Journal/Conference : IEEE
Year(published year): 2020
Author: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
Subject: self-supervised learning, speech representation
- Self-supervised learning은 레이블이 없는 데이터에서 일반적인 데이터 표현을 학습하고, 이를 레이블이 있는 데이터에서 세부 조정하는 패러다임입니다. 이 방법은 자연어 처리 분야에서 특히 성공적으로 적용되어 왔으며, 컴퓨터 비전 분야에서도 활발한 연구 주제 중 하나입니다. Self-supervised learning은 지도 학습과 달리 레이블링 작업에 대한 인력과 시간을 절약할 수 있으며, 대규모 데이터셋에서 효과적으로 작동할 수 있습니다. wav2vec 2.0은 음성 처리 분야에서 self-supervised learning을 사용하여 강력한 음성 표현을 학습하는 방법 중 하나입니다.
- WER는 ‘단어 오류 비율’을 의미하는 용어로, 음성 인식 시스템의 성능을 평가하는 데 자주 사용됩니다. 첫 페이지의 초록에서는 wav2vec 2.0이 모든 레이블 데이터를 사용할 때 Librispeech의 깨끗한/다른 테스트 세트에서 각각 1.8/3.3 WER을 달성한다고 언급되었습니다. 이것은 시스템이 깨끗한 테스트 세트에서 100 단어당 평균 1.8개의 오류와 다른 테스트 세트에서 100 단어당 평균 3.3개의 오류를 만든다는 것을 의미합니다.
- Latent representations은 입력 데이터의 특징을 나타내는 벡터입니다. 이러한 벡터는 일반적으로 인공 신경망의 중간 계층에서 추출됩니다. wav2vec 2.0에서는 음성 입력을 잠재 공간에서 마스킹하고, 이를 함께 학습하는 양자화된 잠재 표현을 사용하여 대조적인 작업을 해결합니다. 이를 통해 wav2vec 2.0은 레이블이 없는 음성 데이터로부터 강력한 음성 표현을 학습할 수 있습니다.
- 잠재 공간은 인공 신경망의 hidden layer와 유사한 개념입니다. 인공 신경망에서 입력 데이터는 여러 개의 hidden layer를 거쳐 출력층으로 전달됩니다. 이때 hidden layer에서 추출된 벡터를 잠재 공간이라고 부릅니다. wav2vec 2.0에서도 음성 입력은 여러 개의 hidden layer를 거쳐 잠재 공간에서 마스킹되고, 이를 함께 학습하는 양자화된 잠재 표현을 사용하여 대조적인 작업을 해결합니다.
- wav2vec 2.0에서는 음성 입력을 잠재 공간에서 마스킹하는 방법을 사용합니다. 이 방법은 레이블이 없는 데이터로부터 강력한 음성 표현을 학습하기 위해 사용됩니다. 이를 위해 wav2vec 2.0은 입력 음성 신호를 잠재 공간으로 변환하고, 일부 잠재 벡터를 무작위로 마스킹합니다. 그런 다음, 모델은 마스킹된 벡터를 예측하도록 훈련됩니다. 이러한 방식으로 wav2vec 2.0은 레이블이 없는 데이터에서도 유효한 정보를 추출할 수 있습니다.
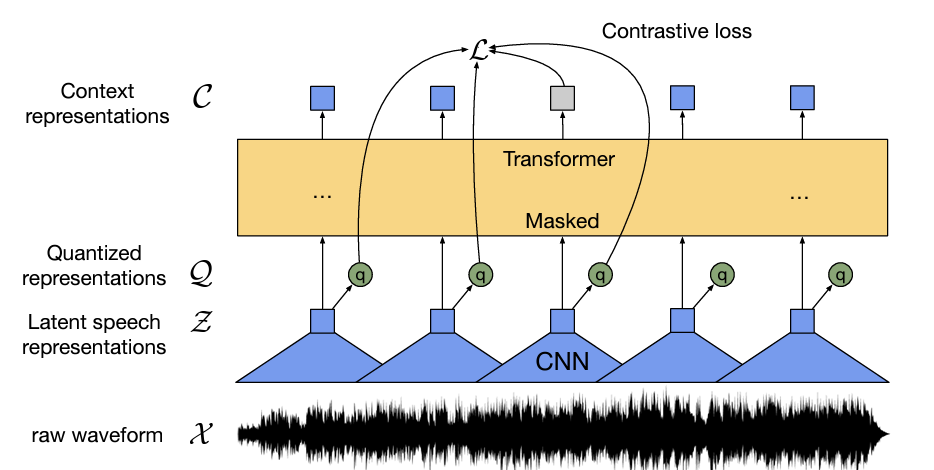
wav2vec 2.0 모델은 다음과 같은 단계로 데이터가 흘러갑니다:
- 입력 데이터인 raw audio X는 multi-layer convolutional feature encoder f를 통해 잠재 공간의 벡터 z1, …, zT로 변환됩니다.
- 잠재 벡터들 z1, …, zT는 Transformer g를 통해 c1, …, cT로 변환됩니다. 이때, c1, …, cT는 전체 시퀀스 [9, 5, 4]에서 정보를 캡처하는 벡터입니다.
- feature encoder의 출력은 양자화 모듈 Z를 통해 qt로 이산화됩니다. 이렇게 얻어진 qt는 self-supervised objective (§ 3.2)에서 target을 나타내기 위해 사용됩니다.
이러한 방식으로 wav2vec 2.0은 레이블이 없는 데이터에서도 유효한 정보를 추출할 수 있습니다. 또한, wav2vec 2.0은 vq-wav2vec [5]와 비교하여 연속적인 음성 표현에 대한 context representations을 구축하고 self-attention을 사용하여 전체 시퀀스의 종속성을 캡처합니다.
전체 시퀀스에서 정보를 캡처한다는 것은, 입력 데이터의 전체 시퀀스에 대한 정보를 모델이 학습하고 이를 잘 반영하여 출력을 생성한다는 것을 의미합니다. wav2vec 2.0 모델에서는 입력 데이터인 raw audio X가 feature encoder를 통해 잠재 공간의 벡터 z1, …, zT로 변환되고, 이 벡터들이 Transformer를 통해 c1, …, cT로 변환됩니다. 이때, c1, …, cT는 전체 시퀀스 [9, 5, 4]에서 정보를 캡처하는 벡터입니다. 따라서 wav2vec 2.0 모델은 입력 데이터의 전체 시퀀스에 대한 정보를 잘 반영하여 출력을 생성할 수 있습니다.
양자화 모듈(Quantization module)은 wav2vec 2.0 모델에서 self-supervised training을 위해 사용되는데, 이 모듈은 feature encoder의 출력인 z 벡터를 유한한 speech representations 집합으로 이산화(discretize)합니다. 이러한 이산화된 벡터들은 self-supervised objective (§ 3.2)에서 타겟을 나타내는 데 사용됩니다.
wav2vec 2.0 모델에서는 product quantization [25]이라는 방법을 사용하여 z 벡터를 이산화합니다. 이 방법은 벡터 공간을 여러 개의 서브 공간으로 분할하고, 각 서브 공간에 대해 centroid를 계산하여 해당 서브 공간 내의 점들을 가장 가까운 centroid와 매칭시키는 방식으로 동작합니다. 이렇게 생성된 매칭된 centroid들의 인덱스를 사용하여 z 벡터를 이산화합니다.
z 벡터를 유한한 speech representations 집합으로 이산화한다는 것은, 연속적인 값을 일정한 간격으로 나누어서 유한한 speech representations 집합으로 변환하는 것을 의미합니다. 이러한 변환은 self-supervised objective (§ 3.2)에서 타겟을 나타내는 데 사용됩니다.
Feature encoder는 입력 데이터인 raw audio X를 잠재 공간의 벡터 z1, …, zT로 변환하는데 사용됩니다. 이 encoder는 여러 블록으로 구성되어 있으며, 각 블록은 시간적 컨볼루션(temporal convolution)을 포함하고 있습니다. 이후 layer normalization [1]과 GELU activation function [21]이 적용됩니다.
또한, Feature encoder에 입력되는 raw waveform은 zero mean과 unit variance로 정규화됩니다. 이렇게 정규화된 입력 데이터는 Encoder의 총 stride에 따라 T개의 time-steps로 Transformer (§ 4.2)에 입력됩니다. 따라서 Feature encoder는 입력 데이터를 잘 처리하여 Transformer에 전달하는 역할을 합니다.
Contextualized representations with Transformers는 wav2vec 2.0 모델에서 사용되는 기술 중 하나입니다. 이 기술은 feature encoder의 출력인 z 벡터를 context network로 전달하여, 입력 데이터의 전체 시퀀스에 대한 정보를 잘 반영하는 벡터 c1, …, cT를 생성합니다.
이때, context network는 Transformer architecture [55, 9, 33]을 따릅니다. Transformer는 입력 데이터의 전체 시퀀스에 대한 정보를 잘 반영할 수 있는 구조로, 이전의 RNN과 같은 모델보다 더욱 효과적으로 입력 데이터를 처리할 수 있습니다.
- Transformer architecture는 딥러닝 모델 중 하나로, 입력 데이터의 전체 시퀀스에 대한 정보를 잘 반영할 수 있는 구조를 가지고 있습니다. 이 구조는 RNN과 같은 모델보다 더욱 효과적으로 입력 데이터를 처리할 수 있습니다.
- Transformer architecture는 self-attention mechanism을 사용하여 입력 데이터의 전체 시퀀스에 대한 정보를 잘 반영합니다. Self-attention mechanism은 입력 데이터 내에서 서로 다른 위치의 정보를 상호작용시켜서, 해당 위치의 정보가 다른 위치에서 어떻게 사용되는지 학습합니다.
- Transformer architecture는 크게 두 가지 부분으로 나뉩니다. 첫 번째 부분은 encoder이며, 입력 데이터를 임베딩하고 여러 층의 self-attention과 feed-forward network layer로 구성됩니다. 두 번째 부분은 decoder이며, encoder에서 생성된 벡터들을 기반으로 출력 시퀀스를 생성하는데 사용됩니다.
- Transformer architecture는 자연어 처리 분야에서 많이 사용되며, 특히 기계 번역 분야에서 좋은 성능을 보입니다. wav2vec 2.0 모델에서도 Transformer architecture가 feature encoder와 context network에 적용되어, 입력 데이터의 전체 시퀀스에 대한 정보를 잘 반영하는 벡터들을 생성합니다.
또한, wav2vec 2.0 모델에서는 absolute positional information을 인코딩하는 고정된 positional embeddings 대신 relative positional embedding을 사용합니다. 이러한 relative positional embedding은 convolutional layer와 유사하게 동작하며 [37, 4, 57], 입력 데이터의 상대적인 위치 정보를 인코딩합니다.
마지막으로, convolutional layer의 출력값에 GELU activation function을 적용하고 입력값에 더해준 후 layer normalization을 적용합니다. 이러한 과정을 거치면서 생성된 벡터 c1, …, cT는 입력 데이터의 전체 시퀀스에 대한 정보를 잘 반영하고 있습니다.
Quantization module은 wav2vec 2.0 모델에서 사용되는 기술 중 하나입니다. 이 모듈은 self-supervised training을 위해 feature encoder의 출력인 z 벡터를 이산화(discretize)하여 사용합니다
Quantization module은 product quantization [25]이라는 방법을 사용하여 z 벡터를 이산화합니다. 이 방법은 G개의 codebook(또는 group)을 사용하며, 각 codebook은 V개의 entry로 구성됩니다. 따라서, 각 codebook에서 하나의 entry를 선택하고, 선택된 entry들을 concatenate하여 하나의 벡터 q를 생성합니다.
이러한 과정으로 생성된 q 벡터는 입력 데이터 X에 대한 잠재적인 표현(representation)으로 사용됩니다. 이때, q 벡터는 연속적인 값을 일정한 간격으로 나누어서 유한한 speech representations 집합으로 변환하는 것을 의미합니다.
Quantization module은 wav2vec 2.0 모델에서 self-supervised objective (§ 3.2)에서 타겟을 나타내는 데 사용됩니다. 즉, 입력 데이터 X와 q 벡터 사이의 관계를 학습하여, 입력 데이터 X에 대한 잠재적인 표현(representation)을 생성하는 데 활용됩니다.
wav2vec 2.0 모델의 training은 크게 pre-training과 fine-tuning 두 단계로 나뉩니다. 이 두 단계에서 사용되는 데이터는 모두 self-supervised learning을 기반으로 합니다.
Pre-training 단계에서는, 입력 데이터 X를 이용하여 feature encoder와 context network를 학습합니다. 이때, 입력 데이터 X는 일정한 비율로 time steps가 mask되어 있습니다. Masking된 time steps에 대해서, 모델은 해당 time step의 quantized latent audio representation을 식별해야 합니다.
Fine-tuning 단계에서는, labeled data를 이용하여 pre-trained model을 fine-tuning합니다. Fine-tuning에 사용되는 labeled data는 speech recognition task나 speaker identification task 등과 같은 downstream task에서 수집된 데이터입니다.
따라서, wav2vec 2.0 모델의 training 과정은 다음과 같습니다.
- Pre-training: 입력 데이터 X를 이용하여 feature encoder와 context network를 학습합니다.
- Masked language modeling 방식을 사용하여, 일부 time steps가 mask됩니다.
- Masking된 time steps에 대해서, 모델은 해당 time step의 quantized latent audio representation을 식별해야 합니다.
- Fine-tuning: labeled data를 이용하여 pre-trained model을 fine-tuning합니다.
- Downstream task에서 수집된 labeled data를 사용합니다.
- Fine-tuned model은 downstream task에서 좋은 성능을 보입니다.
- Pre-training: 입력 데이터 X를 이용하여 feature encoder와 context network를 학습합니다.
quantized latent audio representation을 식별해야 한다는 것은, masked time step에서 입력 데이터 X에 대한 feature encoder의 출력인 z 벡터를 이산화하여 생성된 q 벡터 중에서, 정확히 어떤 q 벡터가 해당 masked time step에 대한 올바른 표현(representation)인지를 식별해야 한다는 것을 의미합니다.
즉, wav2vec 2.0 모델은 pre-training 단계에서 입력 데이터 X의 일부 time steps를 mask하고, 이러한 masked time steps에 대해서 올바른 quantized latent audio representation을 식별하는 데 초점을 둡니다. 이러한 방식으로 모델은 입력 데이터 X에 대한 잠재적인 표현(representation)을 학습하게 됩니다.
이러한 pre-training 단계에서 학습된 모델은 fine-tuning 단계에서 downstream task에 적용됩니다. Fine-tuning 단계에서는 labeled data를 이용하여 pre-trained model을 fine-tuning하며, 이때 모델은 downstream task에서 좋은 성능을 보이도록 학습됩니다
입력 데이터가 context network를 학습한다는 것은, wav2vec 2.0 모델에서 입력 데이터 X의 잠재적인 표현(representation)을 생성하기 위해 context network가 사용된다는 것을 의미합니다.
Context network는 feature encoder의 출력인 z 벡터를 입력으로 받아, 전체 시퀀스에 대한 정보를 잘 반영하는 c 벡터들을 생성합니다. 이때, c 벡터들은 Transformer architecture와 함께 사용되어 입력 데이터 X의 전체 시퀀스에 대한 정보를 잘 반영하는 벡터들을 생성합니다.
따라서, wav2vec 2.0 모델에서 입력 데이터 X는 feature encoder와 context network를 통해 잠재적인 표현(representation)으로 변환됩니다. 이러한 방식으로 모델은 self-supervised learning을 기반으로 하여 입력 데이터 X에 대한 좋은 표현(representation)을 학습하게 됩니다.