개요
- 빅쿼리 ML을 사용하여 다양한 머신러닝 모델을 돌리기
- GA4와 빅쿼리 연동 시 추출되는 데이터들을 정제해서 머신러닝 훈련데이터로 만들기
- 각 모델의 평가, 파라미터들을 알아보고 조정해보기
목표
- 앱 설치 후 첫 24시간 동안의 사용자 활동을 기반으로 하는 “Flood It!” 데이터 세트를 사용하여 다양한 분류 모델을 시도하여 이탈 성향(1) 또는 이탈하지 않을 성향(0)을 예측
비용
- BigQuery 가격
- 분석 가격 책정: SQL 쿼리, 사용자 정의 함수, 스크립트, 테이블을 스캔하는 DML(데이터 조작 언어) 및 DDL(데이터 정의 언어)문을 포함한 쿼리를 처리할 때 발생하는 비용
- 주문분석형 가격책정
- (주문형)쿼리: 5$ per TB, 매월 1TB까지는 무료
- 정액제
- 월간 정액제: 슬롯 100개당 2000$
- 연간 정액제: 슬롯 100개당 1700$(달마다)
- 주문분석형 가격책정
- 스토리지 가격 책정: BigQuery에 로드한 데이터를 저장하는 데 드는 비용
- 분석 가격 책정: SQL 쿼리, 사용자 정의 함수, 스크립트, 테이블을 스캔하는 DML(데이터 조작 언어) 및 DDL(데이터 정의 언어)문을 포함한 쿼리를 처리할 때 발생하는 비용
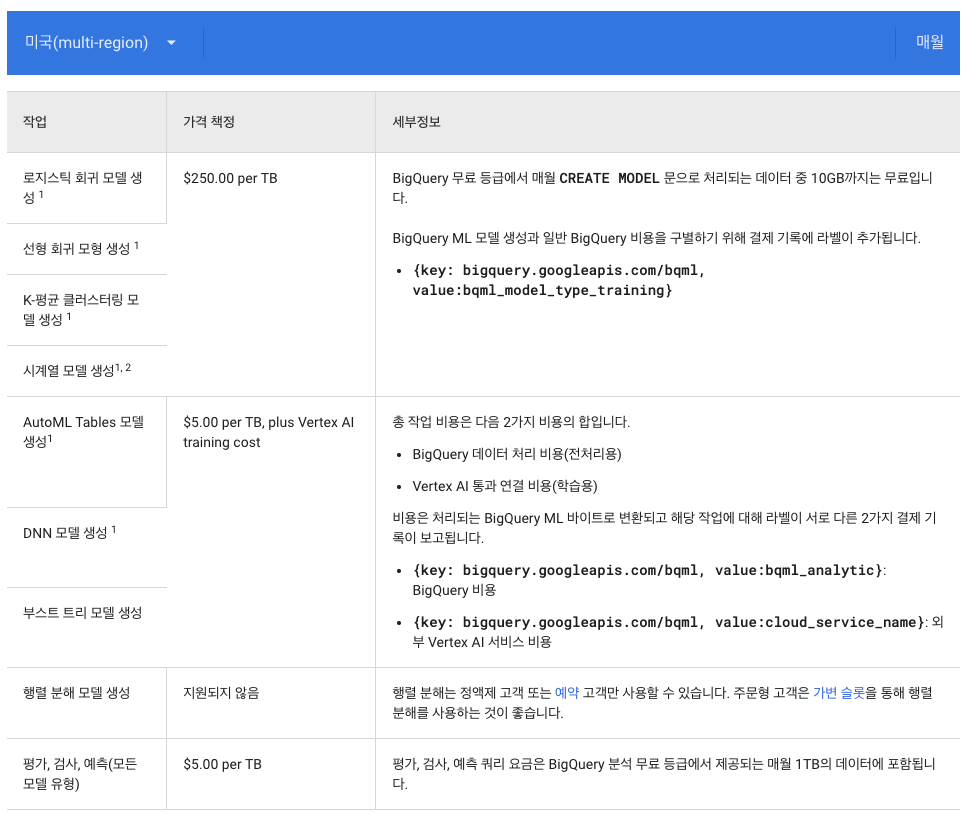
- BigQueyrML 가격
무료사용량 한도
- 스토리지: 매월 10GB
- 쿼리(분석): 매월 처리되는 쿼리 데이터중 최초 1TB는 무료
- BigQuery Storage Write API: 매월 처음 2TB는 무료
- BigQuery ML
CREATE MODEL쿼리: 매월 10GB까지는CREATE MODEL
문이 포함된 쿼리 데이터가 무료로 처리
주문형 가격
데이터
- 학습 데이터로 정제 하기
- 앱으로 복귀할 가능성이 없는 사용자를 필터링합니다.
- 사용자 인구통계 데이터에 대한 특성을 만듭니다.
- 사용자 행동 데이터에 대한 특성을 만듭니다.
- 인구통계 데이터 및 행동 데이터를 결합하면 더 효과적인 예측 모델을 만드는 데 도움이 된다.
- 처리 후 학습 데이터의 각 행은
user_pseudo_id열로 식별된 순 사용자의 데이터를 나타낸다.
전체 데이터 조회
→ GA4에서 넘어온 데이터 형식(스키마 및 각 열에 대한 세부 정보)
1 | SELECT |
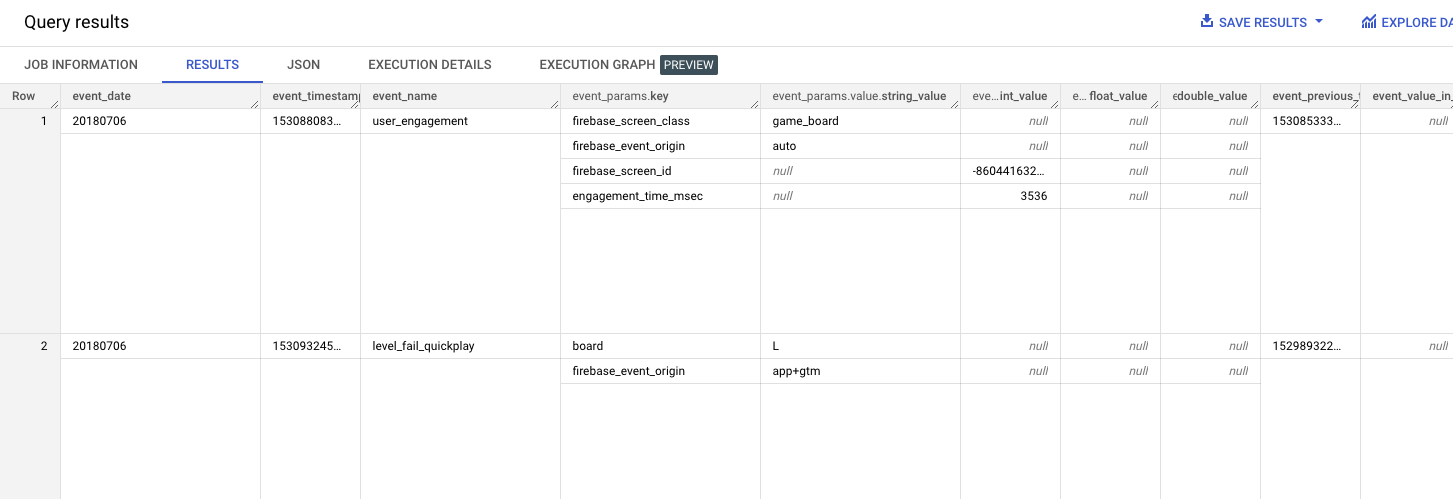
총 15000명의 유저와 5.7만개의 이벤트가 있는걸 볼수 있음
1
2
3
4
5SELECT
COUNT(DISTINCT user_pseudo_id) as count_distinct_users,
COUNT(event_timestamp) as count_events
FROM
`firebase-public-project.analytics_153293282.events_*`
학습 데이터로 정제하기
- User ID: 고유한 사용자 ID
- User demographic data: 인구 통계 학적 데이터
- User behavioral data: 행동 데이터
- Churned: 예측하고자 하는 실제 라벨(1=이탈, 0=귀환)

STEP 1: 각 유저에 대한 라벨 식별
사용자 이탈을 정의하는 방법에는 여러 가지가 있지만, 이 노트북에서는 사용자가 앱을 처음 사용한 후 24시간이 지나도 다시 앱을 사용하지 않는 사용자를 1일 이탈로 예측 → 사용자가 앱에 처음 참여한 후 24시간이 지난 후를 기준으로 합니다:
- 사용자가 그 이후 이벤트 데이터를 표시하지 않는 경우, 해당 사용자는 탈퇴한 것으로 간주됩니다.
- 사용자가 그 이후 이벤트 데이터 포인트가 하나 이상 있으면, 해당 사용자는 귀환한 것으로 간주됩니다.
앱에서 단 몇 분만 사용한 후 다시 돌아올 가능성이 낮은 사용자를 제거하고자 할 수도 있는데, 이를 “bouncing”이라고도 합니다. 예를 들어, 앱을 최소 10분 이상 사용한 사용자(이탈하지 않은 사용자)를 대상으로만 모델을 구축하고자 한다고 가정해 보겠습니다.
따라서 이 노트북의 이탈한 사용자에 대한 업데이트된 정의
“앱에서 10분 이상 시간을 보냈지만 앱을 처음 사용한 후 24시간이 지난 후 다시는 앱을 사용하지 않은 모든 사용자”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44CREATE OR REPLACE VIEW
`bqmlga4.returningusers` AS (
WITH firstlasttouch AS (
SELECT
user_pseudo_id,
MIN(event_timestamp) AS user_first_engagement,
MAX(event_timestamp) AS user_last_engagement
FROM
`firebase-public-project.analytics_153293282.events_*`
WHERE event_name="user_engagement"
GROUP BY
user_pseudo_id
)
SELECT
user_pseudo_id,
user_first_engagement,
user_last_engagement,
EXTRACT(MONTH from TIMESTAMP_MICROS(user_first_engagement)) as month,
EXTRACT(DAYOFYEAR from TIMESTAMP_MICROS(user_first_engagement)) as julianday,
EXTRACT(DAYOFWEEK from TIMESTAMP_MICROS(user_first_engagement)) as dayofweek,
#add 24 hr to user's first touch
(user_first_engagement + 86400000000) AS ts_24hr_after_first_engagement,
#churned = 1 if last_touch within 24 hr of app installation, else 0
IF (user_last_engagement < (user_first_engagement + 86400000000),
1,
0 ) AS churned,
#bounced = 1 if last_touch within 10 min, else 0
IF (user_last_engagement <= (user_first_engagement + 600000000),
1,
0 ) AS bounced,
FROM
firstlasttouch
GROUP BY
1,2,3
);
SELECT
*
FROM
`bqmlga4.returningusers`Churned 열의 경우 첫 24시간이 지난 후에 액션을 수행하면 Churned =0이 되고 그렇지 않으면 마지막 액션이 첫 24시간 이내에만 이루어진 경우 Churned=1이 된다.
Bounced 열의 경우 사용자의 마지막 동작이 앱을 처음 터치한 후 10분 이내인 경우 bounced = 1, 그렇지 않으면 bounced=0
이 15000명의 사용자 중 몇명이 이탈했다가 다시 돌아왔는지 확인
1
2
3
4
5
6
7
8SELECT
bounced,
churned,
COUNT(churned) as count_users
FROM
bqmlga4.returningusers
GROUP BY 1,2
ORDER BY bounced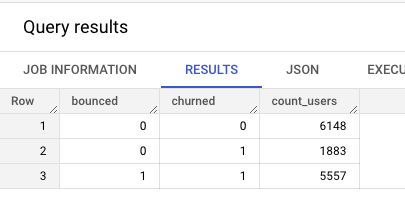
- 15000명의 사용자를 기준으로 5,557명(41%)의 사용자가 앱을 처음 사용한 후 10분 이내에 이탈했지만 나머지 8,031명의 사용자 중 1,883(23%)이 24시간 후에 이탈한 것을 확인
학습 데이터의 경우 bounce=0인 데이터만 사용함 → 이미 귀환한 유저에 대해서는 할 필요가 없기 때문
1
2
3
4
5SELECT
COUNTIF(churned=1)/COUNT(churned) as churn_rate
FROM
bqmlga4.returningusers
WHERE bounced = 0
STEP 2: 각 사용자에 대한 인구 통계 데이터 추출
앱정보, 기기, 이커머스, 이벤트 파라미터, 지역 등 사용자에 대한 인구통계학적 데이터 추출
자체 데이터 세트를 사용하고 있고 조인 가능한 first-party data가 있는 경우 이 섹션은 GA4에서 쉽게 사용할 수 없는 각 사용자에 대한 추가 속성을 추가할 수 있는 좋은 기회
인구통계는 변경가능성이 있음.
간단하게 설명하기 위해 사용자가 앱에 처음접속 했을때 구글 애널리틱스 4가 제공하는 인구통계학적 정보를 MIN(event_timestamp)로 표시된대로만 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21CREATE OR REPLACE VIEW bqmlga4.user_demographics AS (
WITH first_values AS (
SELECT
user_pseudo_id,
geo.country as country,
device.operating_system as operating_system,
device.language as language,
ROW_NUMBER() OVER (PARTITION BY user_pseudo_id ORDER BY event_timestamp DESC) AS row_num
FROM `firebase-public-project.analytics_153293282.events_*`
WHERE event_name="user_engagement"
)
SELECT * EXCEPT (row_num)
FROM first_values
WHERE row_num = 1
);
SELECT
*
FROM
bqmlga4.user_demographics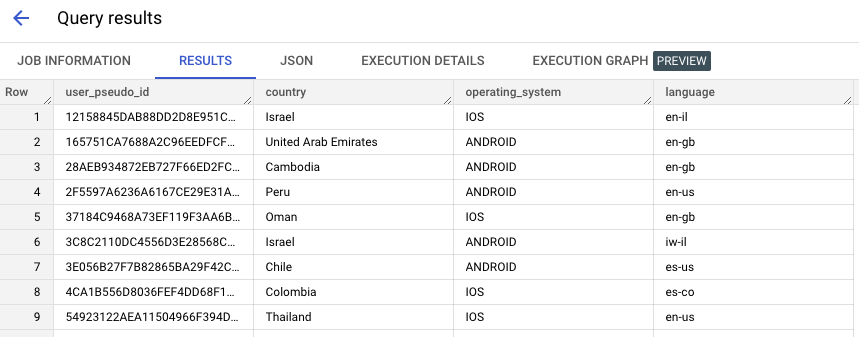
STEP 3: 각 사용자에 대한 행동 데이터 추출
첫 24시간 동안의 사용자 활동을 기반으로 해당 사용자의 이탈 또는 재방문 여부를 예측 → 첫 24시간 행동 데이터만 학습 시켜야 함
‘user_first_engagement’에서 첫 인게이지먼트의 월 또는 일과 같은 추가 시간 관련 기능을 추출할 수도 있음
우선 event_name을 기준으로 데이터 세트에 존재하는 모든 고유 이벤트를 탐색 → 총 37개의 이벤트
1
2
3
4
5
6
7
8SELECT
event_name,
COUNT(event_name) as event_count
FROM
`firebase-public-project.analytics_153293282.events_*`
GROUP BY 1
ORDER BY
event_count DESC여기서 user_engagement, level_start_quickplay, level_end_quickplay, level_complete_quickplay, level_reset_quickplay, post_score, spend_virtual_currency, ad_reward, challenge_a_friend, completed_5_levels, use_extra_steps → 이 피처들만 가지고 각각 유저가 몇번이나 이 이벤트를 발생시켰는지 확인
자체 데이터 세트를 사용하는 경우 집계 및 추출할 수 있는 이벤트 유형이 다를 수 있음.
앱이 GA에 매우 다른 event_names를 전송할수 있으므로 시나리오 가장 적합한 이벤트를 사용해야 함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38CREATE OR REPLACE VIEW bqmlga4.user_aggregate_behavior AS (
WITH
events_first24hr AS (
#select user data only from first 24 hr of using the app
SELECT
e.*
FROM
`firebase-public-project.analytics_153293282.events_*` e
JOIN
bqmlga4.returningusers r
ON
e.user_pseudo_id = r.user_pseudo_id
WHERE
e.event_timestamp <= r.ts_24hr_after_first_engagement
)
SELECT
user_pseudo_id,
SUM(IF(event_name = 'user_engagement', 1, 0)) AS cnt_user_engagement,
SUM(IF(event_name = 'level_start_quickplay', 1, 0)) AS cnt_level_start_quickplay,
SUM(IF(event_name = 'level_end_quickplay', 1, 0)) AS cnt_level_end_quickplay,
SUM(IF(event_name = 'level_complete_quickplay', 1, 0)) AS cnt_level_complete_quickplay,
SUM(IF(event_name = 'level_reset_quickplay', 1, 0)) AS cnt_level_reset_quickplay,
SUM(IF(event_name = 'post_score', 1, 0)) AS cnt_post_score,
SUM(IF(event_name = 'spend_virtual_currency', 1, 0)) AS cnt_spend_virtual_currency,
SUM(IF(event_name = 'ad_reward', 1, 0)) AS cnt_ad_reward,
SUM(IF(event_name = 'challenge_a_friend', 1, 0)) AS cnt_challenge_a_friend,
SUM(IF(event_name = 'completed_5_levels', 1, 0)) AS cnt_completed_5_levels,
SUM(IF(event_name = 'use_extra_steps', 1, 0)) AS cnt_use_extra_steps,
FROM
events_first24hr
GROUP BY
1
);
SELECT
*
FROM
bqmlga4.user_aggregate_behavior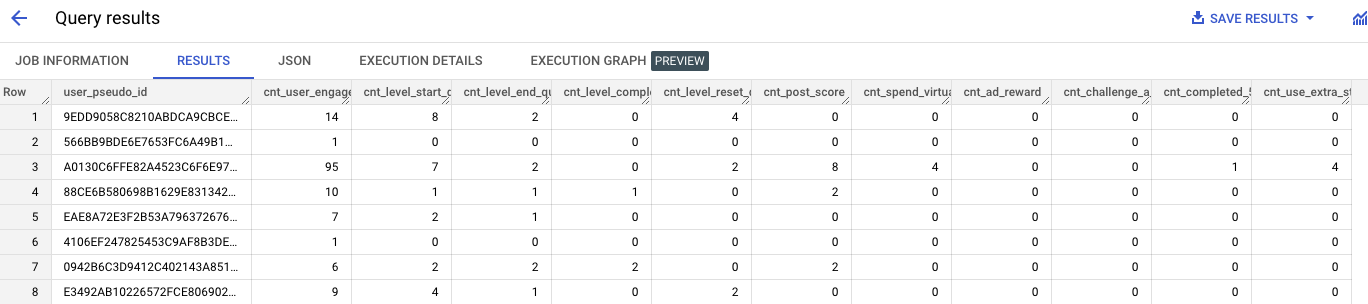
이 단계는 동작 수행 빈도 외에도 사용자가 사용한 게임 내 화폐의 총액이나 앱과 더 관련이 있을수 있는 특정 앱별 마일스톤(예: 특정 임계값의 경험치 획득 또는 5회 이상 레벨업)에 도달했는지 여부와 같은 다른 행동 특징을 포함할수 있다는 점에 유의.
STEP 4: 세 데이터 결합하여 학습데이터 구축
최종 학습 데이터 베이스 구축: 여기어세 bounce=0을 지정하여 앱 사용후 처음 10분 이내에 bounce하지 않은 사용자로만 학습 데이터를 제할할 수도 있음.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37CREATE OR REPLACE VIEW bqmlga4.train AS (
SELECT
dem.*,
IFNULL(beh.cnt_user_engagement, 0) AS cnt_user_engagement,
IFNULL(beh.cnt_level_start_quickplay, 0) AS cnt_level_start_quickplay,
IFNULL(beh.cnt_level_end_quickplay, 0) AS cnt_level_end_quickplay,
IFNULL(beh.cnt_level_complete_quickplay, 0) AS cnt_level_complete_quickplay,
IFNULL(beh.cnt_level_reset_quickplay, 0) AS cnt_level_reset_quickplay,
IFNULL(beh.cnt_post_score, 0) AS cnt_post_score,
IFNULL(beh.cnt_spend_virtual_currency, 0) AS cnt_spend_virtual_currency,
IFNULL(beh.cnt_ad_reward, 0) AS cnt_ad_reward,
IFNULL(beh.cnt_challenge_a_friend, 0) AS cnt_challenge_a_friend,
IFNULL(beh.cnt_completed_5_levels, 0) AS cnt_completed_5_levels,
IFNULL(beh.cnt_use_extra_steps, 0) AS cnt_use_extra_steps,
ret.user_first_engagement,
ret.month,
ret.julianday,
ret.dayofweek,
ret.churned
FROM
bqmlga4.returningusers ret
LEFT OUTER JOIN
bqmlga4.user_demographics dem
ON
ret.user_pseudo_id = dem.user_pseudo_id
LEFT OUTER JOIN
bqmlga4.user_aggregate_behavior beh
ON
ret.user_pseudo_id = beh.user_pseudo_id
WHERE ret.bounced = 0
);
SELECT
*
FROM
bqmlga4.train
학습데이터로 빅쿼리 ML 학습하기
- 이진분류 작업이므로 간단하게 logistic regression으로 시작할수 있지만 다른 모델도 사용 가능하다.
| M o d e l | Advantage | Disadvantage |
|---|---|---|
| Logistic Regression | ||
| LOGISTIC_REG | 다른 타입에 비해 학습 시간이 빠름 | 모델 성능이 조금 떨어짐 |
| XGBoost | ||
| BOOSTED_TREE_CLASSIFIER | 높은 모델 수행 능력 | feature importance를 검사할수 있다, LOGISTIC_REG 에 비해 학습 시간이 느림 |
| Deep Neural Networks | ||
| DNN_CLASSIFIER | 높은 모델 수행 능력 | LOGISTIC_REG 에 비해 학습 시간이 느림 |
| AutoML | ||
| AUTOML_CLASSIFIER | 매우 높은 모델 수행 능력 | 적어도 몇시간 정도 훈련시간이 걸리고 모델이 어떻게 작동하는지 설명하기 쉽지 않음 |
- 훈련, 테스트 셋으로 분할하지 않아도 CREATE MODEL문을 실행하면 BigQuery ML이 자동적으로 학습하기 때문에 학습 후 바로 모델을 평가 할수 있음
- 하이퍼 파라미터 튜닝: 각 모델에 대한 하이퍼파라미터를 튜닝할수 도 있음(link)
1 | CREATE OR REPLACE MODEL bqmlga4.churn_logreg |
AutoML
- AutoML Tables를 사용하면 구조화된 데이터에 대한 최신 머신러닝 모델을 속도와 규모를 대폭 향상 시켜 자동으로 구축할 수 있음.
- AutoML Tables는 구글의 모델 집단에서 구조화된 데이터를 자동으로 검색하여 간단한 데이터 집합을 위한 선형/로지스틱 휘귀모델부터 더 크고 복잡한 데이터 집합을 위한 고급 심층, 앙상블 및 아키텍쳐 검색 방법에 이르기까지 사용자의 요구에 가장 적합한 모델을 찾아줌.
- BUDGET_HOURS 매개변수는 AutoML 테이블 학습을 위한 것으로 시간 단위로 지정됨. 기본값은 1.0이며 1.0에서 72.0사이여야 함.
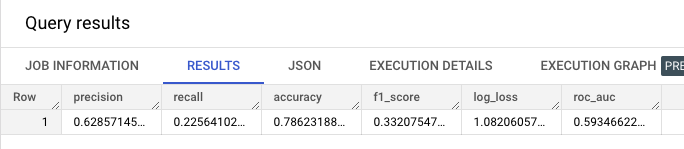
모델 평가
Logistic Regression
1 | SELECT |
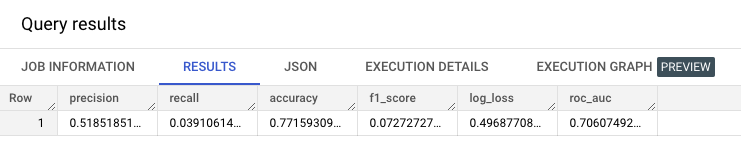
XGBoost
1 | SELECT |
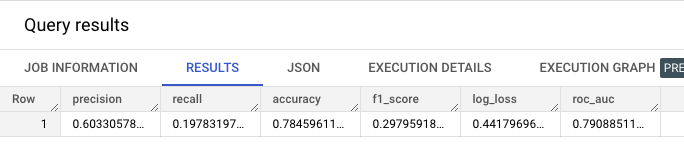
DNN
1 | SELECT |
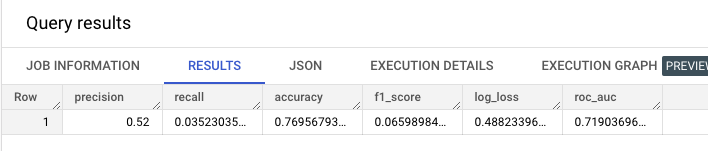
AutoML
1 | SELECT |
모델 예측
이탈 성향에 대한 예측을 할 수 있음
1
2
3
4
5SELECT
*
FROM
ML.PREDICT(MODEL bqmlga4.churn_logreg,
(SELECT * FROM bqmlga4.train)) #can be replaced with a test dataset성향 모델링에서 가장 중요한 출력은 행동이 발생할 확률.
밑의 코드는 사용자가 24시간 후에 재방문할 확률을 반환 → 확률이 높고 1에 가까울수록 사용자가 이탈할 가능성이 높고, 0에 가까울수록 사용자가 재방문할 가능성이 높음
1
2
3
4
5
6
7
8
9SELECT
user_pseudo_id,
churned,
predicted_churned,
predicted_churned_probs[OFFSET(0)].prob as probability_churned
FROM
ML.PREDICT(MODEL bqmlga4.churn_logreg,
(SELECT * FROM bqmlga4.train)) #can be replaced with a proper test dataset
빅쿼리 밖으로 예측 결과 export
Bigquery Storage API를 사용하여 데이터를 Pandas 데이터 프레임으로 내보낼수 있음(문서 및 코드 샘플)
다른 BigQuery 클라이언트 라이브러리를 사용할수도 있음.
별도의 서비스에서 사용할 수 있도록 예측 테이블을 Google 클라우드 스토리지(GCS)로 직접 보낼수도 있음 → 가장 쉬운 방법은 SQL을 사용하여 GCS로 직접 보내는 것
1
2
3
4
5
6
7
8
9
10
11
12EXPORT DATA OPTIONS (
uri="gs://mybucket/myfile/churnpredictions.csv",
format=CSV
) AS
SELECT
user_pseudo_id,
churned,
predicted_churned,
predicted_churned_probs[OFFSET(0)].prob as probability_churned
FROM
ML.PREDICT(MODEL bqmlga4.churn_logreg,
(SELECT * FROM bqmlga4.train)) #can be replaced with a proper test dataset