평균 차이가 더 큰 경우에 그러하며, 이로써 음향 가치에 대한 그러한 파라미터의 중요성을 제안합니다. 큰 규모의 파라미터 세트들에 비해 전반적으로 GeMAPS 세트는 최소한의 크기임에도 불구하고 놀랍게도 비슷한 성능을 보입니다. 향후 연구에서는 제안된 최소한의 세트가 교차 데이터베이스 분류 실험에서 더 나은 일반화를 얻을 수 있는지 조사해야 합니다.
5.Discussion and Conclusion
- GeMAPS는 수동 상호작용이나 보정 없이 오디오 파형에서 음향 파라미터 세트를 추출하는 자동 추출 시스템을 기반으로 합니다.
- 하지만 특정 현상과 관련성이 있거나 상관관계가 있는 것으로 밝혀진 모든 파라미터를 자동으로 안정적으로 추출할 수 있는 것은 아닙니다. 예를 들어 모음기반 포먼트 분석에는 신뢰할수 있는 자동모음감지및 분류 시스템이 필요합니다.
- 따라서 GeMAPS에서는 깨끗한 음향 조건에서 감독없이 안정적으로 추출할 수 있는 파라미터만 포함했습니다. 검증 실험은 데이터 베이스간 최상의 비교 가능성을 위해 binary classification 실험으로 제한되었습니다.
- 자동 추출을 통한 표준 파라미터 세트의 잠재적 위험 중 하나는 발성 현상과의 연결이 무시될 수 있다는 것입니다. 파라미터 세트를 선택할 때, 이러한 연결을 강조하고 수집 기준 중 하나로 기본 발성 메커니즘을 사용했습니다. 향후 연구를 통해 이러한 기초를 강화하고 새로운 통찰력을 제공할 것으로 기대됩니다. 예를 들어, 각성과 빠른 발성 및/또는 조음 제스처와 관련이 있다고 예상할 수 있으며, 평화로운 성격은 느린 제스처로부터 비롯된다고 합니다. 따라서 앞으로는 발성의 음향 출력을 소리 크기, 피치 등 기본 파라미터를 넘어 생리학적으로 관련된 파라미터로 이해를 확장하는 것이 가치가 있습니다.
- 이러한 맥락에서 성대 접착은 특히 관련성이 높은 파라미터입니다. 접착 증가는 닫힌 단계를 길게 하고 횡성대 공기 흐름 펄스의 진폭을 줄입니다. 이로 인해 음성 원천 기본값의 감쇄 또는 더 구체적으로는 음성 원천 부분 음 두 개 사이의 레벨 차이를 줄일 것으로 예상됩니다. 이러한 방사음에서 이 레벨 차이는 주로 첫 번째 포먼트의 주파수에 영향을 받으며, 이는 발성의 감정 색채에 이차적인 중요성을 가집니다. GeMAPS의 향후 발전은 음성 원천 파라미터를 직접 측정하기 위해 음향 출력 신호를 역 필터링하는 기술의 추가를 포함할 수 있습니다. 이러한 분석은 감정 표현의 다양한 음향 출력 특성의 생리적 상관 관계를 확인할 수 있게 하여 감정적 각성이 음성 생산에 미치는 메커니즘에 대한 지식을 강화합니다.