개인 연간 소득이 5만 달러 이상인지 예측하기
개요
- GCP에서 BQML 사용하기
- BQML의 로지스틱 회귀 모델 유형으로 supervised learning을 지원하는 기능 사용
- 바이너리/멀티 로지스틱 회귀 모형을 사용하면 값이 두/여러 범주 중 하나에 속할지 예측할 수 있다.
- 데이터를 둘 이상의 범주로 분류하려는 문제
bigquery-public-data.ml_datasets.census_adult_income데이터 사용
목표
- 로지스틱 회귀 모델을 만들고 평가한다.
- 로지스틱 회귀 모델을 사용하여 예측한다.
비용
0단계: public-dataset 가져오기
GCP BigQuery로 이동하여 프로젝트를 만들고, 프로젝트 밑에
+ADD DATA를 클릭한다
Public Datasets를 선택한다
데이터 셋중 아무거나 선택 한 후
VIEW DATASET을 선택하면 새 창이 뜨면서 구글 퍼블릭데이터 셋이 연결 된다.
이번 포스팅에서 다룰 데이터는
bigquery-public-data.ml_datasets.census_adult_income이다. 아래처럼 창이 뜨면 빅쿼리SQL을 사용할 준비가 다 되었다.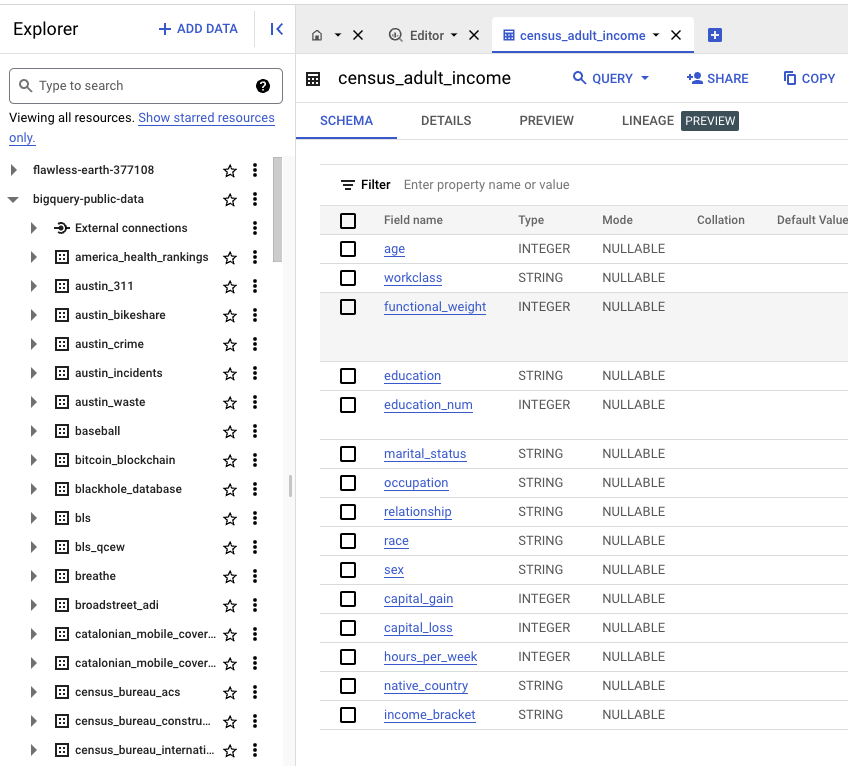
1단계: 데이터 세트 만들기
내 프로젝트를 선택하고 옆에 점세개를 누르고
Create dataset을 눌러서 데이터 세트를 만든다.
데이터 세트 ID에
census를 입력한다리전을 미국(US)로 선택한다 → public dataset이 US멀티 리전에 있기 때문. 같은 리전에 두어야 혼선을 막을수 있다.
만들어진 데이터 셋을 확인할 수 있다.
2단계: 데이터 확인 및 EDA
데이터 확인
- age(나이): 개인의 나이를 연단위로 나타냅니다
- workclass(노동 계급): 개인의 고용형태
- functional_weight: 일련의 관측결과를 바탕으로 인구조사국이 부여하는 개인의 가중치
- education: 개인의 최종학력
- education_num: 교육수준을 숫자로 범주화 하여 열거 합니다. 숫자가 높을수록 개인의 교육수준이 높습니다.
- marital_status: 개인의 결혼 여부 입니다.
- occupation: 개인의 직업입니다.
- relationship: 가정 내 각 개인의 관계입니다.
- race: 인종을 나타냅니다
- sex: 개인의 성별입니다.
- capital_gain: 개인의 자본 이익을 미국 달러로 표기 합니다.
- capital_loss: 개인의 자본 손실을 미국 달러로 표기 합니다.
- hours_per_week: 주당 근무시간입니다.
- native_country: 개인의 출신 국가 입니다.
- income_bracket: 개인의 연간 소득이 미화 50,000달러가 넘는지 여부를 나타냅니다
예측 작업: 개인의 연간 소득이 50,000달러 이상인지 확인해보기
쿼리 실행
1
2
3
4
5
6
7
8
9
10
11
12SELECT
age,
workclass,
marital_status,
education_num,
occupation,
hours_per_week,
income_bracket
FROM
`bigquery-public-data.ml_datasets.census_adult_income`
LIMIT
100;쿼리 실행 결과
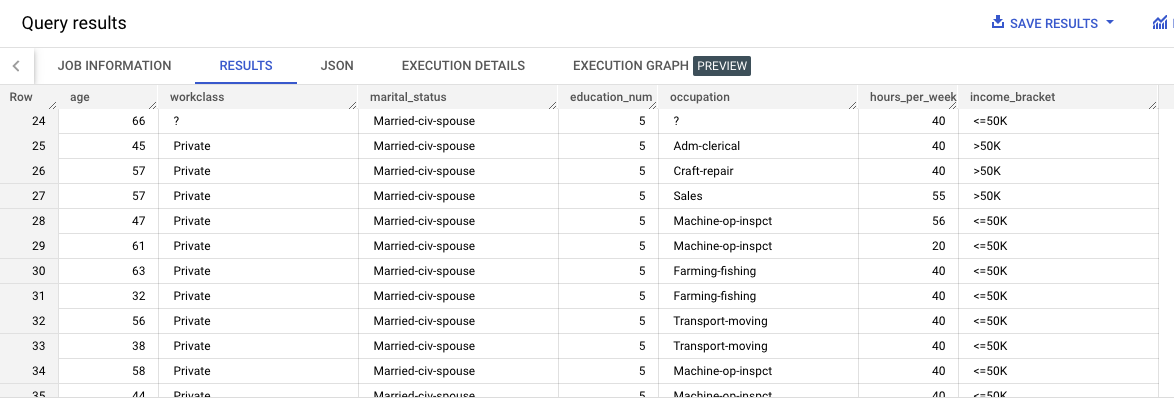
분석
income_bracket:<=50K또는>50K값중 하나만 있음education,education_num→ 동일한 데이터가 서로 다른 형식으로 표기되어 있음functional_weight: 인구 조사 기관에서 특정행이 대표한다고 판단하는 개인의 수 → 우리가 원하는 income 예측과는 관련이 없음.
3단계: 학습 데이터 선택
학습에 필요한 데이터 선택
- age: 연령
- workclass: 고용형태
- marital_status: 결혼여부
- education_num: 교육수준
- occupation: 직업
- hours_per_week: 주당 근무시간
학습 데이터를 컴파일 하는 뷰를 만든다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17CREATE OR REPLACE VIEW
`census.input_view` AS
SELECT
age,
workclass,
marital_status,
education_num,
occupation,
hours_per_week,
income_bracket,
CASE
WHEN MOD(functional_weight, 10) < 8 THEN 'training'
WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation'
WHEN MOD(functional_weight, 10) = 9 THEN 'prediction'
END AS dataframe
FROM
`bigquery-public-data.ml_datasets.census_adult_income`education, education_num 등과 같은 중복되는 카테고리를 제외한다.
functional_weight 는 income_bracket과 상관이 없는 컬럼이므로 라벨링으로 사용한다.
80%training, 10% 평가, 10% 예측
MOD(X,Y): X를 Y로 나눴을때의 나머지
위 쿼리를 수행시키면 1단계에서 만든 census에 input_view가 만들어졌음을 알수 있다.
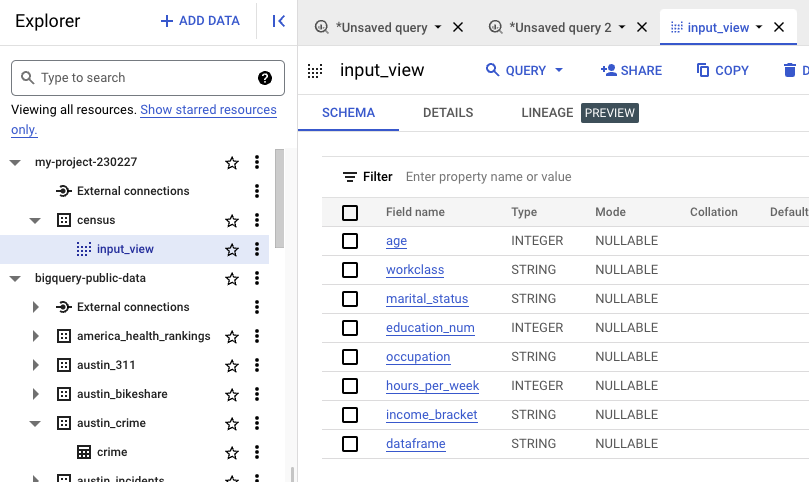
4단계: 로지스틱 회귀모델 만들기
Create Model문을LOGISTIC_REG옵션과 함께 사용하면 로지스틱 회귀 모델을 만들고 학습 시킬수 있다.1
2
3
4
5
6
7
8
9
10
11
12
13CREATE OR REPLACE MODEL
`census.census_model`
OPTIONS
( model_type='LOGISTIC_REG',
auto_class_weights=TRUE,
input_label_cols=['income_bracket']
) AS
SELECT
* EXCEPT(dataframe)
FROM
`census.input_view`
WHERE
dataframe = 'training'CREATE MODEL문은SELECT문의 학습 데이터를 사용하여 모델을 학습 시킨다.OPTIONS절은 모델 유형과 학습 옵션을 지정한다.- 여기서
LOGISTIC_REG옵션은 로지스틱 회귀 모델 유형을 지정한다. - 바이너리 로지스틱 회귀모델과 멀티클래스 로지스틱 회귀모델을 구분하여 지정할 필요는 없다.
- BigQuery ML은 라벨열 고유 값 수 기반으로 학습 대상을 결정할 수 있다. → 고유 값 수에 따라서 자동으로 선택하여 학습함
- 여기서
input_label_cols옵션은 SELECT 문에서 라벨 열로 사용할 열을 지정한다. 여기서 라벨 열은income_bracket이므로 모델은 각 행에 있는 다른 값을 기반으로income_bracket의 두 값 중 가장 가능성이 높은 값을 학습 한다.SELECT문은 2단계의 뷰를 사용한다. 이 뷰에는 모델 학습용 특성 데이터가 포함된 열만 포함된다.WHERE절은 학습데이터 프레임에 속하는 행만 학습 데이터에 포함되도록input_view의 행을 필터링 한다.
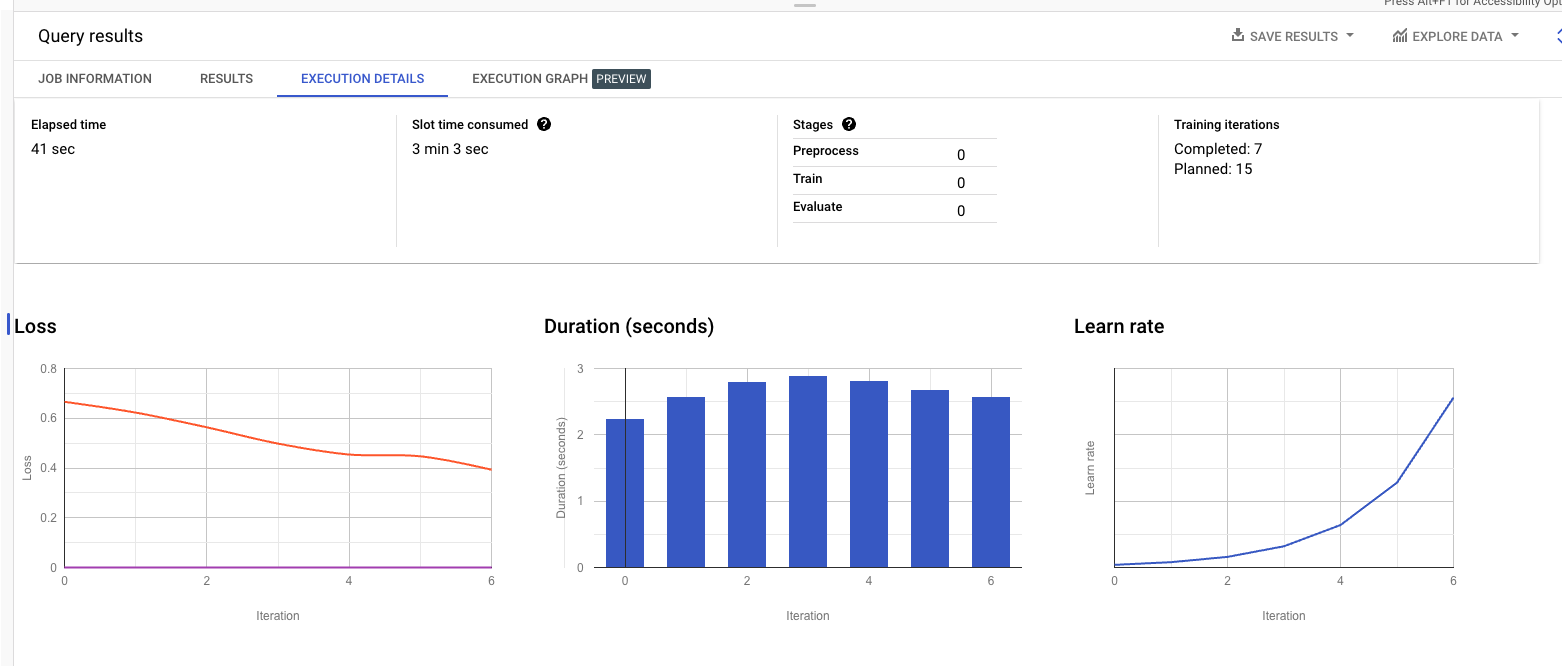
CREATE MODEL 쿼리 실행
1 | CREATE OR REPLACE MODEL |
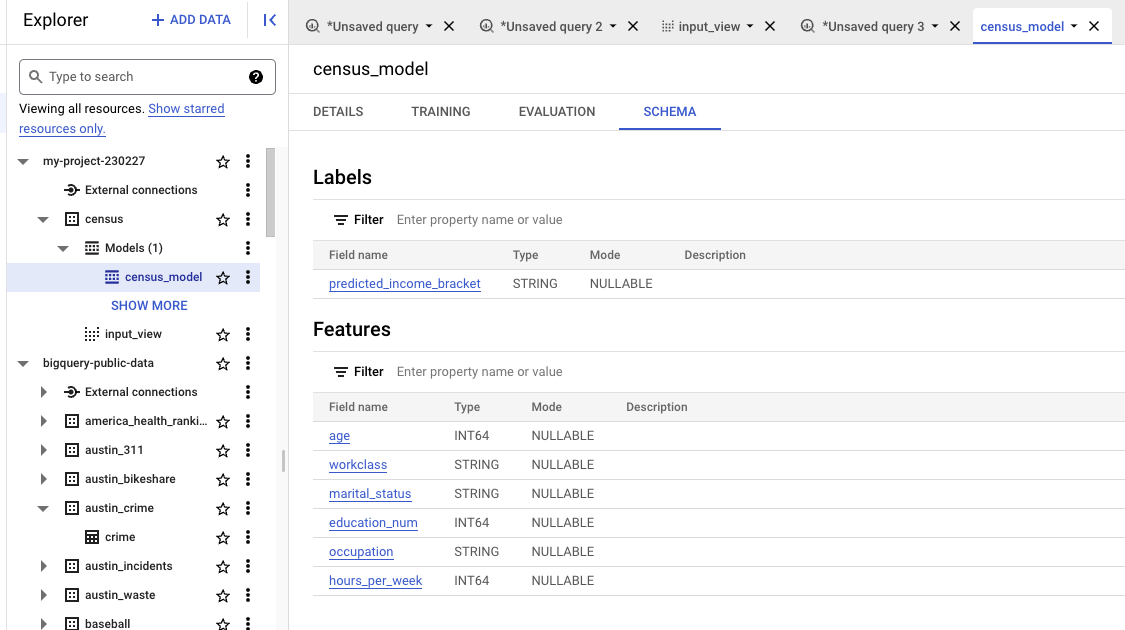
SCHEMA 탭은 BigQuery ML이 로지스틱 회귀를 수행하는데 사용한 속성을 나열한다.
5단계: ML.EVALUATE 함수를 사용하여 모델 평가
4단계의
CREATE MODEL문을 수행했을때 모델의 결과 창에EVALUATION탭으로 확인할 수 있다.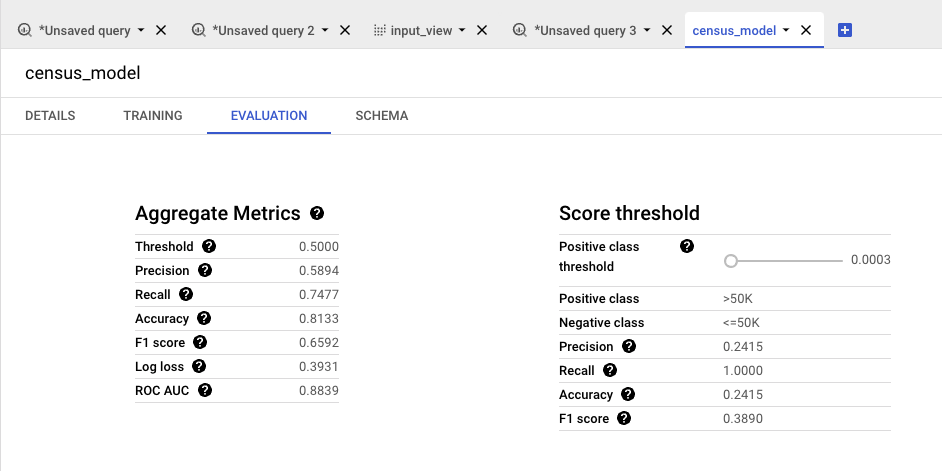
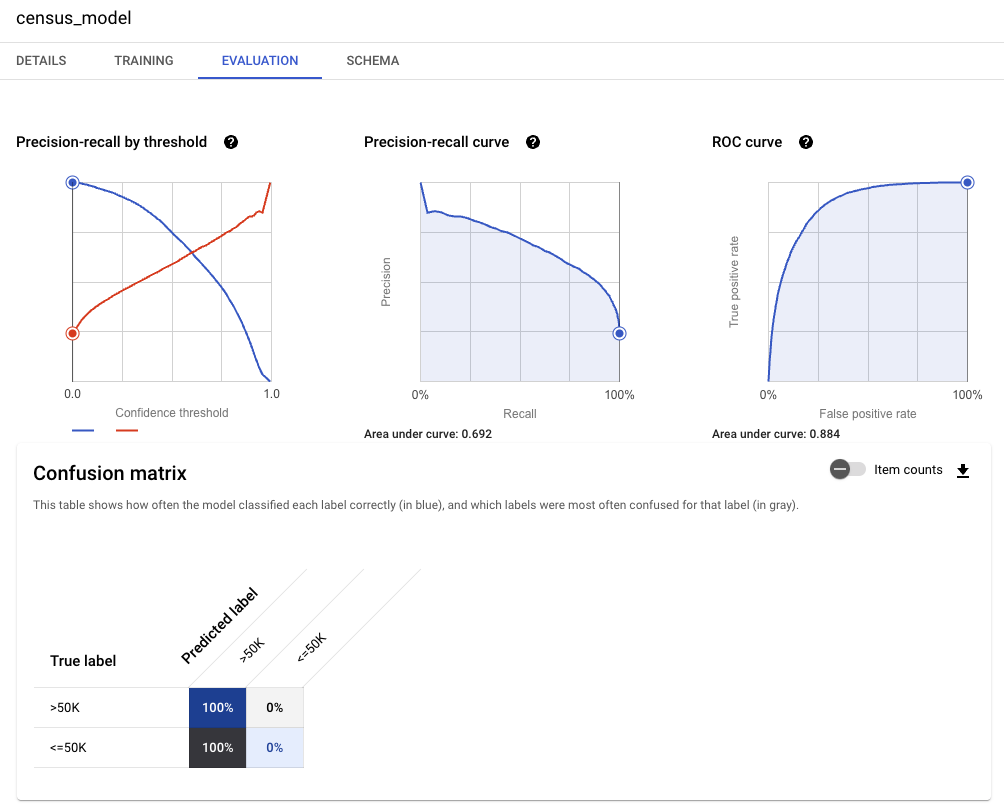
ML.EVALUATE 함수는 실제 데이터를 기준으로 예측 값을 평가한다.
1
2
3
4
5
6
7
8
9
10
11
12
13SELECT
*
FROM
ML.EVALUATE (MODEL `census.census_model`,
(
SELECT
*
FROM
`census.input_view`
WHERE
dataframe = 'evaluation'
)
)앞에서 학습시킨 모델과 SELECT 서브 쿼리에서 반환된 평가 데이터를 받아들인다.
이 함수는 모델에 대한 단일행의 통계를 반환한다.
input_view 의 데이터를 평가 데이터로 사용한다.
실행 결과

로지스틱 회귀를 수행했으므로 결과에
precision,recall,accuracy,f1_score,log_loss,roc_auc열이 포함된다.
1번과 2번의 차이
- ML.EVALUATE는 학습 과정에서 계산된 평가 측정값을 가져오는데, 이를 위해 자동으로 예약된 평가 데이터셋을 사용합니다.
- data_split_method 학습 옵션에 NO_SPLIT 가 지정된 1번 방법의 경우 전체 입력 데이터 세트가 학습과 평가에 모두 사용된다.
- 평가 데이터와 훈련 데이터를 구분하지 않고 ML.EVALUATE 를 호출 하면 학습 데이터 세트에서 임의의 평가 데이터 세트가 측정되고 이러한 평가 효과는 모델 학습 데이터와 별도로 유지된 데이터 세트에 대한 평가 실행보다 적다. → 따라서 구분해주는게 좋다.
6단계: ML.PREDICT 함수를 사용하여 소득 계층 예측
특정 응답자가 속한 소득 계층을 식별하려면
ML.PREDICT함수를 사용한다.1
2
3
4
5
6
7
8
9
10
11
12
13SELECT
*
FROM
ML.PREDICT (MODEL `census.census_model`,
(
SELECT
*
FROM
`census.input_view`
WHERE
dataframe = 'prediction'
)
)prediction데이터 프레임에 있는 모든 응답자의 소득 계층을 예측한다.
실행 결과:
predicted_income_bracket은income_bracket의 예측값
7단계: Explainable AI 메서드로 예측 결과 설명
모델에서 이러한 예측 결과를 생성하는 이유를 알아 보려면
ML.EXPLAIN_PREDICT함수를 사용하면 된다.ML.EXPLAIN_PREDICT는ML.PREDICT의 확장된 버전예측 결과 뿐만 아니라 예측결과를 설명하는 추가 열을 출력한다.
BigQueryML의 Shapley 값과 Explainable AI서비스에 대한 자세한 내용
1
2
3
4
5
6
7
8
9
10
11
12
13#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `census.census_model`,
(
SELECT
*
FROM
`census.input_view`
WHERE
dataframe = 'evaluation'),
STRUCT(3 as top_k_features))실행 결과
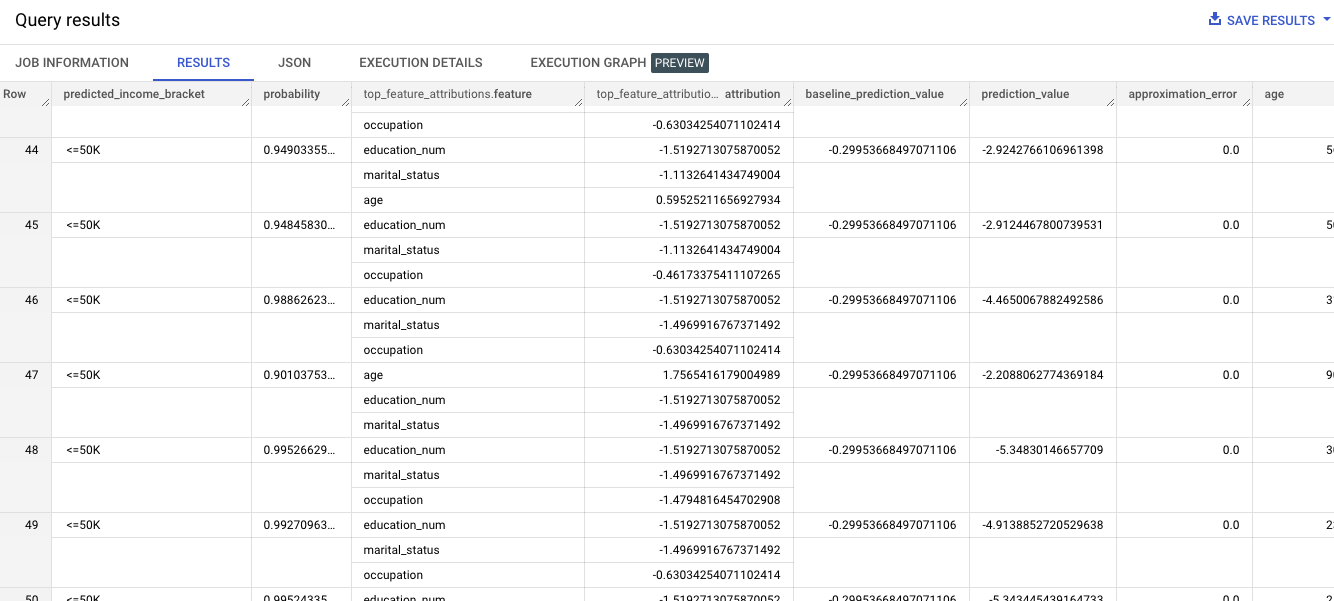
로지스틱 회귀모델에서 Shapley 값은 머신 러닝 모델의 예측 결과에 각 특성이 기여하는 정도를 평가하기 위해 사용된다. 이 값을 통해 모델의 예측 결과를 해석하고, 모델의 예측 결과를 개선하기 위해 어떤 특성을 수정해야 하는지를 결정하는 데 도움을 준다.
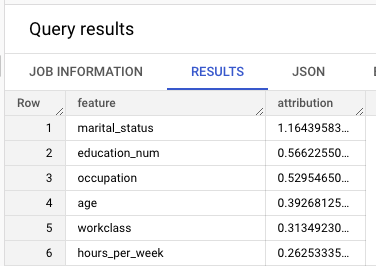
top_k_features가 3으로 설정되었기 때문에 제공된 테이블의 행당 특성 기여 학목 3개를 출력함.기여항목은 절댓값 기준으로 내림차순으로 정렬된다. 44번행의 결과 값은
education_num이 가장 큰 기여를 하였다면, 47번행의 결과는age가 가장 큰 기여를 했음을 알수 있다.
8단계: 모델을 전연적으로 설명
일반적으로 소득계층을 셜정하는데 가장 중요한 특성이 무엇인지 확인하려면
ML.GLOABL_EXPLAIN함수를 사용하면 된다.이를 사용하려면 모델을 학습 시킬때 ENABLE_GLOBAL_EXPLAIN = TRUE 옵션을 사용하여야 한다.
sklearn의 feature importance와 같은 기능을 하는 함수
학습 쿼리
1
2
3
4
5
6
7
8
9
10
11
12
13
14CREATE OR REPLACE MODEL
census.census_model
OPTIONS
( model_type='LOGISTIC_REG',
auto_class_weights=TRUE,
enable_global_explain=TRUE,
input_label_cols=['income_bracket']
) AS
SELECT
* EXCEPT(dataframe)
FROM
census.input_view
WHERE
dataframe = 'training'전역 설명에 Access하는 쿼리
1
2
3
4
5#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
실행 결과