개요
- 이 노트북의 예제로 실습 진행
- 데이터 흐름: oracle → pub/sub → datastream → dataflow → bigquery → looker
- 전체적인 process
- compute engine에서 vm 인스턴스 생성
- 저장장소 Cloud Storage Bucket 생성
- 객체 변경사항에 대한 알림을 Pub/sub으로 전송하도록 bucket 구성
- Data stream을 만들어 google cloud storage에 오라클 데이터 복제
- DataFlow로 복제된 데이터를 json파일로 빅쿼리에 적재
- 빅쿼리로 데이터 분석 및 ML
- 루커로 시각화
- 본 포스트는 위 전체 프로세스에서 5~6번에 해당하는 내용(이전 내용 확인)
- DataFlow로 복제된 데이터를 json파일로 변환하여 Bigquery 적재 하는 방법을 알아보자
- BQML의 ARIMA_PLUS 대해서 알아보자
- 루커를 사용하지 않고 루커 스튜디오로 시각화
사례에서 활용된 DataFlow
- Dataflow Datastream to BigQuery 스트리밍 템플릿에 배포하여 Datastream에서 캡처한 변경사항을 BigQuery에 복제
- UDF를 만들고 사용하여 이 템플릿의 기능을 확장
수신 데이터를 처리할 수 있는 UDF 만들기
- UDF를 만들어 backfill된 데이터와 모든 새 수신 데이터에서 다음 작업을 수행
- backfill: 데이터 파이프라인을 운용할때 이미 지난 날짜를 기준으로 재처리하는 작업, 메우는 작업,
- 버그가 있거나 어떤 이유로 로직이 변경됐을때 전체 데이터를 새로 말아주어야 할때
- 컬럼 등의 메타 데이터가 변경되었을 때 이를 반영하기 위한 append 성의 작업이 필요할때
- 고객 결제 수단과 같은 민감한 정보를 수정
- 데이터 계보와 검색을 위해 Oracle 소스 테이블을 BigQuery에 추가
- backfill: 데이터 파이프라인을 운용할때 이미 지난 날짜를 기준으로 재처리하는 작업, 메우는 작업,
- 이 로직은 Datastream에서 생성된 JSON 파일을 입력 매개변수로 사용하는 자바스크립트 파일에서 캡처됨
Cloud Shell 세션에서 다음 코드를 복사하여
retail_transform.js파일에 저장- Oracle에서 추출한 json 파일을 암호화 해서 새로운 json 파일을 생성함.
1
2
3
4
5
6
7
8
9
10
11
12function process(inJson) {
var obj = JSON.parse(inJson),
includePubsubMessage = obj.data && obj.attributes,
data = includePubsubMessage ? obj.data : obj;
data.PAYMENT_METHOD = data.PAYMENT_METHOD.split(':')[0].concat("XXX");
data.ORACLE_SOURCE = data._metadata_schema.concat('.', data._metadata_table);
return JSON.stringify(obj);
}retail_transform.js file을 저장할 Cloud Storage 버킷을 만든 후 자바스크립트 파일을 새로 만든 버킷에 업로드합니다.- 위에서 생성된 json 파일을 새로운 버켓에 저장함
1
2
3
4gsutil mb gs://js-${BUCKET_NAME}
gsutil cp retail_transform.js \
gs://js-${BUCKET_NAME}/utils/retail_transform.js
Dataflow 작업 만들기
Cloud Shell에서 데드 레터 큐(DLQ) 버킷을 만든다: 이 버킷은 DataFlow에서 사용됨
- dead-letter-queue: 하나 이상의 Source Queue가 성공적으로 컨슘되지 못한 메세지들을 재전송하기 위해 사용하는 별도의 큐. DLQ에 쌓인 메세지들을 보면 왜 이 메세지들이 컨슈머에 의해 처리되지 못했는지를 알 수 있다.
1
gsutil mb gs://dlq-${BUCKET_NAME}
Dataflow 실행에 필요한 서비스 계정을 만들고 계정을
Dataflow Worker,Dataflow Admin,Pub/Sub Admin,BigQuery Data Editor,BigQuery Job User,Datastream Admin
역할에 할당1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29gcloud iam service-accounts create df-tutorial
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:df-tutorial@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:df-tutorial@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/dataflow.worker"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:df-tutorial@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:df-tutorial@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:df-tutorial@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/bigquery.jobUser"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:df-tutorial@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/datastream.admin"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:df-tutorial@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"자동 확장이 사용 설정되면 Dataflow VM이 TCP 포트 12345 및 12346에서 네트워크 트래픽과 통신하고 전송 및 수신할 수 있도록 방화벽 이그레스 규칙을 만든다: VM끼리 통신이 가능하게끔 하는 작업
1
2
3
4
5
6
7
8gcloud compute firewall-rules create fw-allow-inter-dataflow-comm \
--action=allow \
--direction=ingress \
--network=GCP_NETWORK_NAME \
--target-tags=dataflow \
--source-tags=dataflow \
--priority=0 \
--rules tcp:12345-12346Dataflow 작업을 만들고 실행 → Dataflow 콘솔을 확인하여 새 스트리밍 작업이 시작되었는지 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15export REGION=us-central1
gcloud dataflow flex-template run orders-cdc-template --region ${REGION} \
--template-file-gcs-location "gs://dataflow-templates/latest/flex/Cloud_Datastream_to_BigQuery" \
--service-account-email "df-tutorial@${PROJECT_ID}.iam.gserviceaccount.com" \
--parameters \
inputFilePattern="gs://${BUCKET_NAME}/",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/oracle_retail_sub",\
inputFileFormat="json",\
outputStagingDatasetTemplate="retail",\
outputDatasetTemplate="retail",\
deadLetterQueueDirectory="gs://dlq-${BUCKET_NAME}",\
autoscalingAlgorithm="THROUGHPUT_BASED",\
mergeFrequencyMinutes=1,\
javascriptTextTransformGcsPath="gs://js-${BUCKET_NAME}/utils/retail_transform.js",\
javascriptTextTransformFunctionName="process"Cloud Shell에서 다음 명령어를 실행하여 Datastream 스트림을 시작
1
2gcloud datastream streams update oracle-cdc \
--location=us-central1 --state=RUNNING --update-mask=stateDataStream 스트림 상태를 확인
1
2gcloud datastream streams list \
--location=us-central1상태가 Running으로 표시되는지 확인. 새 상태값이 반영되기까지 몇 초 정도 걸릴 수 있음.
Datastream 콘솔을 확인하여
ORDERS테이블 백필 진행 상황을 확인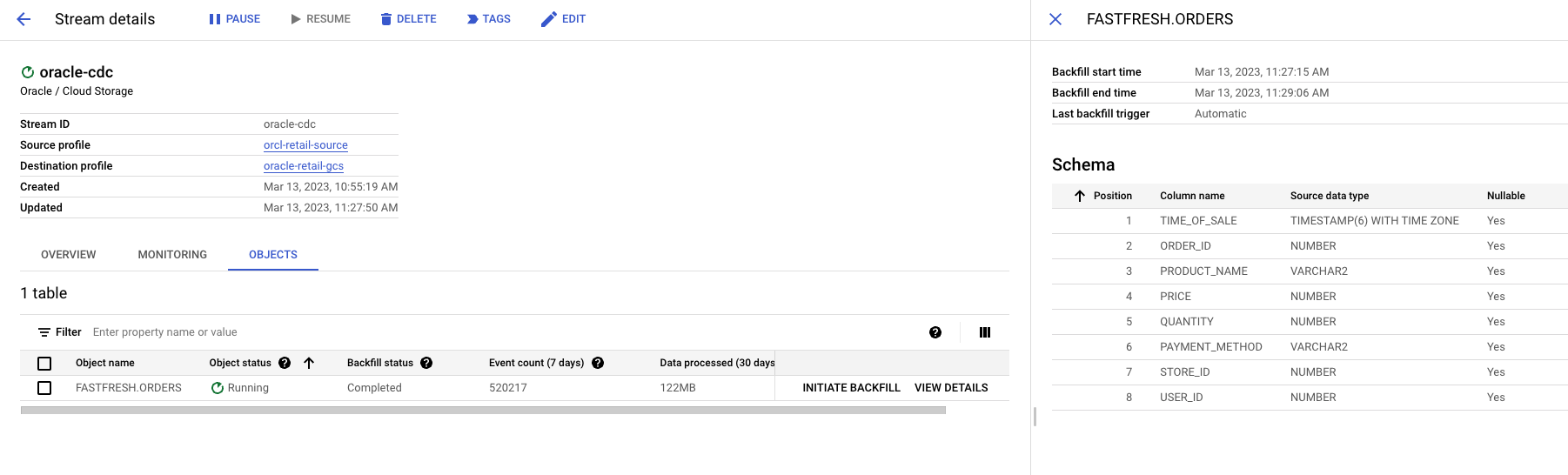
이 task는 초기 로드 이므로 Datastream은
ORDERS객체에서 읽음. 스트림 생성 중에 지정한 Cloud Storage 버킷에 있는 JSON 파일에 모든 레코드를 쓴다. 백필 태스크가 완료되는데 약 10분 정도 걸림.
BigQuery에서 데이터 분석
데이터 세트에서 다음 새 테이블 두 개가 Dataflow 작업으로 생성
ORDERS: 이 출력 테이블은 Oracle 테이블 복제본이며 Dataflow 템플릿의 일부로 데이터에 적용된 변환을 포함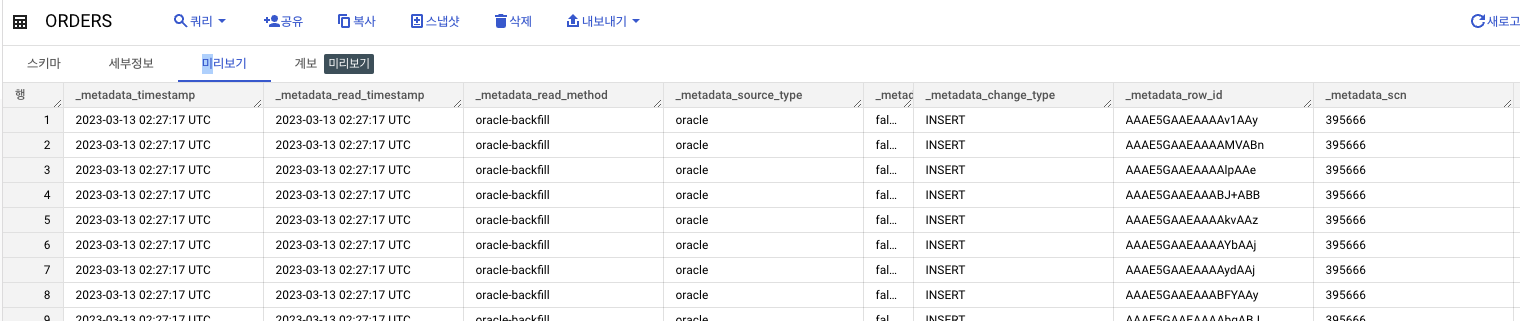
ORDERS_log: 이 스테이징 테이블은 Oracle 소스의 모든 변경사항을 기록. 테이블은 파티션으로 나눠지고 변경사항이 업데이트, 삽입 또는 삭제인지 여부와 같은 일부 메타데이터 변경 정보와 함께 업데이트된 레코드를 저장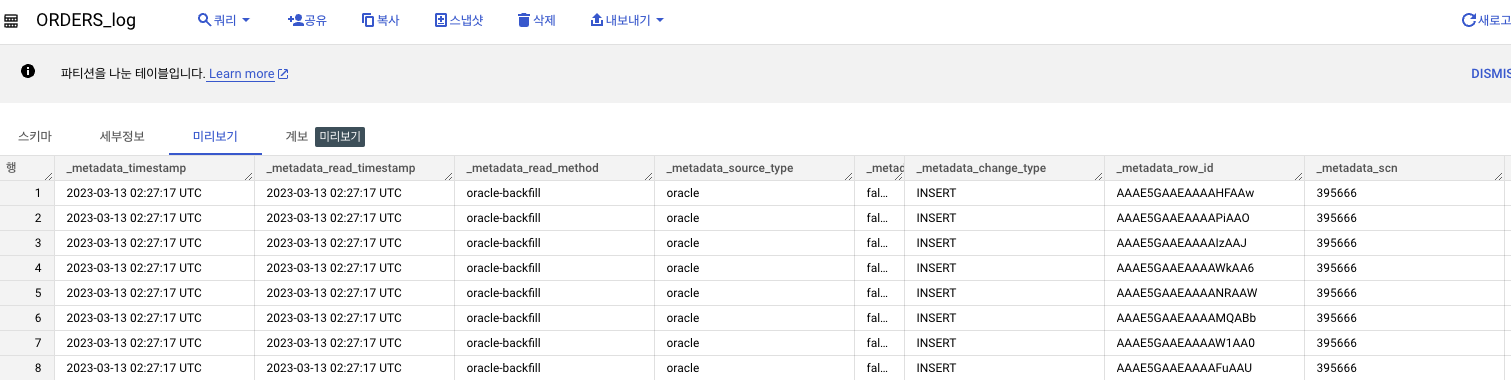
BigQuery ML에서 수요 예측 모델 빌드
- BigQuery ML은 ARIMA_PLUS 알고리즘을 사용하여 수요 예측 모델을 빌드하고 배포하는 데 사용될 수 있음. 이 섹션에서는 BigQuery ML을 사용하여 매장 내 제품 수요를 예측하는 모델을 빌드.
학습 데이터 준비
백필한 데이터의 샘플을 사용하여 모델을 학습
이 경우 1년 동안의 데이터를 사용합니다. 학습 데이터에서는 다음을 보여줍니다.
- 제품 이름(
product_name) - 판매된 각 제품의 단위 수량(
total_sold) - 시간당 판매된 제품 수(
hourly_timestamp)
- 제품 이름(
BigQuery에서 다음 SQL을 실행하여 학습 데이터를 만들고
training_data라는 새 테이블에 저장1
2
3
4
5
6
7
8
9
10
11CREATE OR REPLACE TABLE `retail.training_data`
AS
SELECT
TIMESTAMP_TRUNC(time_of_sale, HOUR) as hourly_timestamp,
product_name,
SUM(quantity) AS total_sold
FROM `retail.ORDERS`
GROUP BY hourly_timestamp, product_name
HAVING hourly_timestamp BETWEEN TIMESTAMP_TRUNC('2021-11-22', HOUR) AND
TIMESTAMP_TRUNC('2021-11-28', HOUR)
ORDER BY hourly_timestamp
예측 수요
BigQuery에서 다음 SQL을 실행하여
ARIMA_PLUS알고리즘을 사용하는 시계열 모델을 생성1
2
3
4
5
6
7
8
9
10
11
12
13CREATE OR REPLACE MODEL `retail.arima_plus_model`
OPTIONS(
MODEL_TYPE='ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL='hourly_timestamp',
TIME_SERIES_DATA_COL='total_sold',
TIME_SERIES_ID_COL='product_name'
) AS
SELECT
hourly_timestamp,
product_name,
total_sold
FROM
`retail.training_data`- ML.FORECAST함수는
n시간 범위에 걸쳐 예상되는 수요를 예측하는 데 사용됨
- ML.FORECAST함수는
다음 SQL을 실행하여 향후 30일 동안의 유기농 바나나 수요를 예측
1
SELECT * FROM ML.FORECAST(MODEL `retail.arima_plus_model`, STRUCT(720 AS horizon))
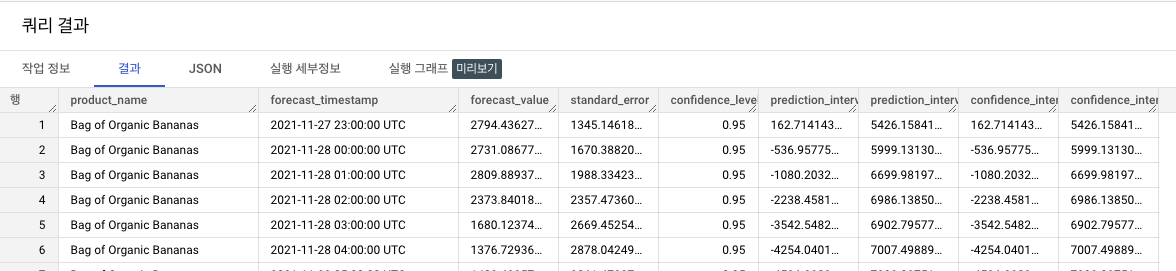
- 학습 데이터는 시간 단위이므로 범위 값은 예측 시 동일한 시간 단위(시간)를 사용. 720시간 범위 값은 다음 30일 동안의 예측 결과를 반환
- 이 튜토리얼에서는 소량의 샘플 데이터 세트를 사용하므로 모델의 정확성에 대한 자세한 조사는 이 튜토리얼에서 다루지 않음.
시각화하기
BigQuery에서 다음 SQL 쿼리를 실행하여 유기농 바나나의 실제 판매량과 예상 판매량을 통합하는 뷰를 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28CREATE OR REPLACE VIEW `retail.orders_forecast` AS (
SELECT
timestamp,
product_name,
SUM(forecast_value) AS forecast,
SUM(actual_value) AS actual
from
(
SELECT
TIMESTAMP_TRUNC(TIME_OF_SALE, HOUR) AS timestamp,
product_name,
SUM(QUANTITY) as actual_value,
NULL AS forecast_value
FROM `retail.ORDERS`
GROUP BY timestamp, product_name
UNION ALL
SELECT
forecast_timestamp AS timestamp,
product_name,
NULL AS actual_value,
forecast_value,
FROM ML.FORECAST(MODEL `retail.arima_plus_model`,
STRUCT(720 AS horizon))
ORDER BY timestamp
)
GROUP BY timestamp, product_name
ORDER BY timestamp
)- 이 뷰를 사용하면 실제 데이터와 예측 데이터를 탐색할 때 Looker에서 관련 데이터를 쿼리할 수 있음
다음 SQL을 실행하여 뷰를 검증
1
2
3
4SELECT * FROM `retail.orders_forecast`
WHERE PRODUCT_NAME='Bag of Organic Bananas'
AND TIMESTAMP_TRUNC(timestamp, HOUR) BETWEEN TIMESTAMP_TRUNC('2021-11-28', HOUR) AND TIMESTAMP_TRUNC('2021-11-30', HOUR)
LIMIT 100;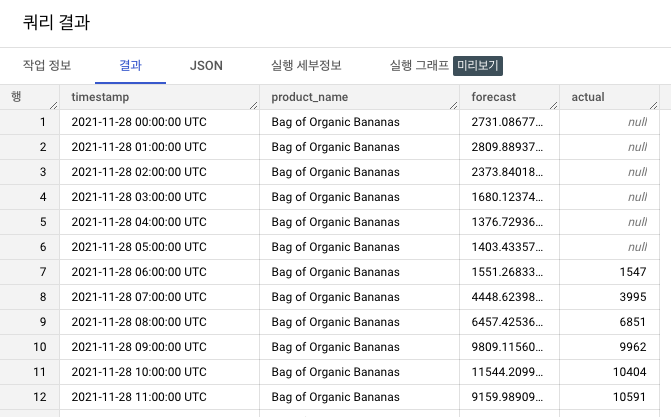
이전 포스팅의 ‘Big Query를 사용하여 SQL로 데이터를 정제한 후 Looker Studio에 SQL로 차트 만들기’ 처럼 sql쿼리로 데이터 셋을 생성
1
2SELECT * FROM `retail.orders_forecast`
WHERE actual IS NOT NULL결과 페이지
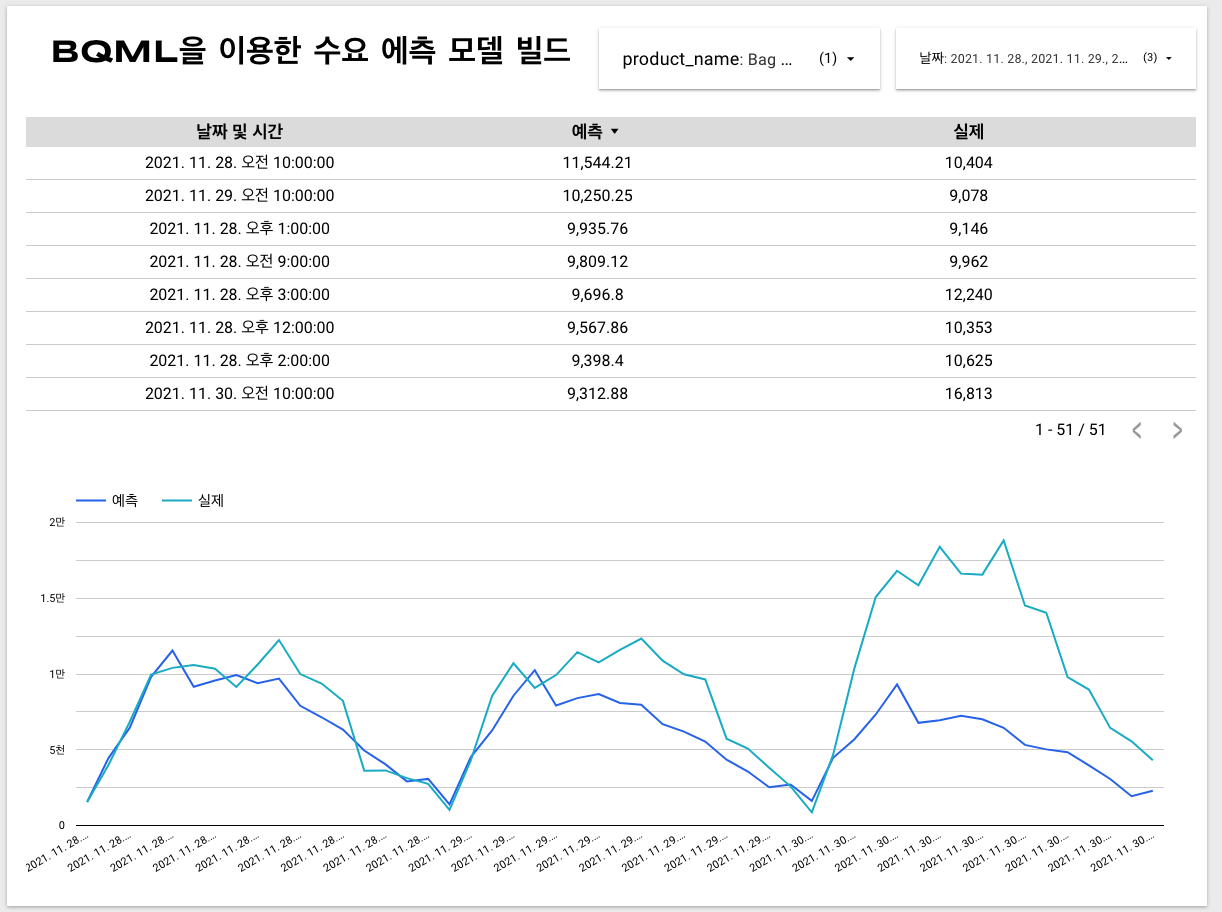
- 드롭다운 목록의 날짜 부분은 함수를 걸어 date형태로 조회할수 있게 하였음.
- Reference
- https://cloud.google.com/architecture/build-visualize-demand-forecast-prediction-datastream-dataflow-bigqueryml-looker?hl=ko#create-a-dataflow-job
- https://cloud.google.com/dataflow?hl=ko
- https://cloud.google.com/dataflow/pricing?hl=ko#shuffle-pricing-details
- https://velog.io/@usaindream/Dead-Letter-QueueDLQ
- https://wookiist.dev/175