Journal/Conference : IEEE
Year(published year): 2022 September
Author: Taesu Kim, SeungHeon Doh, Gyunpyo Lee, Hyungseok Jeon, Juhan Nam, Hyeon-Jeong Suk
Subject: Emotion Recognition, Wake-Up Words
Hi,KIA: A Speech Emotion Recognition Dataset for Wake-Up Words
Summary
- 새로운 공개 데이터셋인 Hi, KIA, 감정 레이블이 지정된 WUW 데이터셋을 제안함
- Hi, KIA라는 새로운 공개 데이터셋을 제안하고 이를 이용한 감정 인식 모델을 개발함
- 제안된 데이터셋은 488개의 한국어 발화 샘플로 구성되어 있으며, 분노, 기쁨, 슬픔, 중립 등 4가지 감정 상태로 레이블링되어 있음
- 개발된 두가지 분류 모델은 전통적인 hand-craft feature와 pre-trained neural network를 이용한 transfer-learning 접근 방식을 사용하여 구현되었으며 이 데이터셋에서 짧은 발화 수준의 감정 인식에 대한 기준 결과를 제시함
- 이러한 결과들은 앞으로 VUI 기반 어플리케이션에 활용될 것으로 기대됨
I. Introduction
음성 인식 기술은 음성 사용자 인터페이스(VUIs)를 통해 다양한 응용 프로그램에서 사용되고 있다. VUIs는 사용자에게 보이지 않는 인터페이스로서, 기존의 인터페이스보다 감정적인 커뮤니케이션을 더 잘 전달할 수 있다. 특히, 차량 내 VUIs는 운전 중 안전을 보장하고 운전자의 감정적인 경험을 향상시키는 데 큰 관심을 받고 있다. WUW(Wake-up words)를 발화하여 VUIs를 활성화하는 것이 가장 일반적인 사용 방법 중 하나이다. 이 연구에서는 Hi,KIA 데이터셋을 사용하여 WUW 발화 시 사용자의 감정 상태를 분류하는 모델을 개발하였다. Hi,KIA 데이터셋은 488개의 한국어 발화 샘플로 구성되어 있으며, 4가지 감정 상태(분노, 기쁨, 슬픔, 중립)로 레이블링되어 있다. 이 모델은 차량 내 VUIs에서 WUW를 발화한 사용자의 감정 상태를 인식하는 데 활용될 수 있다.
Wake up word emotion recognition
- 화자의 음성을 기반으로 화자의 감정 상태를 감지하는 프로세스.
- 여기에는 감정 상태와 관련이 있는 것으로 알려진 피치, 강도 및 스펙트럼 특성과 같은 다양한 음향적 특징에 대해 화자의 음성을 분석하는 작업이 포함.
감정 데이터를 사용한 이유
- 사용자와 자연스러운 대화를 할 수 있는 VUI(Voice User Interface) 기반 어플리케이션의 개발이 필요
- 이러한 어플리케이션에서는 사용자의 감정 상태를 파악하여 적절한 대응을 제공하는 것이 중요
- 예를 들어, 운전 중인 차량에서 음성 인식 기반의 VUI 어플리케이션을 사용할 때, 운전자가 분노 상태일 때는 안전 운전에 방해가 되는 메시지를 보여주지 않도록 하거나, 기분 좋은 상태일 때는 더욱 친근한 메시지를 보여줄 수 있음
SER 데이터셋들과 비교
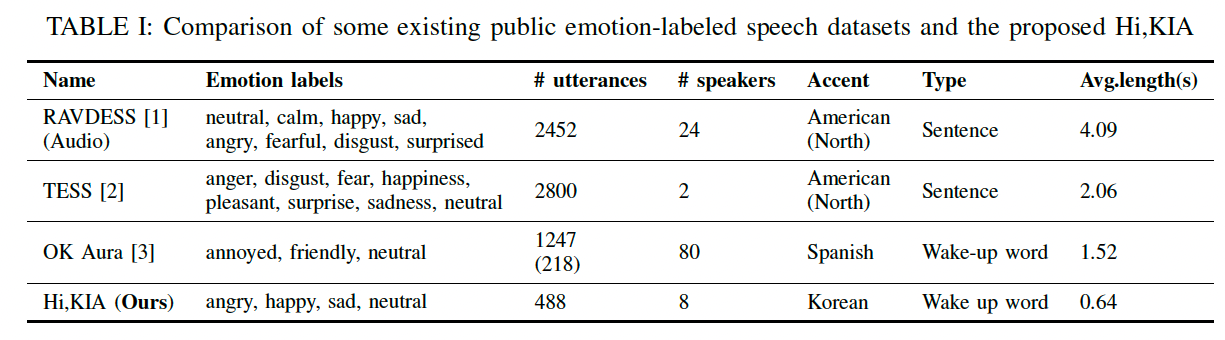
- SER는 감정 발화와 라벨이 포함된 데이터셋을 필요로 함
- IEMOCAP, EmoDB, RAVDESS, TESS 등의 SER 데이터셋이 있음
- 이 데이터 셋들은 text-independent emotion recognition을 기반으로 만들어짐
- 이 말을 다른말로 하면 lexical information과는 상관 없이 사용자의 감정을 인식하는 시스템이라는 것
- WUW SER 데이터셋은 짧은 발화와 키워드로 제한됨
- 최근에 Release된 Ok Aura의 경우 데이터 셋도 많고 스피커도 많지만 labeled된 데이터가 218개 밖에 없음.
II. DATASET
A. Scenario Selection
시나리오는 “Hi, KIA (WUW)”로 시작하는 텍스트 스크립트로 제공되며, 감정 상태를 유발하는 문맥 문장으로 끝남
affective computing 분야에서 경험이 있는 8명의 대학원생들이 VUI가 특정 감정에서 사용되는 시나리오를 제안하도록 요청
이전 연구를 기반으로 운전자의 다섯 가지 감정(화남, 스트레스, 기쁨, 두려움, 슬픔)이 제시
학생들은 각각의 감정에 대해 최소한 두 개의 시나리오를 제안하였으며, 중복된 것들을 병합하여 총 53개의 시나리오가 수집
시나리오는 그림 1(a)에 표시된 valence-arousal 좌표계로 매핑되었습니다.
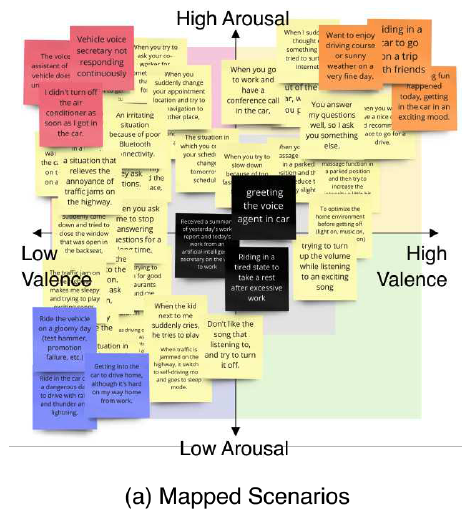
4사분면에 해당하는 감정 범주는 시나리오가 거의 없기 때문에 제외되었습니다.
- arousal: 감정의 흥분 정도를 이야기하는 척도
- 이 값이 작을수록 차분한 감정인데, 지루함이나 편안함, 졸림 등이 해당
- arousal이 큰 감정에는 흥분감, 분노, 공포 등
- valence: 감정의 긍정 혹은 부정적인 정도
- 공포는 아주 부정적인 valence를 가지고 지루함이나 흥분감은 중간 정도의 valence를, 행복이나 편안함은 긍정적인 valence를 가짐
- arousal: 감정의 흥분 정도를 이야기하는 척도
시나리오는 valence-arousal 좌표계를 기반으로 화남, 기쁨, 슬픔 및 중립 카테고리로 클러스터링되었습니다.
각 카테고리에서 대표적인 3개의 시나리오가 선택되어 “Hi, KIA” 데이터셋 구축에 사용되었습니다.
선택된 시나리오에 대한 녹음 가이드로 사용될 문장과 함께 삽화가 있는 카드를 준비
각 카드에는 차 내부 위에 녹음 가이드로 사용될 문장이 제시
해당 문장의 상황을 설명하는 참조 이미지를 배경으로 제공
B. Recording and Post-processing
- 4명의 목소리 배우들을 온라인으로 모집. 평균 연령은 31.38세이며 표준 편차는 3.90세
- 마우스 위치를 마이크로부터 30cm 이상 떨어뜨리도록
- 12개 시나리오에 대해 총 576개의 오디오 파일을 수집
C. Human Validation
8명의 대학원생들이 576개의 녹음 파일을 무작위로 선정하여, 각 녹음 파일이 ‘화남’, ‘기쁨’, ‘슬픔’, ‘중립’ 중 어떤 감정을 나타내는지 분류
만약 녹음 파일이 인식하기 어려웠다면 ‘unknown’으로 분류
이 결과를 바탕으로, 모든 인간 평가자가 다른 예측을 한 88개의 녹음 파일은 제거
이를 통해 최종적으로 488개의 녹음 파일이 “Hi, KIA” dataset에 포함됨.
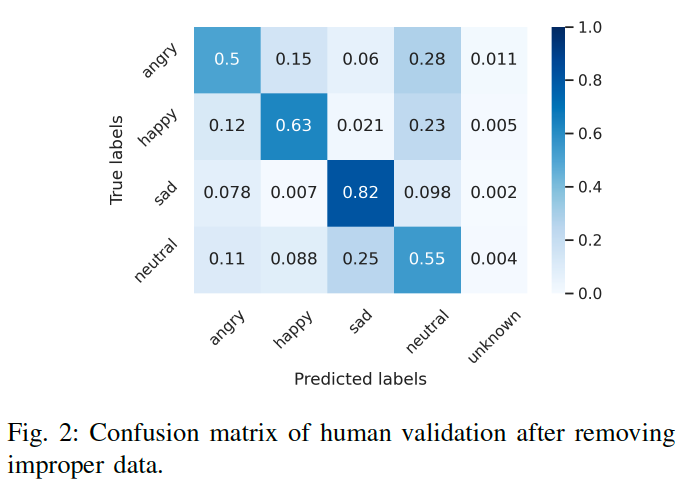
인간 평가자들의 응답을 결합하고 Figure 2에 나와 있는 혼동 행렬을 계산
우리는 평가자들이 ‘슬픈’ 감정을 분류하는 데 비교적 능숙하다는 것을 발견
반면에, ‘화난’과 ‘중립’ 목소리를 식별하는 데 어려움이 있었으며, 그들은 ‘화난’을 ‘중립’으로 평가하고 ‘중립’을 ‘슬픈’으로 평가
high-arousals 목소리를 감정적인 기저 상태로 인식: 참가자들은 ‘angry’와 ‘happy’를 ‘neutral’ 감정으로 관찰
이는 사람들이 WUW(wake up words)에서 high arousals 인상을 인식하는 데 어려움이 있다는 것을 나타냅니다.
III. WAKE-UP WORD EMOTION RECOGNITION
- 데이터셋의 크기가 작기 때문에 두 가지 학습 전략을 탐구
- 하나는 도메인 지식에 기반한 수작업 오디오 특징을 사용하는 것이고, 다른 하나는 대규모 데이터셋으로 학습된 모델의 일반화 능력을 활용하여 작은 데이터셋으로 사전 학습된 신경망 모델을 세밀하게 조정하는 것
- One is using hand-craft audio features based on domain knowledge. The other is fine-tuning a pretrained
neural network model with the small dataset by leveraging the generalization capability of the model trained with a largescale dataset.
A. Hand-craft Features
주파수, 에너지 및 스펙트럼 도메인 기능을 포함하는 확장된 Geneva Minimalistic Acoustic Parameter Set(eGeMAPS) [22]를 사용
88차원의 eGeMAPS 특징은 고정된 평균과 표준 편차 값을 사용하여 z-점수로 표준화
Figure 3은 전체 데이터셋에서 에너지와 음높이 분포의 두 바이올린 그림을 보여줌
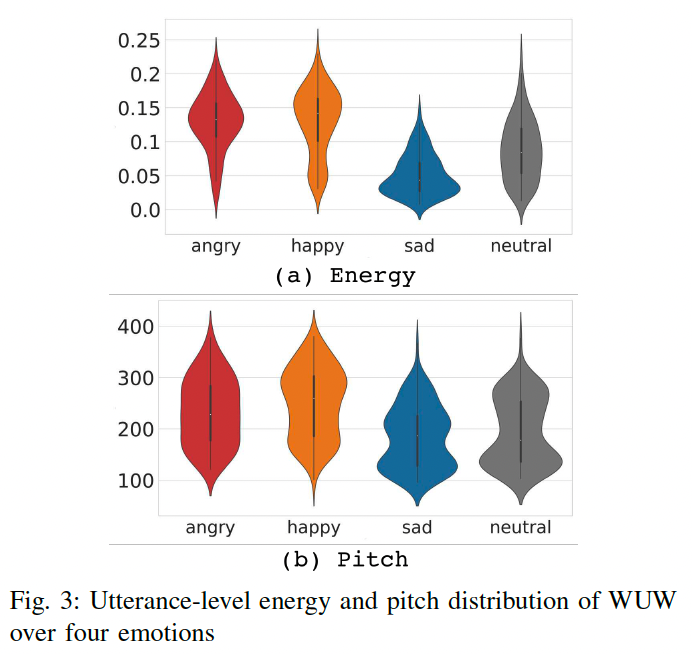
- 일반적인 경향은 고기분 상태 그룹(‘화난’, ‘기쁜’)이 저기분 상태 그룹(‘슬픈’, ‘보통’)과 잘 구별됨
- 딥 뉴럴 네트워크 기반의 기능과 비교하기 위해, 문장 수준의 eGeMAPS 기능을 로지스틱 회귀 분류기의 input으로 사용
B. Fine-Tuning with Pretrained Wav2vec 2.0
- 최근 연구에서는 음성 감정 인식을 위해 딥 러닝을 사용하는 것이 일반적입니다. 그러나 annotation이 달린 데이터의 부족으로 인해 이러한 방법들은 제한되어 있습니다.
- 이 문제를 해결하기 위해, Wav2vec와 같은 대규모 사전 학습된 신경망을 사용한 전이 학습이 감정 인식 정확도를 향상시켰습니다. Hi, KIA와 함께, 우리는 Wav2vec2.0을 사용하여 유사한 전이 학습을 수행하였습니다.
Pretrained Wav2vec2.0
- Wav2vec2.0 [29]은 원시 오디오 신호에서 의미 있는 표현을 추출하기 위해 훈련된 transformer 기반 모델입니다.
- Wav2vec2.0은 CNN을 기반으로 한 로컬 인코더, transformer를 기반으로 한 컨텍스트 네트워크 및 양자화 모듈로 구성되어 있습니다. 로컬 인코더는 원시 파형에서 직접 low-level representation을 추출합니다. 이러한 표현을 기반으로 컨텍스트 네트워크는 대조 손실(contrastive loss)을 사용하여 과거 표현에서 미래 표현을 예측하도록 학습됩니다. 컨텍스트 네트워크의 출력은 학습된 high-level representations입니다.
Fine-tuning methods
- 우리는 Wav2vec2.0을 사용하여 특징을 추출하고 average pooling을 통해 문장 수준의 기능을 얻었습니다. 이전 연구를 따라[28], 우리는 Wav2vec2.0의 모듈에 대한 다양한 세부 조정 전략을 탐구하였습니다.
- 첫째, 감정 지도 없이 긴급한 libri-speech corpus로 학습된 vanila Wav2vec2.0에서 감정 인식 성능을 측정하는 것입니다(세부 조정 없음). 둘째, 로컬 인코더 또는 컨텍스트 네트워크(각각 저수준 또는 고수준 표현에 대한 책임)를 세밀하게 조정하는 것입니다. 마지막으로 전체 네트워크를 세밀하게 조정합니다
C. Experiment Setup
Data split and Metrics
- speaker independence를 위해 8-fold cross-validation을 실행: 7명을 train, validation에 사용하고 1명을 test로 사용 → 그 결과가 WA(Weighted Accuracy)와 UA(Unweighted Accuracy)로 보고 됨
- WA: 모든 클래스를 대상으로 한 전체 정확도
- UA: 각 클래스의 평균 정확도
Hyper-parameters
- 사전 훈련된 모델인 wav2vec2.0-base를 사용하여 실험을 수행
- 2개의 transformer 블록과 7개의 컨볼루션 블록으로 구성
- 각각 512 채널
- Huggingface transformers repository [30]를 기반
- AdamW [31]를 사용하여 모델을 최적화하였으며, 학습률은 5e^5, epoch는 200
- full audio data: 16,000 Hz sampling rate와 1 batch size
IV. RESULTS
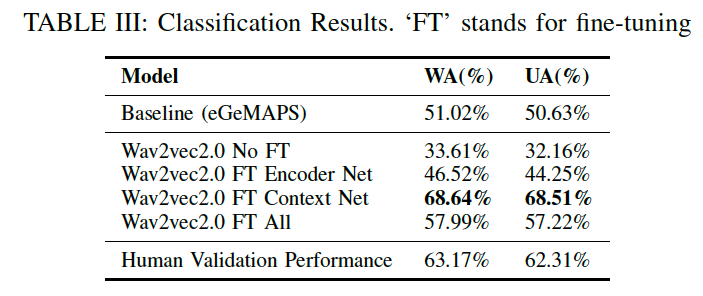
Table III는 분류 모델과 인간 검증의 분류 성능을 보여줍니다.
Human Validation: 8명의 평가자의 평균 성능으로 계산
Fine-tuning이 없는 Wav2vec2.0 특징은 hand-craft 특징보다 성능이 좋지 않음.
- 이는 자기 지도 학습만으로 high-level emotion feature를 추출하는 것이 어렵다는 것을 나타냄
Wav2vec2.0을 fine-tuning하면 분류 정확도가 크게 향상
세 가지 설정 중에서 Context Net을 fine-tuning하는 것이 가장 잘 작동하며, WA(%)와 UA(%)에서 각각 68.64%와 68.51%를 달성합니다.
이는 작은 데이터셋의 경우 high-level representation과 관련된 매개변수를 업데이트하는 것이 모든 매개변수를 업데이트하는 것보다 더 효율적임을 나타냄
Context Net를 fine-tuning하면 인간 검증보다 우수한 결과를 얻을 수 있음 → 이것은 감정 인식이 주관적이기 때문.
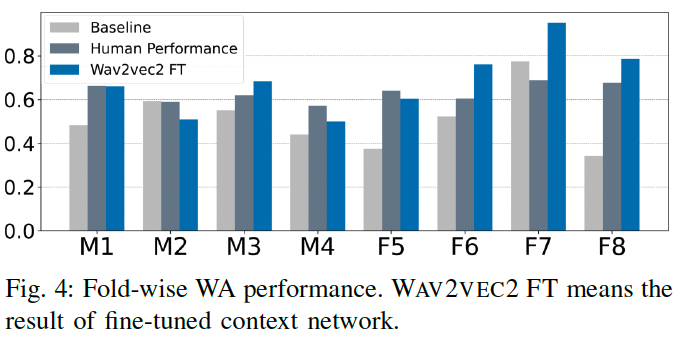
4명의 남성과 4명의 여성이 포함된 8개의 폴드에서 WA(가중치 정확도)를 보여줌
여기서 주목할 점: wav2vec2.0 feature가 대부분의 여성 폴드에서 인간 검증 성능을 능가한다는 것
Human Validation Performance는 남성과 여성 폴드 모두에서 비교적 안정적
Hand-craft 특징과 ‘Wav2vec2.0 FT’는 남성과 여성 폴드 사이에 성능 차이를 보이며, 특히 M1, M2, M4 및 F5 폴드에서 인간 검증보다 성능이 낮음
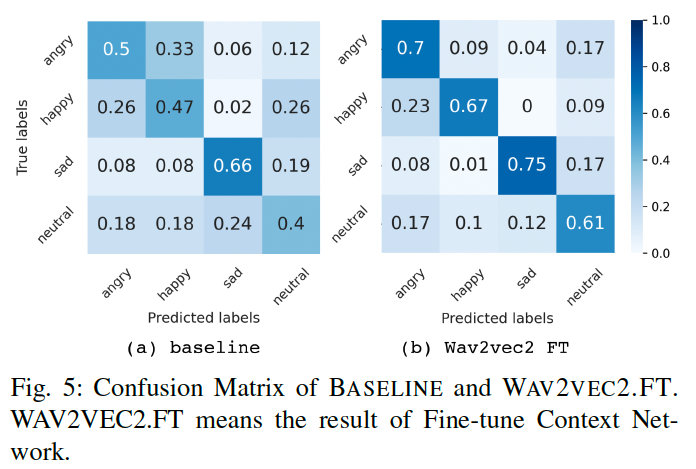
- hand-craft 특징과 Wav2vec2.0 Context Net fine-tuning에 의한 혼동 행렬
- 두 모델 모두 ‘happy’, ‘sad’와 같은 감정의 활성화 및 가치 차이를 구별하는 데 좋음
- 그러나 hand-craft 특징은 high-arousals(‘angry’, ‘happy’) 및 sad-neutral pair 내에서 가치 차이를 이해하는 데 약함 → Wav2vec2.0 컨텍스트 네트워크 fine-tuning에서 완화
- Figure 2와 Figure 5를 비교하면, Wav2vec2.0 컨텍스트 네트워크 fine-tuning은 high arousals 감정과 neutral 감정을 구별하는 데 인간 검증보다 우수한 성능을 보임.
V. CONCLUSIONS
- 이 논문은 감정 라벨이 지정된 WUW 데이터 세트인 Hi, KIA를 제안
- 감정적인 짧은 말을 수집하기 위해 신중하게 설계된 절차를 설명
- Human Validation을 수행한 후 → 488개의 녹음으로 구성된 데이터 세트를 완성
- 이는 한국어 악센트와 발화 수준의 4가지 감정 클래스 주석이 포함된 샷 길이 음성 데이터 세트
- 이 데이터 세트에서 hand-crafted 특징과 transfer learning을 사용하여 짧은 발화 수준 음성 감정 인식에 대한 기준 결과를 제시
- 결과는 4가지 감정 인식에서 높은 정확도를 달성할 수 있다는 것을 보여줍니다.