Journal/Conference: Google
Year(published year): 2016
Author: Paul Covington, Jay Adams, Emre Sargin
Subject: Recommendation, Youtube
Deep Nueral Networks for YouTube Recommendations
GPT 요약
- 딥러닝이 어떻게 유튜브 추천의 성능을 향상시켰어?
- 딥러닝은 유튜브 추천 시스템의 성능을 향상시키는 데 큰 역할을 합니다. 이전에는 작은 문제에서 잘 작동하는 많은 추천 알고리즘이 유튜브와 같은 대규모 문제에서 실패했었습니다. 그러나 딥러닝을 사용하면 이러한 문제를 극복할 수 있습니다. 이 논문에서는 딥 후보 생성 모델과 별도의 딥 랭킹 모델을 설명하며, 이들이 어떻게 유튜브 추천 시스템의 성능을 향상시켰는지 자세히 다루고 있습니다.
- 이전에는 유튜브 추천 시스템에서 사용되는 전통적인 추천 알고리즘은 사용자의 이전 기록과 관련된 비슷한 동영상을 찾아서 추천하는 방식이었습니다. 그러나 이러한 방식은 대규모 데이터에서는 제대로 작동하지 않았습니다. 따라서 딥러닝을 사용하여 유튜브 추천 시스템을 개선하였습니다.
- 논문에서는 딥 후보 생성 모델과 별도의 딥 랭킹 모델을 소개합니다. 딥 후보 생성 모델은 많은 후보 동영상 중에서 가장 관련성이 높은 동영상을 선택하는 모델입니다. 이 모델은 다양한 신호를 사용하여 학습됩니다. 예를 들어, 동영상 제목, 설명, 태그 및 시청 기록 등이 있습니다.
- 딥 랭킹 모델은 후보 동영상 중에서 가장 관심 있는 동영상을 선택하는 모델입니다. 이 모델은 예상 시청 시간을 예측하는 데 사용됩니다. 이전에는 클릭 확률을 예측하는 것이 일반적이었지만, 이 논문에서는 예상 시청 시간을 예측하여 보다 정확한 추천을 제공합니다.
- 딥러닝을 사용하면 이전에는 해결할 수 없었던 대규모 데이터에서의 추천 문제를 해결할 수 있습니다. 따라서 딥러닝은 유튜브 추천 시스템의 성능을 크게 향상시켰습니다.
- feature engineering을 어떻게 했어?
- 저희는 보통 랭킹 모델에서 수백 개의 특징을 사용합니다. 이러한 특징은 범주형과 연속형으로 거의 반반씩 구성됩니다.
- 그러나 딥러닝은 특징 공학을 대체할 수 있는 잠재력이 있지만, 저희가 다루는 데이터의 본질 때문에 바로 딥러닝 모델에 입력하기에는 적합하지 않습니다.
- 따라서 저희는 여전히 많은 시간을 특징 공학에 할애하고 있습니다. 이를 위해 우리는 각 동영상과 관련된 정보를 수집하고, 이를 기반으로 다양한 특징을 추출합니다. 예를 들어, 동영상 제목, 설명, 태그 및 시청 기록 등이 있습니다.
- 이러한 특징들은 후보 생성 및 랭킹 모델에서 사용됩니다. 따라서 우리가 선택하는 특징들은 추천 시스템의 성능에 큰 영향을 미칩니다.
- 딥 랭킹 모델과 딥 후보 모델의 차이점이 뭐야?
- 딥 후보 생성 모델과 딥 랭킹 모델은 유튜브 추천 시스템에서 서로 다른 역할을 합니다.
- 딥 후보 생성 모델은 많은 후보 동영상 중에서 가장 관련성이 높은 동영상을 선택하는 모델입니다. 이 모델은 다양한 신호를 사용하여 학습됩니다. 예를 들어, 동영상 제목, 설명, 태그 및 시청 기록 등이 있습니다. 이러한 신호를 사용하여 후보 동영상을 생성하고, 이들 중에서 가장 관련성이 높은 동영상을 선택합니다.
- 반면에 딥 랭킹 모델은 후보 동영상 중에서 가장 관심 있는 동영상을 선택하는 모델입니다. 이 모델은 예상 시청 시간을 예측하는 데 사용됩니다. 이전에는 클릭 확률을 예측하는 것이 일반적이었지만, 이 논문에서는 예상 시청 시간을 예측하여 보다 정확한 추천을 제공합니다.
- 따라서 딥 후보 생성 모델과 딥 랭킹 모델은 서로 다른 목적과 기능을 가지고 있습니다.
- 이를 이용해서 어떻게 사용자에게 추천하는거야?
- 유튜브 추천 시스템은 크게 두 단계로 나뉩니다. 첫 번째는 딥 후보 생성 모델을 사용하여 수백만 개의 동영상 중에서 수백 개의 후보 동영상을 선택하는 것입니다. 두 번째는 딥 랭킹 모델을 사용하여 이러한 후보 동영상 중에서 가장 관심 있는 동영상을 선택하는 것입니다.
- 따라서 유저에게 추천하기 위해서는, 먼저 유저의 시청 기록, 검색 기록, 좋아요 및 싫어요 등과 같은 정보를 수집합니다. 그런 다음 이 정보를 사용하여 딥 후보 생성 모델을 실행하여 수백 개의 후보 동영상을 생성합니다.
- 그 다음, 딥 랭킹 모델을 실행하여 이러한 후보 동영상 중에서 가장 관심 있는 동영상을 선택합니다. 이 모델은 예상 시청 시간을 예측하는 데 사용됩니다. 예측된 시청 시간이 긴 동영상일수록, 유저가 해당 동영상에 대해 관심이 있을 가능성이 높습니다.
- 따라서 유튜브 추천 시스템은 딥 후보 생성 모델과 딥 랭킹 모델을 결합하여 유저에게 맞춤형 추천을 제공합니다.
- 전통적인 추천 알고리즘보다 더 성능이 나은지 어떻게 알아?
- 이 논문에서는 딥 후보 생성 모델과 딥 랭킹 모델을 기존의 전통적인 추천 알고리즘과 비교하여 성능을 평가하였습니다.
- 기존의 전통적인 추천 알고리즘은 주로 협업 필터링, 콘텐츠 기반 필터링 등이 사용되었습니다. 이러한 알고리즘들은 유저와 아이템 간의 상호작용 정보를 사용하여 추천을 수행합니다.
- 논문에서는 A/B 테스트를 사용하여 딥 후보 생성 모델과 딥 랭킹 모델을 기존의 전통적인 추천 알고리즘과 비교하였습니다. 이를 위해, 일부 유저에게는 기존의 추천 알고리즘을 사용하여 동영상을 추천하고, 다른 일부 유저에게는 딥 후보 생성 모델과 딥 랭킹 모델을 사용하여 동영상을 추천하였습니다.
- 결과적으로, 딥 후보 생성 모델과 딥 랭킹 모델이 기존의 전통적인 추천 알고리즘보다 더 나은 성능을 보였습니다. 이러한 결과는 딥러닝이 복잡한 문제를 해결하는 데 있어서 매우 유용하다는 것을 보여주며, 유튜브 추천 시스템에서 딥러닝이 어떻게 활용될 수 있는지를 보여줍니다.
- 추천 알고리즘의 모델 구조에 대해서 input layer, hidden layer, output을 포함해서 자세하게 알려줘
- 이 논문에서는 딥 후보 생성 모델과 딥 랭킹 모델을 사용하여 유튜브 추천 시스템의 성능을 향상시켰습니다. 각 모델의 구조는 다음과 같습니다.
- 딥 후보 생성 모델
- Input layer: 유저의 시청 기록, 검색 기록, 좋아요 및 싫어요 등과 같은 정보를 입력 받습니다.
- Hidden layers: 이러한 입력 정보를 처리하는 여러 개의 은닉층이 있습니다. 이 은닉층들은 각각 다양한 신호를 사용하여 후보 동영상을 생성합니다.
- Output layer: 후보 동영상 중에서 가장 관련성이 높은 동영상을 선택합니다.
- 딥 랭킹 모델
- Input layer: 후보 동영상의 정보를 입력 받습니다.
- Hidden layers: 이러한 입력 정보를 처리하는 여러 개의 은닉층이 있습니다. 이 은닉층들은 예상 시청 시간을 예측하는 데 사용됩니다.
- Output layer: 예상 시청 시간이 가장 긴 동영상을 선택합니다.
- 두 모델 모두 다양한 신호를 사용하여 복잡한 문제를 해결하기 위해 여러 개의 은닉층을 가지고 있으며, 딥러닝의 특징인 역전파 알고리즘을 사용하여 학습됩니다. 이러한 모델 구조는 유튜브 추천 시스템에서 매우 효과적이며, 대규모 데이터에서 복잡한 문제를 해결하는 데 있어서 딥러닝이 매우 유용하다는 것을 보여줍니다.
- 전체 논문 내용 개요랑 제목 포함해서 요약해줘
- 이 논문의 제목은 “Deep Neural Networks for YouTube Recommendations”입니다. 이 논문에서는 유튜브 추천 시스템에 대한 딥러닝 기반의 접근 방식을 제안하고, 이를 통해 성능을 크게 향상시켰습니다.
- 유튜브는 세계에서 가장 큰 비디오 공유 플랫폼 중 하나이며, 추천 시스템은 수억 명의 사용자가 매일 사용하는 핵심 기능 중 하나입니다. 이 논문에서는 유튜브 추천 시스템이 어떻게 구성되어 있는지에 대한 개요를 제공하며, 딥 후보 생성 모델과 딥 랭킹 모델이 어떻게 작동하는지에 대해 자세히 설명합니다.
- 딥 후보 생성 모델은 유저의 시청 기록, 검색 기록, 좋아요 및 싫어요 등과 같은 정보를 입력으로 받아서 수백만 개의 동영상 중에서 수백 개의 후보 동영상을 생성합니다. 딥 랭킹 모델은 이러한 후보 동영상 중에서 가장 관심 있는 동영상을 선택하는데 사용됩니다. 이 모델은 예상 시청 시간을 예측하는 데 사용되며, 예측된 시청 시간이 긴 동영상일수록 유저가 해당 동영상에 대해 관심이 있을 가능성이 높습니다.
- 논문에서는 A/B 테스트를 사용하여 딥 후보 생성 모델과 딥 랭킹 모델이 기존의 전통적인 추천 알고리즘보다 더 나은 성능을 보인다는 것을 실험적으로 입증하였습니다. 이러한 결과는 딥러닝이 복잡한 문제를 해결하는 데 있어서 매우 유용하다는 것을 보여주며, 유튜브 추천 시스템에서 딥러닝이 어떻게 활용될 수 있는지를 보여줍니다.
- 4.ranking 부분을 feature과 modeling부분을 포함해서 요약해줘
- Ranking is a crucial step in the YouTube recommendation system, which uses impression data to specialize and calibrate candidate predictions for the particular user interface. During ranking, many more features describing the video and the user’s relationship to the video are accessed, because only a few hundred videos are being scored rather than the millions scored in candidate generation. The ranking model is separate from the candidate generation model and uses deep neural networks to predict expected watch time for each candidate video. The model has several hidden layers that process input information and use backpropagation algorithm to learn from large-scale data. The output layer selects the video with the highest predicted watch time as the recommended video.
- 순위는 노출 데이터를 사용하여 특정 사용자 인터페이스에 대한 후보 예측을 전문화하고 보정하는 YouTube 추천 시스템에서 중요한 단계입니다. 순위를 매기는 동안에는 후보 생성에서 점수를 매기는 수백만 개의 동영상이 아닌 수백 개의 동영상만 점수를 매기기 때문에 동영상과 사용자와 동영상과의 관계를 설명하는 더 많은 기능에 액세스합니다. 순위 모델은 후보 생성 모델과는 별개의 모델이며 심층 신경망을 사용하여 각 후보 동영상의 예상 시청 시간을 예측합니다. 이 모델에는 입력 정보를 처리하고 대규모 데이터에서 학습하기 위해 역전파 알고리즘을 사용하는 여러 개의 숨겨진 레이어가 있습니다. 출력 레이어는 예상 시청 시간이 가장 높은 동영상을 추천 동영상으로 선택합니다.
- 그래서 결론이 뭐야?
- The paper proposes a deep neural network architecture for recommending YouTube videos, which is split into two distinct problems: candidate generation and ranking. The deep candidate generation model generates hundreds of relevant videos for the user based on their history and context, while the deep ranking model selects the most relevant video from these candidates using impression data and many more features. The paper shows that the proposed approach outperforms traditional recommendation algorithms in A/B testing.
- 이 논문에서는 후보 생성 및 순위 지정이라는 두 가지 문제로 나뉘어져 있는 YouTube 동영상 추천을 위한 심층 신경망 아키텍처를 제안합니다. 딥 후보 생성 모델은 사용자의 기록과 컨텍스트를 기반으로 수백 개의 관련 동영상을 생성하고, 딥 랭킹 모델은 노출 데이터와 더 많은 기능을 사용하여 이러한 후보 중에서 가장 관련성이 높은 동영상을 선택합니다. 이 논문은 제안된 접근 방식이 A/B 테스트에서 기존 추천 알고리즘보다 우수한 성능을 보인다는 것을 보여줍니다.
Summary
- 딥러닝을 사용하여 성능 향상을 한 Youtube의 추천 시스템을 소개한다.
- deep candidate generation model과 deep ranking model을 설명
YouTube represents one of the largest scale and most sophisticated industrial recommendation systems in existence. In this paper, we describe the system at a high level and focus on the dramatic performance improvements brought by deep learning. The paper is split according to the classic two-stage information retrieval dichotomy: first, we detail a deep candidate generation model and then describe a separate deep ranking model. We also provide practical lessons and insights derived from designing, iterating and maintaining a massive recommendation system with enormous userfacing impact.
YouTube는 현존하는 가장 큰 규모와 정교한 산업 추천 시스템 중 하나입니다. 이 paper에서는 이 시스템을 높은 수준에서 설명하고 딥러닝이 가져온 극적인 성능 향상에 초점을 맞춥니다. 이 paper는 기존의 2단계 정보 검색 이분법에 따라 먼저 deep candidate generation model을 자세히 설명한 다음 별도의 deep ranking model을 설명합니다. 또한 사용자에게 막대한 영향을 미치는 대규모 추천 시스템을 설계, 반복 및 유지 관리하면서 얻은 실질적인 교훈과 인사이트를 제공합니다.
INTRODUCTION
YouTube is the world’s largest platform for creating, sharing and discovering video content. YouTube recommendations are responsible for helping more than a billion users discover personalized content from an ever-growing corpus of videos. In this paper we will focus on the immense impact deep learning has recently had on the YouTube video recommendations system. Figure 1 illustrates the recommendations on the YouTube mobile app home. Recommending YouTube videos is extremely challenging from three major perspectives:
YouTube는 동영상 콘텐츠를 제작, 공유 및 검색할 수 있는 세계 최대의 플랫폼입니다. YouTube 추천은 10억 명 이상의 사용자가 계속 증가하는 동영상 모음에서 개인화된 콘텐츠를 발견할 수 있도록 지원합니다. 이 paper에서는 최근 딥러닝이 YouTube 동영상 추천 시스템에 미친 막대한 영향에 초점을 맞출 것입니다. 그림 1은 YouTube 모바일 앱 홈의 추천 시스템을 보여줍니다. YouTube 동영상 추천은 크게 세 가지 관점에서 매우 까다로운 작업입니다:
- Scale: Many existing recommendation algorithms proven to work well on small problems fail to operate on our scale. Highly specialized distributed learning algorithms and efficient serving systems are essential for handling YouTube’s massive user base and corpus.
- 규모: 작은 문제에서는 잘 작동하는 것으로 입증된 기존의 많은 추천 알고리즘은 YouTube의 규모에서는 작동하지 않습니다. YouTube의 방대한 사용자 기반과 말뭉치를 처리하려면 고도로 전문화된 분산 학습 알고리즘과 효율적인 서빙 시스템이 필수적입니다.
- Freshness: YouTube has a very dynamic corpus with many hours of video are uploaded per second. The recommendation system should be responsive enough to model newly uploaded content as well as the latest actions taken by the user. Balancing new content with well established videos can be understood from an exploration/exploitation perspective.(강화학습)
- 신선도: YouTube는 초당 수 시간 분량의 동영상이 업로드되는 매우 역동적인 코퍼스를 보유하고 있습니다. 추천 시스템은 새로 업로드된 콘텐츠와 사용자가 최근에 수행한 작업을 모델링할 수 있을 만큼 반응성이 뛰어나야 합니다. 새로운 콘텐츠와 잘 알려진 동영상의 균형을 맞추는 것은 탐색/활용 관점에서 이해할 수 있습니다.
- Noise: Historical user behavior on YouTube is inherently difficult to predict due to sparsity and a variety of unobservable external factors. We rarely obtain the ground truth of user satisfaction and instead model noisy implicit feedback signals. Furthermore, metadata associated with content is poorly structured without a well de ned ontology. Our algorithms need to be robust to these particular characteristics of our training data.
- 노이즈: YouTube의 과거 사용자 행동은 희소성과 관찰할 수 없는 다양한 외부 요인으로 인해 본질적으로 예측하기 어렵습니다. 사용자 만족도에 대한 실측 데이터를 거의 확보하지 못하고 대신 노이즈가 많은 암시적 피드백 신호를 모델링합니다. 또한 콘텐츠와 관련된 메타데이터는 잘 정의된 온톨로지 없이는 제대로 구조화되지 않습니다. 학습 데이터의 이러한 특정 특성에 맞게 알고리즘을 강력하게 설계해야 합니다.
In conjugation with other product areas across Google, YouTube has undergone a fundamental paradigm shift towards using deep learning as a general-purpose solution for nearly all learning problems. Our system is built on Google Brain [4] which was recently open sourced as TensorFlow [1]. TensorFlow provides a flexible framework for experimenting with various deep neural network architectures using large scale distributed training. Our models learn approximately one billion parameters and are trained on hundreds of billions of examples.
YouTube는 Google의 다른 제품 영역과 함께 거의 모든 학습 문제에 대한 범용 솔루션으로 딥 러닝을 사용하는 방향으로 근본적인 패러다임의 변화를 겪었습니다. YouTube의 시스템은 최근 TensorFlow[1]로 오픈 소스화된 Google Brain[4]을 기반으로 구축되었습니다. 텐서플로는 대규모 분산 학습을 사용하여 다양한 심층 신경망 아키텍처를 실험할 수 있는 유연한 프레임워크를 제공합니다. 유니티의 모델은 약 10억 개의 매개변수를 학습하고 수천억 개의 예제를 통해 훈련됩니다.
In contrast to vast amount of research in matrix factorization methods [19], there is relatively little work using deep neural networks for recommendation systems. Neural networks are used for recommending news in [17], citations in [8] and review ratings in [20]. Collaborative filtering is formulated as a deep neural network in [22] and autoencoders in [18]. Elkahky et al. used deep learning for cross domain user modeling [5]. In a content-based setting, Burges et al. used deep neural networks for music recommendation [21].
행렬 인수분해 방법[19]에 대한 방대한 양의 연구와 달리, 추천 시스템에 심층 신경망을 사용한 연구는 상대적으로 적습니다. 신경망은 [17]에서 뉴스 추천, [8]에서 인용, [20]에서 리뷰 평가에 사용되었습니다. 협업 필터링은 [22]에서 심층 신경망으로, [18]에서 자동 인코더로 공식화되었습니다. Elkahky 등은 크로스 도메인 사용자 모델링에 딥러닝을 사용했습니다[5]. 콘텐츠 기반 환경에서 Burges 등은 음악 추천에 심층 신경망을 사용했습니다[21].
The paper is organized as follows: A brief system overview is presented in Section 2. Section 3 describes the candidate generation model in more detail, including how it is trained and used to serve recommendations. Experimental results will show how the model benefits from deep layers of hidden units and additional heterogeneous signals. Section 4 details the ranking model, including how classic logistic regression is modified to train a model predicting expected watch time (rather than click probability). Experimental results will show that hidden layer depth is helpful as well in this situation. Finally, Section 5 presents our conclusions and lessons learned.
paper는 다음과 같이 구성되어 있습니다: 섹션 2에서는 간략한 시스템 개요를 소개합니다. 섹션 3에서는 후보 생성 모델이 어떻게 학습되고 추천을 제공하는 데 사용되는지 등 후보 생성 모델에 대해 자세히 설명합니다. 실험 결과를 통해 모델이 심층 계층의 숨겨진 유닛과 추가적인 이질적인 신호를 통해 어떤 이점을 얻을 수 있는지 보여줍니다. 섹션 4에서는 클릭 확률이 아닌 예상 시청 시간을 예측하는 모델을 훈련하기 위해 고전적인 로지스틱 회귀를 수정하는 방법을 포함하여 순위 모델을 자세히 설명합니다. 실험 결과를 통해 숨겨진 레이어 깊이가 이러한 상황에서도 유용하다는 것을 보여줍니다. 마지막으로 섹션 5에서는 결론과 교훈을 제시합니다.
SYSTEM OVERVIEW
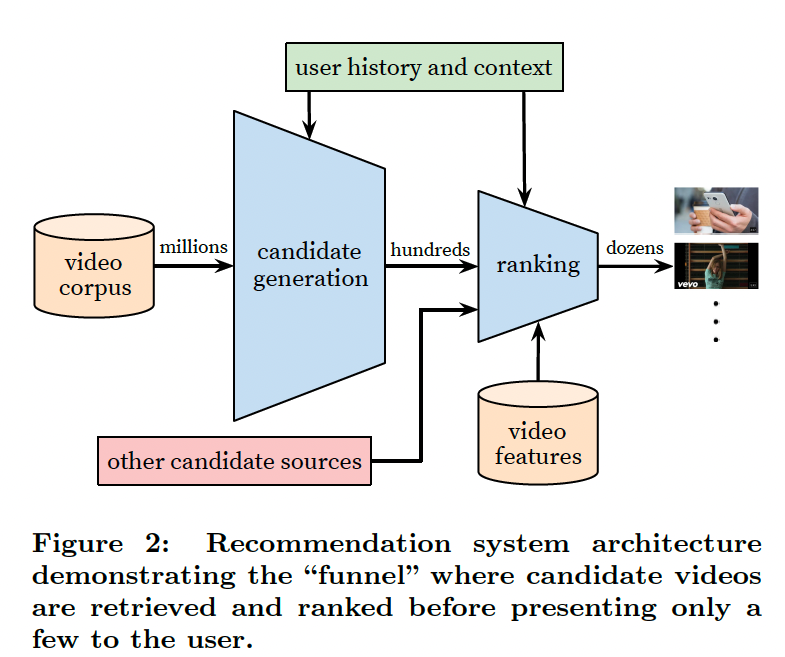
The overall structure of our recommendation system is illustrated in Figure 2. The system is comprised of two neural networks: one for candidate generation and one for ranking. The candidate generation network takes events from the user’s YouTube activity history as input and retrieves a small subset (hundreds) of videos from a large corpus. These candidates are intended to be generally relevant to the user with high precision. The candidate generation network only provides broad personalization via collaborative filtering. The similarity between users is expressed in terms of coarse features such as IDs of video watches, search query tokens
and demographics.
추천 시스템의 전체 구조는 그림 2에 나와 있습니다. 이 시스템은 후보 생성용 네트워크와 랭킹용 네트워크의 두 가지 신경망으로 구성됩니다. 후보 생성 네트워크는 사용자의 YouTube 활동 기록에서 이벤트를 입력으로 받아 대규모 말뭉치에서 작은 하위 집합(수백 개)의 동영상을 검색합니다. 이러한 후보 동영상은 일반적으로 사용자와 관련성이 높고 정밀도가 높아야 합니다. 후보 생성 네트워크만 협업 필터링을 통해 광범위한 개인화를 제공합니다. 사용자 간의 유사성은 동영상 시청의 ID, 검색 쿼리 토큰 및 인구 통계와 같은 거친 기능으로 표현됩니다.
Presenting a few “best” recommendations in a list requires a fine-level representation to distinguish relative importance among candidates with high recall. The ranking network accomplishes this task by assigning a score to each video according to a desired objective function using a rich set of features describing the video and user. The highest scoring videos are presented to the user, ranked by their score.
목록에 몇 가지 ‘최고의’ 추천을 제시하려면 recall률이 높은 후보들 간의 상대적 중요성을 구분할 수 있는 세밀한 수준의 표현이 필요합니다. 랭킹 네트워크는 동영상과 사용자를 설명하는 풍부한 기능 세트를 사용하여 원하는 목적 함수에 따라 각 동영상에 점수를 할당함으로써 이 작업을 수행합니다. 가장 높은 점수를 받은 동영상이 점수에 따라 순위에 따라 사용자에게 표시됩니다.
The two-stage approach to recommendation allows us to make recommendations from a very large corpus (millions) of videos while still being certain that the small number of videos appearing on the device are personalized and engaging for the user. Furthermore, this design enables blending candidates generated by other sources, such as those described in an earlier work [3].
추천에 대한 2단계 접근 방식을 통해 수백만 개에 달하는 대규모 동영상 코퍼스에서 추천을 생성하는 동시에 디바이스에 표시되는 소수의 동영상이 사용자에게 맞춤화되고 흥미를 끌 수 있도록 할 수 있습니다. 또한 이 설계는 이전 연구[3]에서 설명한 것과 같이 다른 소스에서 생성된 후보를 블렌딩할 수 있게 해줍니다.
During development, we make extensive use of o ine metrics (precision, recall, ranking loss, etc.) to guide iterative improvements to our system. However for the final determination of the effectiveness of an algorithm or model, we rely on A/B testing via live experiments. In a live experiment, we can measure subtle changes in click-through rate, watch time, and many other metrics that measure user engagement. This is important because live A/B results are
not always correlated with offline experiments.
개발 과정에서 정확도, 리콜, 순위 손실 등 다양한 지표를 광범위하게 활용하여 시스템의 반복적인 개선을 유도합니다. 그러나 알고리즘이나 모델의 효과를 최종적으로 결정하기 위해서는 라이브 실험을 통한 A/B 테스트에 의존합니다. 실시간 실험에서는 클릭률, 시청 시간 및 사용자 참여를 측정하는 기타 여러 지표의 미묘한 변화를 측정할 수 있습니다. 실시간 A/B 결과가 오프라인 실험과 항상 상관관계가 있는 것은 아니기 때문에 이 점이 중요합니다.
CANDIDATE GENERATION
During candidate generation, the enormous YouTube corpus is winnowed down to hundreds of videos that may be relevant to the user. The predecessor to the recommender described here was a matrix factorization approach trained under rank loss [23]. Early iterations of our neural network model mimicked this factorization behavior with shallow networks that only embedded the user’s previous watches. From this perspective, our approach can be viewed as a nonlinear
generalization of factorization techniques.
후보를 생성하는 동안 방대한 YouTube 말뭉치가 사용자와 관련이 있을 수 있는 수백 개의 동영상으로 좁혀집니다. 여기에 설명된 추천의 전신은 순위 손실 하에서 훈련된 행렬 인수분해 접근 방식이었습니다[23]. 신경망 모델의 초기 반복은 사용자의 이전 시청만 포함하는 얕은 네트워크를 사용하여 이러한 인수 분해 동작을 모방했습니다. 이러한 관점에서 볼 때, 우리의 접근 방식은 인수분해 기법을 비선형적으로 일반화라고 볼 수 있습니다.
Recommendation as Classification
We pose recommendation as extreme multiclass classification where the prediction problem becomes accurately classifying a specific video watch wt at time t among millions of videos i (classes) from a corpus V based on a user U and context C,
추천을 극단적인 다중 클래스 분류로 설정하면, 예측 문제는 사용자 U와 컨텍스트 C를 기반으로 말뭉치 V의 수백만 개의 동영상 i(클래스) 중에서 특정 동영상 시청 횟수 t를 정확하게 분류하는 것입니다,
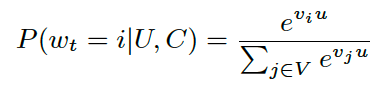
where u 2 Rn represents a high-dimensional \embedding” of the user, context pair and the vj 2 RN represent embeddings of each candidate video. In this setting, an embedding is simply a mapping of sparse entities (individual videos, users etc.) into a dense vector in RN. The task of the deep neural network is to learn user embeddings u as a function of the user’s history and context that are useful for discriminating among videos with a softmax classifier.
여기서 u 2 Rn은 사용자, 컨텍스트 pair 및 vj 2 RN의 고차원 ‘임베딩’을 나타냅니다. 이 설정에서 임베딩은 단순히 스파스 엔티티(개별 동영상, 사용자 등)를 RN의 밀도가 높은 벡터에 매핑하는 것입니다. 심층 신경망의 임무는 소프트맥스 분류기를 사용하여 동영상을 구분하는 데 유용한 사용자 히스토리 및 컨텍스트의 함수로서 사용자 임베딩을 학습하는 것입니다.
Although explicit feedback mechanisms exist on YouTube (thumbs up/down, in-product surveys, etc.) we use the implicit feedback [16] of watches to train the model, where a user completing a video is a positive example. This choice is based on the orders of magnitude more implicit user history available, allowing us to produce recommendations deep in the tail where explicit feedback is extremely sparse.
YouTube에는 명시적인 피드백 메커니즘(좋아요/싫어요, 제품 내 설문조사 등)이 존재하지만, 저희는 사용자가 동영상을 완료하는 것이 긍정적인 예인 시청의 암묵적 피드백[16]을 사용하여 모델을 훈련합니다. 이러한 선택은 사용 가능한 암시적 사용자 기록이 훨씬 더 많기 때문에 명시적 피드백이 극히 드문 꼬리 부분에 대한 추천을 생성할 수 있다는 점을 기반으로 합니다.
Efficient Extreme Multiclass
To efficiently train such a model with millions of classes, we rely on a technique to sample negative classes from the background distribution (”candidate sampling”) and then correct for this sampling via importance weighting [10]. For each example the cross-entropy loss is minimized for the true label and the sampled negative classes. In practice several thousand negatives are sampled, corresponding to more than 100 times speedup over traditional softmax. A popular alternative approach is hierarchical softmax [15], but we weren’t able to achieve comparable accuracy. In hierarchical softmax, traversing each node in the tree involves discriminating between sets of classes that are often unrelated, making the classification problem much more difficult and degrading performance.
수백만 개의 클래스로 이러한 모델을 효율적으로 훈련하기 위해 배경 분포에서 음수 클래스를 샘플링하는 기법(‘후보 샘플링’)을 사용하고 이 샘플링에 중요도 가중치를 부여하여 중요도 가중치[10]를 통해 이 샘플링을 보정합니다. 각 예제에서 교차 엔트로피 손실은 실제 레이블과 샘플링된 음수 클래스에 대해 최소화됩니다. 실제로는 수천 개의 개의 네거티브가 샘플링되며, 이는 기존 소프트맥스보다 100배 이상의 속도 향상에 해당합니다. 널리 사용되는 대안적 접근 방식은 계층적 소프트맥스[15]이지만, 비슷한 정확도를 달성할 수 없었습니다. 계층적 소프트맥스에서는 트리의 각 노드를 탐색할 때 종종 서로 관련이 없는 클래스 집합을 구별해야 하므로 분류 문제가 훨씬 더 어려워지고 성능이 저하됩니다.
At serving time we need to compute the most likely N classes (videos) in order to choose the top N to present to the user. Scoring millions of items under a strict serving latency of tens of milliseconds requires an approximate scoring scheme sublinear in the number of classes. Previous systems at YouTube relied on hashing [24] and the classifier described here uses a similar approach. Since calibrated likelihoods from the softmax output layer are not needed at serving time, the scoring problem reduces to a nearest neighbor search in the dot product space for which general purpose libraries can be used [12]. We found that A/B results were not particularly sensitive to the choice of nearest neighbor search algorithm.
서빙 시간에 사용자에게 표시할 상위 N개를 선택하려면 가장 가능성이 높은 N개의 클래스(동영상)를 계산해야 합니다. 수십 밀리초의 엄격한 서빙 지연 시간 아래에서 수백만 개의 항목에 점수를 매기려면 클래스 수에 따라 대략적인 점수 체계가 필요합니다. YouTube의 이전 시스템은 해싱에 의존했으며[24], 여기에 설명된 분류기는 유사한 접근 방식을 사용합니다. 소프트맥스 출력 레이어의 보정된 가능성은 서빙 시점에 필요하지 않으므로 점수 문제는 범용 라이브러리를 사용할 수 있는 도트 프로덕트 공간에서 가장 가까운 이웃 검색으로 축소됩니다[12]. A/B 결과는 최인접 이웃 검색 알고리즘의 선택에 특별히 민감하지 않다는 것을 발견했습니다.
Model Architecture
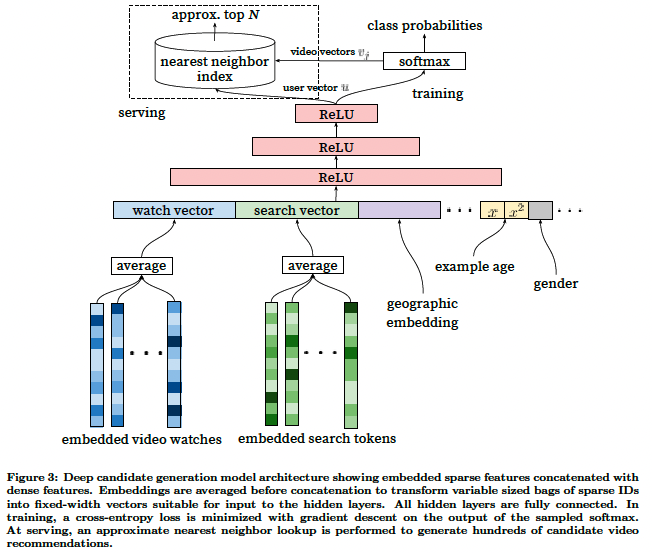
Inspired by continuous bag of words language models [14], we learn high dimensional embeddings for each video in a fixed vocabulary and feed these embeddings into a feedforward neural network. A user’s watch history is represented by a variable-length sequence of sparse video IDs which is mapped to a dense vector representation via the embeddings. The network requires fixed-sized dense inputs and simply averaging the embeddings performed best among several strategies (sum, component-wise max, etc.). Importantly, the embeddings are learned jointly with all other model parameters through normal gradient descent back-propagation updates. Features are concatenated into a wide first layer, followed by several layers of fully connected Rectified Linear Units (ReLU) [6]. Figure 3 shows the general network architecture with additional non-video watch features described below.
연속 단어 가방 언어 모델[14]에서 영감을 받아 각 동영상에 대한 고차원 임베딩을 고정 어휘로 학습하고 이러한 임베딩을 피드포워드 신경망에 공급합니다. 사용자의 시청 기록은 임베딩을 통해 고밀도 벡터 표현에 매핑되는 가변 길이의 스파스 비디오 ID 시퀀스로 표현됩니다. 네트워크에는 고정 크기의 고밀도 입력이 필요하며 여러 전략(합계, 구성 요소별 최대값 등) 중에서 가장 성능이 좋은 임베딩의 평균을 구합니다. 중요한 것은 임베딩이 일반 경사 하강 역전파 업데이트를 통해 다른 모든 모델 파라미터와 함께 학습된다는 점입니다. 특징은 넓은 첫 번째 레이어로 연결되고, 그 다음에는 완전히 연결된 여러 레이어의 정류 선형 단위(ReLU)[6]로 연결됩니다. 그림 3은 아래에 설명된 non-video 감시 기능이 추가된 일반적인 네트워크 아키텍처를 보여줍니다.
Heterogeneous Signals
A key advantage of using deep neural networks as a generalization of matrix factorization is that arbitrary continuous and categorical features can be easily added to the model. Search history is treated similarly to watch history - each query is tokenized into unigrams and bigrams and each token is embedded. Once averaged, the user’s tokenized, embedded queries represent a summarized dense search history. Demographic features are important for providing priors so that the recommendations behave reasonably for new users. The user’s geographic region and device are embedded and concatenated. Simple binary and continuous features such as the user’s gender, logged-in state and age are input directly into the network as real values normalized to [0,1].
행렬 인수분해의 일반화로 심층 신경망을 사용할 때의 주요 장점은 임의의 연속 및 범주형 특징을 모델에 쉽게 추가할 수 있다는 것입니다. 검색 기록은 시청 기록과 유사하게 취급되며, 각 쿼리는 유니그램과 빅그램으로 토큰화되고 각 토큰은 임베드됩니다. 평균을 내면 사용자의 토큰화된 임베디드 쿼리는 조밀하게 요약된 검색 기록을 나타냅니다. 인구통계학적 특징은 추천이 신규 사용자에게 합리적으로 작동하도록 우선순위를 제공하는 데 중요합니다. 사용자의 지리적 지역과 디바이스가 임베드되어 연결됩니다. 사용자의 성별, 로그인 상태, 나이와 같은 간단한 이진 및 연속형 특징은 [0,1]로 정규화된 실제 값으로 네트워크에 직접 입력됩니다.
“Example Age” Feature
Many hours worth of videos are uploaded each second to YouTube. Recommending this recently uploaded (”fresh”) content is extremely important for YouTube as a product. We consistently observe that users prefer fresh content, though not at the expense of relevance. In addition to the first-order effect of simply recommending new videos that users want to watch, there is a critical secondary phenomenon of bootstrapping and propagating viral content [11].
YouTube에는 매초 몇 시간 분량의 동영상이 업로드됩니다. 최근에 업로드된(‘새로운’) 콘텐츠를 추천하는 것은 제품으로서 YouTube에 매우 중요합니다. 사용자들은 관련성을 희생하더라도 새로운 콘텐츠를 선호한다는 사실을 지속적으로 관찰하고 있습니다. 단순히 사용자가 보고 싶어하는 새로운 동영상을 추천하는 1차 효과 외에도, 바이럴 콘텐츠를 부트스트랩하고 전파하는 중요한 2차 현상이 있습니다[11].
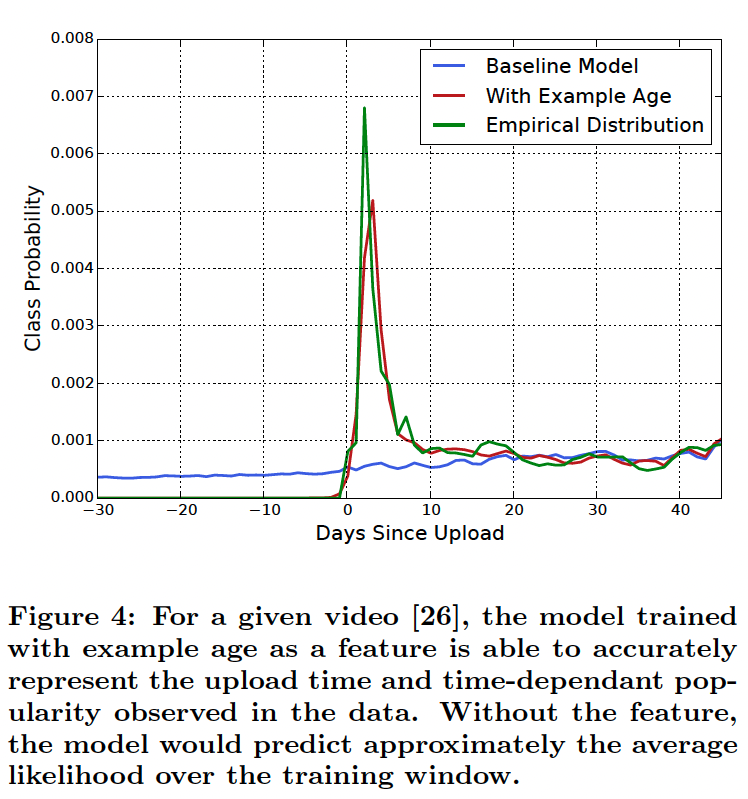
Machine learning systems often exhibit an implicit bias towards the past because they are trained to predict future behavior from historical examples. The distribution of video popularity is highly non-stationary but the multinomial distribution over the corpus produced by our recommender will reflect the average watch likelihood in the training window of several weeks. To correct for this, we feed the age of the training example as a feature during training. At serving time, this feature is set to zero (or slightly negative) to reflect that the model is making predictions at the very end of the training window.
머신 러닝 시스템은 과거의 사례를 통해 미래의 행동을 예측하도록 학습되기 때문에 과거에 대한 암묵적인 편향성을 보이는 경우가 많습니다. 동영상 인기도 분포는 매우 비고정적이지만, 추천자가 생성한 말뭉치에 대한 다항식 분포는 몇 주 동안의 훈련 기간 동안의 평균 시청 가능성을 반영합니다. 이를 보정하기 위해 훈련 중에 훈련 예제의 연령을 피처로 제공합니다. 서빙 시간에는 이 피처가 0(또는 약간 음수)으로 설정되어 모델이 훈련 기간의 맨 마지막에 예측을 하고 있음을 반영합니다.
Figure 4 demonstrates the efficacy of this approach on an arbitrarily chosen video [26].
Label and Context Selection
It is important to emphasize that recommendation often involves solving a surrogate problem and transferring the result to a particular context. A classic example is the assumption that accurately predicting ratings leads to effective movie recommendations [2]. We have found that the choice of this surrogate learning problem has an outsized importance on performance in A/B testing but is very difficult to measure with offline experiments.
추천에는 종종 대체 모델 문제를 해결하고 그 결과를 특정 컨텍스트로 옮기는 작업이 포함된다는 점을 강조하는 것이 중요합니다. 대표적인 예로 평점을 정확하게 예측하면 효과적인 영화 추천이 가능하다는 가정을 들 수 있습니다[2]. 우리는 이 대리 학습 문제의 선택이 A/B 테스트의 성능에 매우 중요하지만 오프라인 실험으로 측정하기는 매우 어렵다는 것을 발견했습니다.
Training examples are generated from all YouTube watches (even those embedded on other sites) rather than just watches on the recommendations we produce. Otherwise, it would be very difficult for new content to surface and the recommender would be overly biased towards exploitation. If users are discovering videos through means other than our recommendations, we want to be able to quickly propagate this discovery to others via collaborative filtering. Another key insight that improved live metrics was to generate a fixed number of training examples per user, effectively weighting our users equally in the loss function. This prevented a small cohort of highly active users from dominating the loss.
Training examples는 추천 동영상뿐만 아니라 모든 YouTube 동영상(다른 사이트에 임베드된 동영상도 포함)에서 생성됩니다. 그렇지 않으면 새로운 콘텐츠가 노출되기가 매우 어렵고 추천이 지나치게 악용에 편향될 수 있습니다. 사용자가 추천 이외의 경로를 통해 동영상을 발견하는 경우, 공동 필터링을 통해 이러한 발견을 다른 사용자에게 신속하게 전파할 수 있기를 바랍니다. 실시간 지표를 개선한 또 다른 주요 인사이트는 사용자당 고정된 사용자당 훈련 예제 수를 고정하여 손실 함수에서 모든 사용자에게 동일한 가중치를 부여하는 것입니다. 이를 통해 활동성이 높은 소수의 사용자 집단이 손실을 지배하는 것을 방지할 수 있었습니다.
Somewhat counter-intuitively, great care must be taken to withhold information from the classifier in order to prevent the model from exploiting the structure of the site and overfitting the surrogate problem. Consider as an example a case in which the user has just issued a search query for “taylor swift”. Since our problem is posed as predicting the next watched video, a classifier given this information will predict that the most likely videos to be watched are those which appear on the corresponding search results page for “taylor swift”. Unsurpisingly, reproducing the user’s last search page as homepage recommendations performs very poorly. By discarding sequence information and representing search queries with an unordered bag of tokens, the classifier is no longer directly aware of the origin of the label.
다소 직관적이지 않을 수 있지만, 모델이 사이트의 구조를 악용하여 대리 문제에 과도하게 적합하지 않도록 분류기에서 정보를 보류하는 데 세심한 주의를 기울여야 합니다. 사용자가 방금 ‘테일러 스위프트’에 대한 검색 쿼리를 실행한 경우를 예로 들어 보겠습니다. 우리의 문제는 다음에 시청할 동영상을 예측하는 것이므로, 이 정보가 주어진 분류기는 ‘테일러 스위프트’에 대한 해당 검색 결과 페이지에 표시되는 동영상이 시청될 가능성이 가장 높은 동영상이라고 예측할 것입니다. 당연히 사용자가 마지막으로 검색한 페이지를 홈페이지 추천 페이지로 재생산하는 것은 매우 저조한 성능을 보입니다. 시퀀스 정보를 버리고 정렬되지 않은 토큰 백으로 검색 쿼리를 표현하면 분류기는 더 이상 레이블의 출처를 직접 인식하지 못합니다.
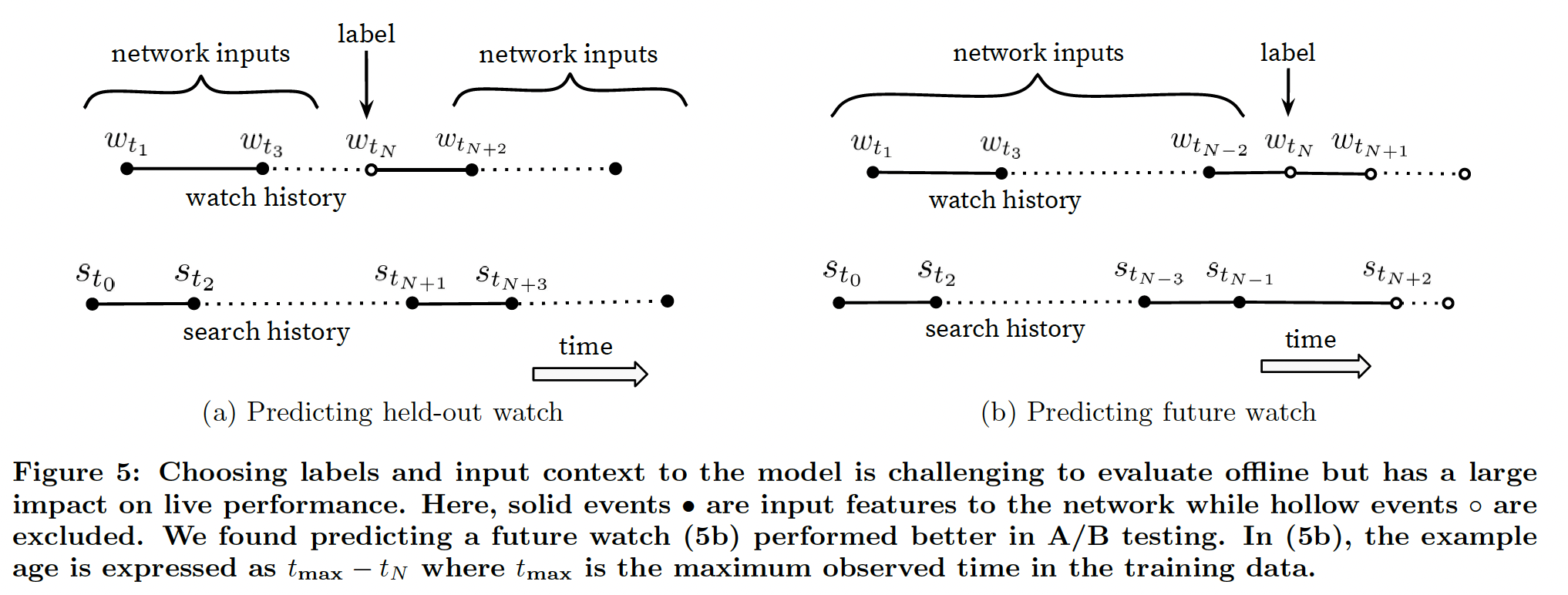
Natural consumption patterns of videos typically lead to very asymmetric co-watch probabilities. Episodic series are usually watched sequentially and users often discover artists in a genre beginning with the most broadly popular before focusing on smaller niches. We therefore found much better performance predicting the user’s next watch, rather than predicting a randomly held-out watch (Figure 5). Many collaborative filtering systems implicitly choose the labels and context by holding out a random item and predicting it from other items in the user’s history (5a). This leaks future information and ignores any asymmetric consumption patterns. In contrast, we “rollback” a user’s history by choosing a random watch and only input actions the user took before the held-out label watch (5b).
동영상의 자연스러운 소비 패턴은 일반적으로 매우 비대칭적인 공동 시청 확률로 이어집니다. 에피소드 시리즈는 일반적으로 순차적으로 시청되며, 사용자는 가장 널리 알려진 장르부터 시작하여 작은 틈새 장르에 집중하면서 해당 장르의 아티스트를 발견하는 경우가 많습니다. 따라서 무작위로 보류된 시청을 예측하는 것보다 사용자의 다음 시청을 예측하는 것이 훨씬 더 나은 성능을 보였습니다(그림 5). 많은 협업 필터링 시스템은 암묵적으로 레이블과 컨텍스트를 선택합니다. 레이블과 컨텍스트를 암시적으로 선택합니다(그림 5a). 이는 미래 정보를 유출하고 비대칭적인 소비 패턴을 무시합니다. 이와는 대조적으로, 무작위 시계를 선택하여 사용자의 기록을 ‘롤백’하고 사용자가 보류된 레이블 시계 이전에 수행한 작업만 입력합니다(5b).
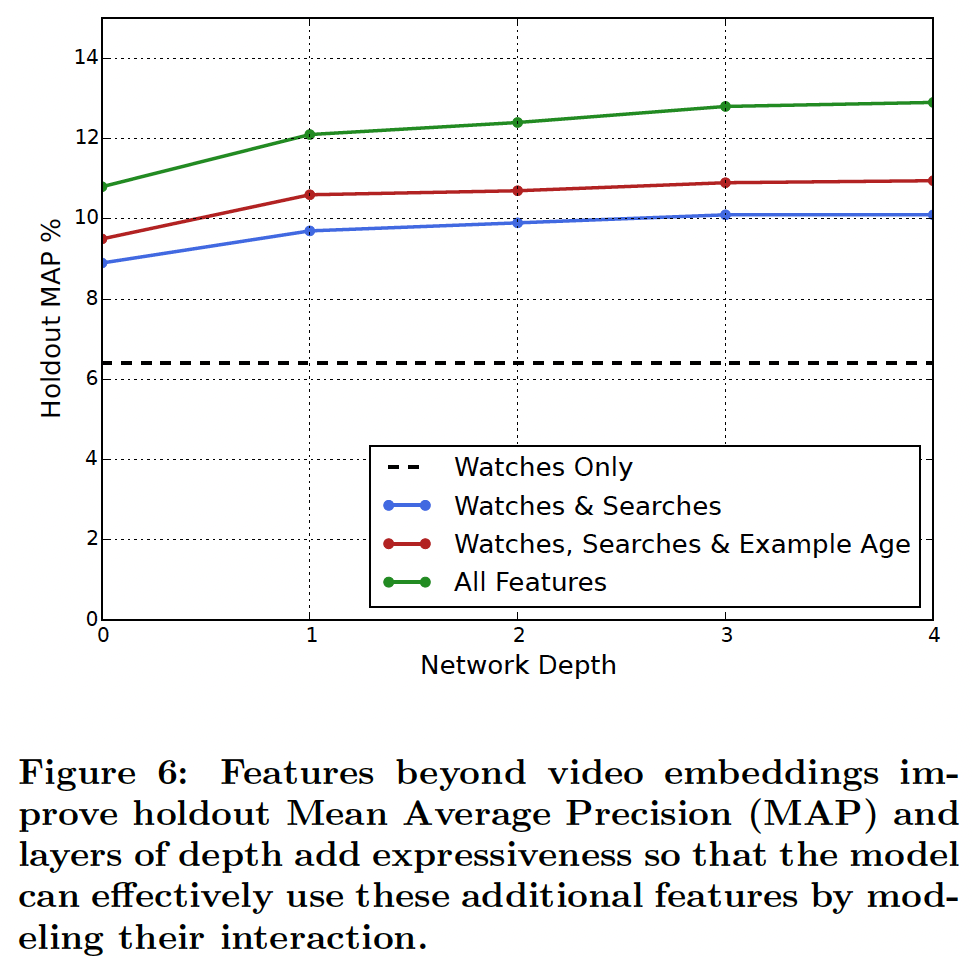
Experiments with Features and Depth
Adding features and depth significantly improves precision on holdout data as shown in Figure 6. In these experiments, a vocabulary of 1M videos and 1M search tokens were embedded with 256 floats each in a maximum bag size of 50 recent watches and 50 recent searches. The softmax layer outputs a multinomial distribution over the same 1M video classes with a dimension of 256 (which can be thought of as a separate output video embedding). These models were trained until convergence over all YouTube users, corresponding to several epochs over the data. Network structure followed a common “tower” pattern in which the bottom of the network is widest and each successive hidden layer halves the number of units (similar to Figure 3). The depth zero network is effectively a linear factorization scheme which performed very similarly to the predecessor system. Width and depth were added until the incremental benefit diminished and convergence became difficult:
그림 6에서 볼 수 있듯이 특징과 깊이를 추가하면 홀드아웃 데이터의 정밀도가 크게 향상됩니다. 이 실험에서는 1백만 개의 동영상과 1백만 개의 검색 토큰으로 구성된 어휘를 최근 시청 50개와 최근 검색 50개의 최대 가방 크기에 각각 256개의 플로트로 임베드했습니다. 소프트맥스 레이어는 동일한 1M 동영상 클래스에 대해 256 차원으로 다항식 분포를 출력합니다(별도의 출력 동영상 임베딩으로 생각할 수 있음). 이러한 모델은 데이터의 여러 시대에 해당하는 모든 YouTube 사용자에 대해 수렴할 때까지 학습되었습니다. 네트워크 구조는 네트워크의 맨 아래가 가장 넓고 연속되는 각 숨겨진 레이어가 유닛 수를 절반으로 줄이는 일반적인 “타워” 패턴을 따랐습니다(그림 3과 유사). 깊이 제로 네트워크는 사실상 선형 인수분해 방식이며, 이전 시스템과 매우 유사하게 작동했습니다. 점진적 이득이 감소하고 수렴이 어려워질 때까지 폭과 깊이가 추가되었습니다:
- Depth 0: A linear layer simply transforms the concatenation
layer to match the softmax dimension of 256 - Depth 1: 256 ReLU
- Depth 2: 512 ReLU → 256 ReLU
- Depth 3: 1024 ReLU → 512 ReLU → 256 ReLU
- Depth 4: 2048 ReLU → 1024 ReLU → 512 ReLU → 256 ReLU
Ranking
The primary role of ranking is to use impression data to specialize and calibrate candidate predictions for the particular user interface. For example, a user may watch a given video with high probability generally but is unlikely to click on the specific homepage impression due to the choice of thumbnail image. During ranking, we have access to many more features describing the video and the user’s relationship to the video because only a few hundred videos are being scored rather than the millions scored in candidate generation. Ranking is also crucial for ensembling different candidate sources whose scores are not directly comparable.
랭킹의 주요 역할은 노출 데이터를 사용하여 특정 사용자 인터페이스에 대한 후보 예측을 전문화하고 보정하는 것입니다. 예를 들어, 사용자가 특정 동영상을 일반적으로 높은 확률로 시청하지만 썸네일 이미지 선택으로 인해 특정 홈페이지 노출을 클릭할 가능성은 낮을 수 있습니다. 순위를 매기는 동안에는 후보 생성에서 수백만 개의 동영상이 점수화되는 대신 수백 개의 동영상만 점수화되기 때문에 동영상과 사용자와의 관계를 설명하는 더 많은 기능에 액세스할 수 있습니다. 순위는 점수가 직접적으로 비교할 수 없는 다양한 후보 소스를 조합하는 데에도 중요합니다.
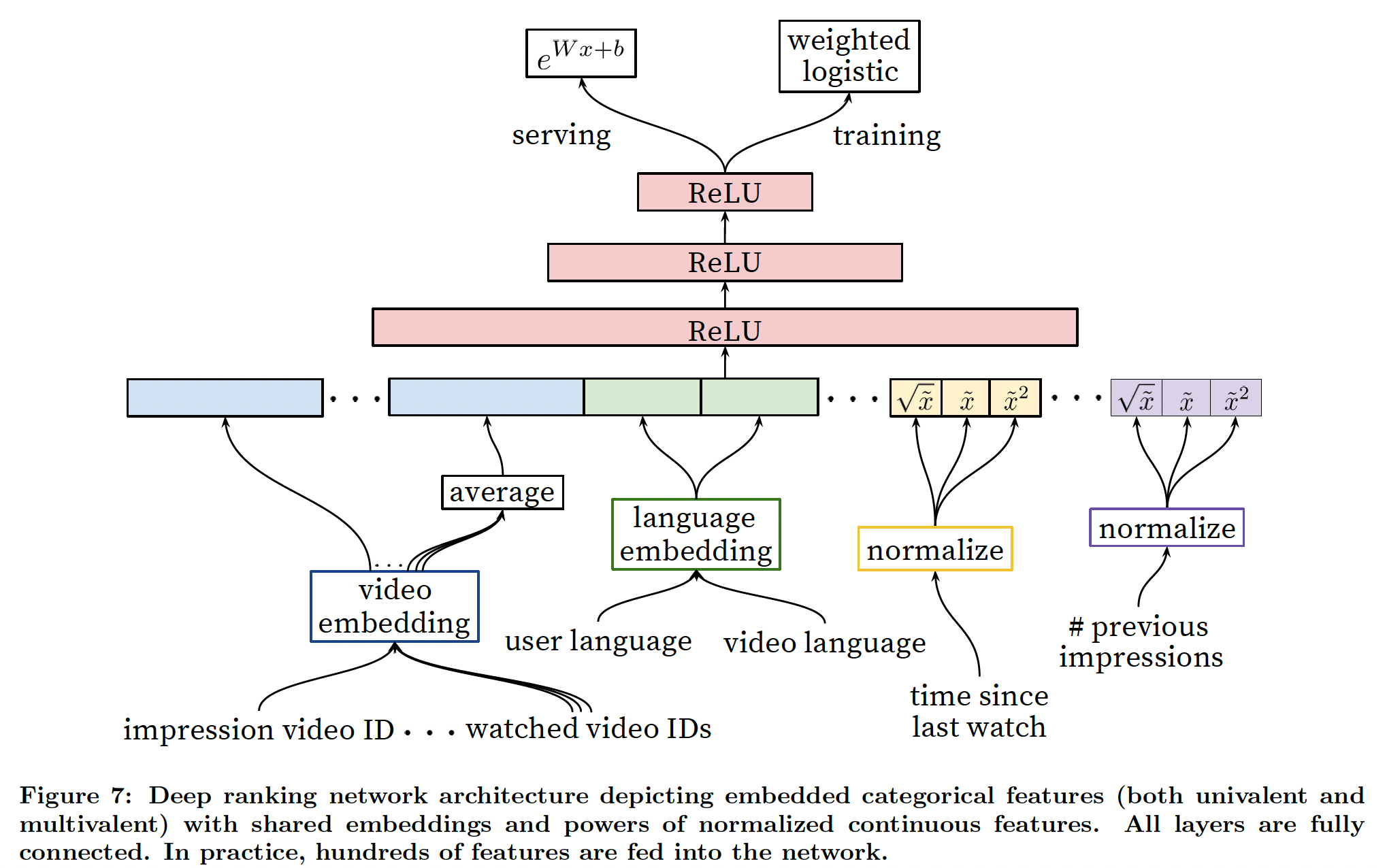
We use a deep neural network with similar architecture as candidate generation to assign an independent score to each video impression using logistic regression (Figure 7). The list of videos is then sorted by this score and returned to the user. Our final ranking objective is constantly being tuned based on live A/B testing results but is generally a simple function of expected watch time per impression. Ranking by click-through rate often promotes deceptive videos that the user does not complete (\clickbait”) whereas watch time better captures engagement [13, 25].
후보 생성과 유사한 아키텍처를 가진 심층 신경망을 사용하여 로지스틱 회귀를 통해 각 동영상 노출에 독립적인 점수를 부여합니다(그림 7). 그런 다음 동영상 목록은 이 점수에 따라 정렬되어 사용자에게 반환됩니다. 최종 순위 목표는 실시간 A/B 테스트 결과를 기반으로 지속적으로 조정되고 있지만, 일반적으로 노출당 예상 시청 시간이라는 간단한 함수를 사용합니다. 클릭률로 순위를 매기면 사용자가 완료하지 않는 기만적인 동영상(”클릭베이트”)을 홍보하는 경우가 많은 반면, 시청 시간은 참여도를 더 잘 파악할 수 있습니다[13, 25].
Feature Representation
Our features are segregated with the traditional taxonomy of categorical and continuous/ordinal features. The categorical features we use vary widely in their cardinality - some are binary (e.g. whether the user is logged-in) while others have millions of possible values (e.g. the user’s last search query). Features are further split according to whether they contribute only a single value (”univalent”) or a set of values (”multivalent”). An example of a univalent categorical feature is the video ID of the impression being scored, while a corresponding multivalent feature might be a bag of the last N video IDs the user has watched. We also classify features according to whether they describe properties of the item (”impression”) or properties of the user/context (”query”). Query features are computed once per request while impression features are computed for each item scored.
우리의 feature는 범주형 기능과 연속형/서수형 기능이라는 전통적인 분류 체계로 구분됩니다. 우리가 사용하는 범주형 피처는 카디널리티가 매우 다양합니다. 일부 피처는 이진(예: 사용자의 로그인 여부)인 반면, 다른 피처는 수백만 개의 가능한 값(예: 사용자의 마지막 검색 쿼리)을 가집니다. 기능은 단일 값만 제공하는지(‘1항’) 또는 여러 값의 집합을 제공하는지(‘2항’)에 따라 더 세분화됩니다. 단항 범주형 특징의 예로는 점수가 매겨진 노출의 동영상 ID를 들 수 있으며, 해당 다항 특징으로는 사용자가 마지막으로 시청한 N개의 동영상 ID를 묶은 것을 들 수 있습니다. 또한 항목의 속성(‘노출’)을 설명하는지, 아니면 사용자/컨텍스트의 속성(‘쿼리’)을 설명하는지에 따라 피처를 분류합니다. 쿼리 피처는 요청당 한 번 계산되며, 노출 피처는 점수가 매겨진 각 항목에 대해 계산됩니다.
Feature Engineering
We typically use hundreds of features in our ranking models, roughly split evenly between categorical and continuous. Despite the promise of deep learning to alleviate the burden of engineering features by hand, the nature of our raw data does not easily lend itself to be input directly into feedforward neural networks. We still expend considerable engineering resources transforming user and video data into useful features. The main challenge is in representing a temporal sequence of user actions and how these actions relate to the video impression being scored.
일반적으로 순위 모델에는 수백 개의 피처가 사용되며, 대략 범주형과 연속형으로 고르게 나뉩니다. 수작업으로 기능을 엔지니어링하는 부담을 덜어주는 딥러닝의 장점에도 불구하고, 원시 데이터의 특성상 피드포워드 신경망에 직접 입력하는 것은 쉽지 않습니다. 여전히 사용자 및 비디오 데이터를 유용한 기능으로 변환하는 데 상당한 엔지니어링 리소스를 투입하고 있습니다. 주요 과제는 사용자 행동의 시간적 순서와 이러한 행동이 점수화되는 비디오 노출과 어떻게 연관되는지를 표현하는 것입니다.
We observe that the most important signals are those that describe a user’s previous interaction with the item itself and other similar items, matching others’ experience in ranking ads [7]. As an example, consider the user’s past history with the channel that uploaded the video being scored - how many videos has the user watched from this channel? When was the last time the user watched a video on this topic? These continuous features describing past user actions on related
items are particularly powerful because they generalize well across disparate items. We have also found it crucial to propagate information from candidate generation into ranking in the form of features, e.g. which sources nominated this video candidate? What scores did they assign?
Features describing the frequency of past video impressions are also critical for introducing \churn” in recommendations (successive requests do not return identical lists). If a user was recently recommended a video but did not watch it then the model will naturally demote this impression on the next page load. Serving up-to-the-second impression and watch history is an engineering feat onto itself outside the scope of this paper, but is vital for producing responsive
recommendations.
Embedding Categorical Features
Similar to candidate generation, we use embeddings to map sparse categorical features to dense representations suitable for neural networks. Each unique ID space (\vocabulary”) has a separate learned embedding with dimension that increases approximately proportional to the logarithm of the number of unique values. These vocabularies are simple look-up tables built by passing over the data once before training. Very large cardinality ID spaces (e.g. video IDs or search query terms) are truncated by including only the top N after sorting based on their frequency in clicked impressions. Out-of-vocabulary values are simply mapped to the zero embedding. As in candidate generation, multivalent categorical feature embeddings are averaged before being fed in to the network.
Importantly, categorical features in the same ID space also share underlying emeddings. For example, there exists a single global embedding of video IDs that many distinct features
use (video ID of the impression, last video ID watched by the user, video ID that \seeded” the recommendation, etc.). Despite the shared embedding, each feature is fed separately into the network so that the layers above can learn specialized representations per feature. Sharing embeddings is important for improving generalization, speeding up training and reducing memory requirements. The overwhelming majority of model parameters are in these high-cardinality embedding spaces - for example, one million IDs embedded in a 32 dimensional space have 7 times more parameters than fully connected layers 2048 units wide.
TBC..