Basic ML Process
- 이 포스트에서는 필자가 생각한 기본 프로세스를 소개 한다.
- 머신러닝을 접해보지 않은 사람들에게 대략적인 개념을 보여주는 포스트 이다.
- 자세한 내용은 추후 추가 예정
가설 수립 → 데이터 확인 및 전처리 → 모델 학습/ 모델 검증 → 예측하기 → 결과 확인
- 가설 수립(회귀/분류 여부 확인) → 잠재 고객 분류, 매출 예측, 리텐션 예측 등등..
- 잠재 고객 분류: 특정 고객군은 추후 유료 서비스를 사용할 것이다.
- 매출 예측: 다음달 매출 예상액은 전월 대비 ?? 일것이다.
- 리텐션 예측: 다음주 리텐션 비율이 ?? 일 것이다, ??일 동안 들어온 고객은 장기 고객이 될 것이다
- 예시 가설: 이틀 이상 접속 & 1 경기 이상 플레이 경험 유저 대상으로 귀환 유저 비율 예측 → 회귀문제
- 데이터 확인 및 전처리
데이터 feature 선택
- 예시 raw data(Big Query에서 추출한 부분)
A그룹은 2021-12-07 ~ 2021-12-21
B그룹은 2022-02-14 ~ 2022-02-28전체: 접속시간, 레벨, 게임횟수, 로그인횟수, 평균순위, 최대순위, 총킬횟수, 유저킬횟수, 헤드샷킬수, 신고 횟수, 솔로/듀오/스쿼드 참여 횟수, 오직 솔로모드만 이용
가입첫날: 총 게임수, 평균순위, 최대순위, 총킬횟수, 유저킬횟수, 헤드샷킬수, 신고 횟수, 솔로/듀오/스쿼드 참여 횟수, 오직 솔로모드만 이용
가입 다음날: 총 게임수, 평균순위, 최대순위, 총킬횟수, 유저킬횟수, 헤드샷킬수, 신고 횟수, 솔로/듀오/스쿼드 참여 횟수, 오직 솔로모드만 이용
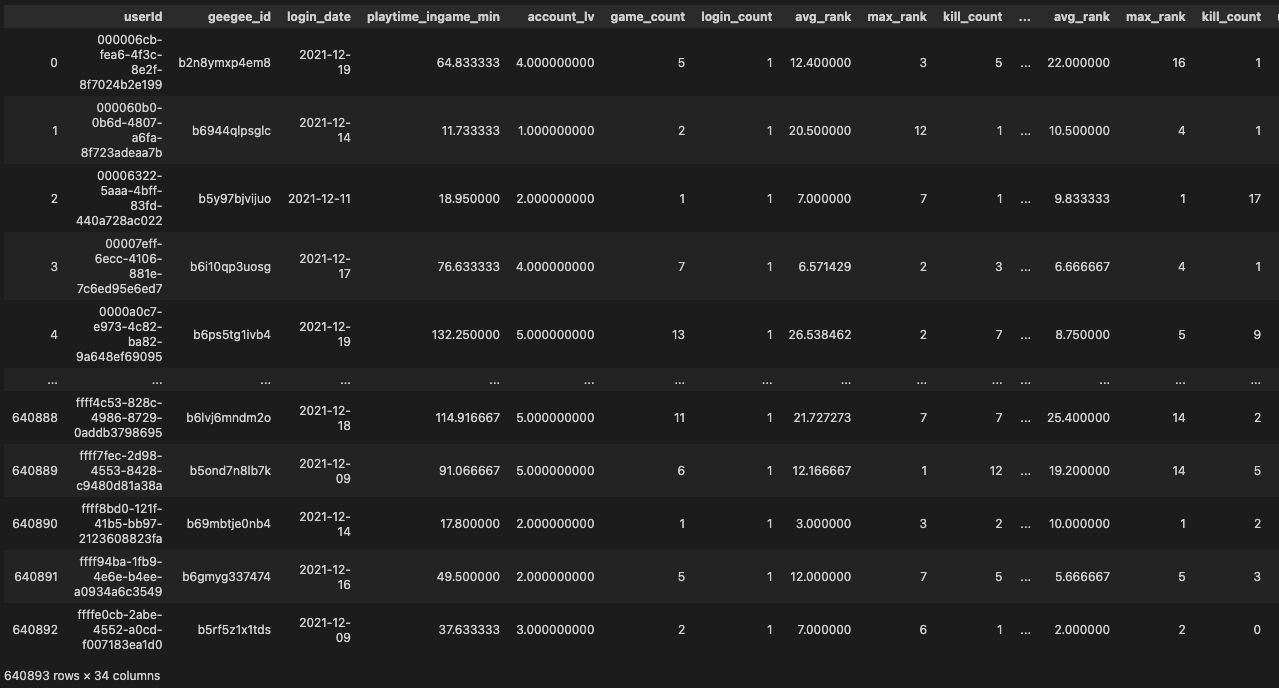
- 예시 raw data(Big Query에서 추출한 부분)
EDA
- 유저 킬수, 최대순위, 로그인횟수, 헤드샷킬수, 유저레벨, 플레이 시간, 로그아웃 날짜, 총 게임 횟수, 총 킬수, 평균 순위
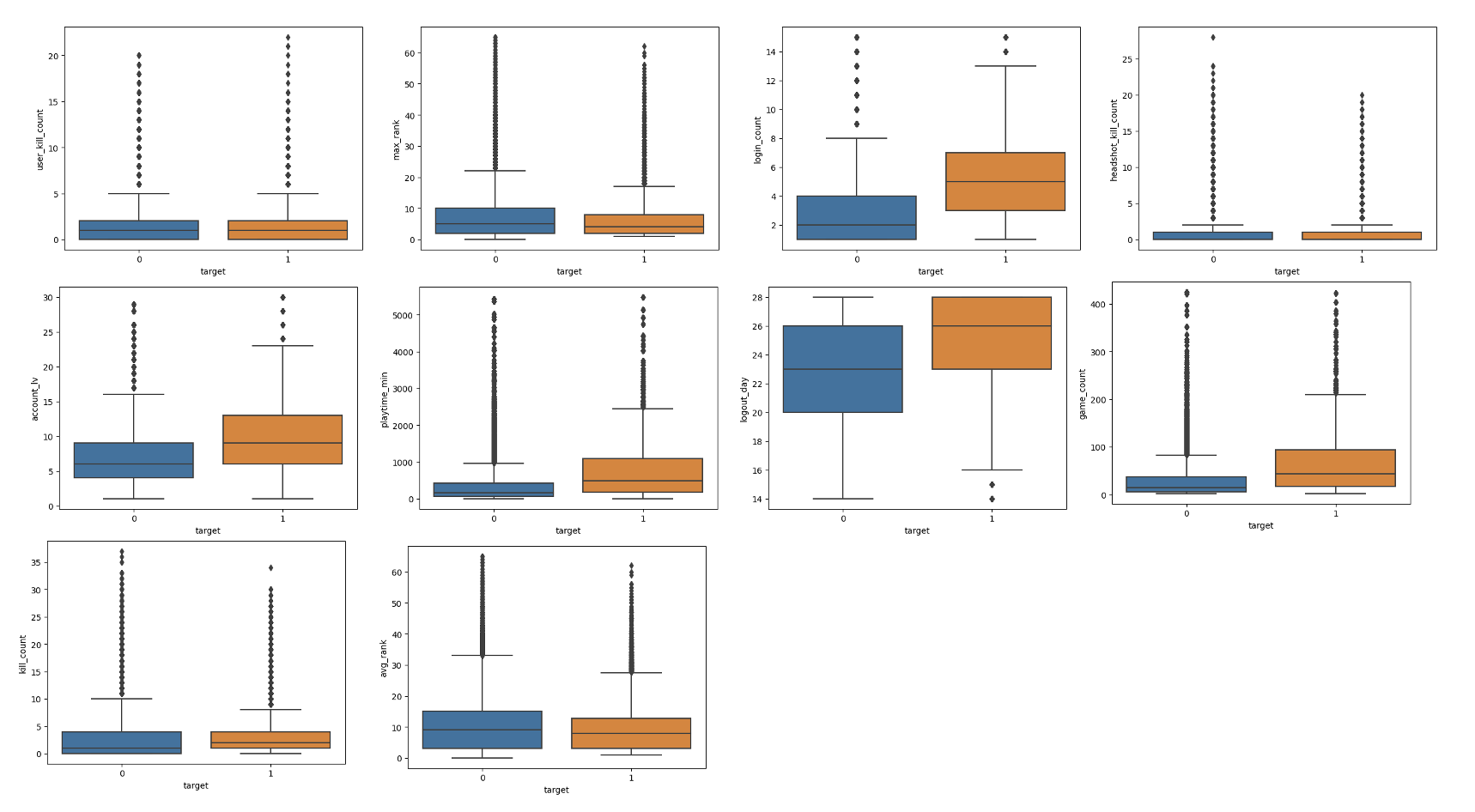
데이터 샘플링
- 데이터를 일부 정리해서 최적의 입력 데이터로 만드는 과정
- 확률적 샘플링
- 단순 랜덤 샘플링
- 2단계 샘플링: 전체 n개의 데이터를 m개의 모집단으로 나누고 m개의 모집단 중에 N개의 데이터를 단순랜덤 샘플링
- 층별 샘플링: 모집단을 여러개 층으로 구분함으로써 각 층에서 n개씩 랜덤하게 데이터 추출
- 군집/집락 샘플링: 모집단이 여러개의 군집으로 구성되어 있는 경우 군집 중 하나 or 여러개의 군집을 선정해서 선정된 군집의 전체 데이터를 사용하는 방법. Ex) 한국의 시,도 데이터
- 계통 샘플링: 1에서 n까지 모든 데이터에 번호를 매겨서 일정 간격마다 하나씩 데이터를 추출하는 방법. 대표적으로 시계열에서 사용됨
- 비확률적 샘플링
- 편의 샘플링: 데이터르르 수집하기 좋은 시점이나 위치를 선정하여 샘플링
- 판단 샘플링: 목적에 가장 적합한 대상이라고 생각하느느 대상을 선택
- 할당 샘플링
- 참고: https://jmj3047.github.io/2022/09/07/Data_Sampling/
feature 축소 or 확대
- ‘유저 킬수, 최대순위, 로그인횟수, 헤드샷킬수, 유저레벨, 플레이 시간, 로그아웃 날짜, 총 게임 횟수, 총 킬수, 평균 순위’ 의 지표를 EDA 과정을 거쳐 ‘접속시간, 레벨, 게임횟수, 로그인횟수, 평균순위, 최대순위, 총킬횟수, 유저킬횟수, 헤드샷킬수, 신고 횟수, 솔로/듀오/스쿼드 참여 횟수, 오직 솔로모드만 이용’ 으로 지표를 확대 시킴 → 약 64만행의 데이터 확보
- 모델 학습/ 모델 검증
모델 선택 및 파라미터 조정 → 모델 학습 → 모델 검증
대부분 한줄의 코드로 모델 선택이 가능함

파라미터 조정 같은 경우 GridSearchCV로 조정 할수 있음
n_estimators=500, learning_rate=0.05, gamma=0, subsample=0.75, → 이 네가지의 파라미터를 최적값으로 조정하고 싶다면, 각각의 범위를 선택해주면 범위 내의 모든 확률을 다 확인한다: 시간도 오래 걸리고 굉장히 무겁게 돌아감.
feature importance로 어떤 파라미터가 모델 학습에 기여를 많이 했는지 알수 있음
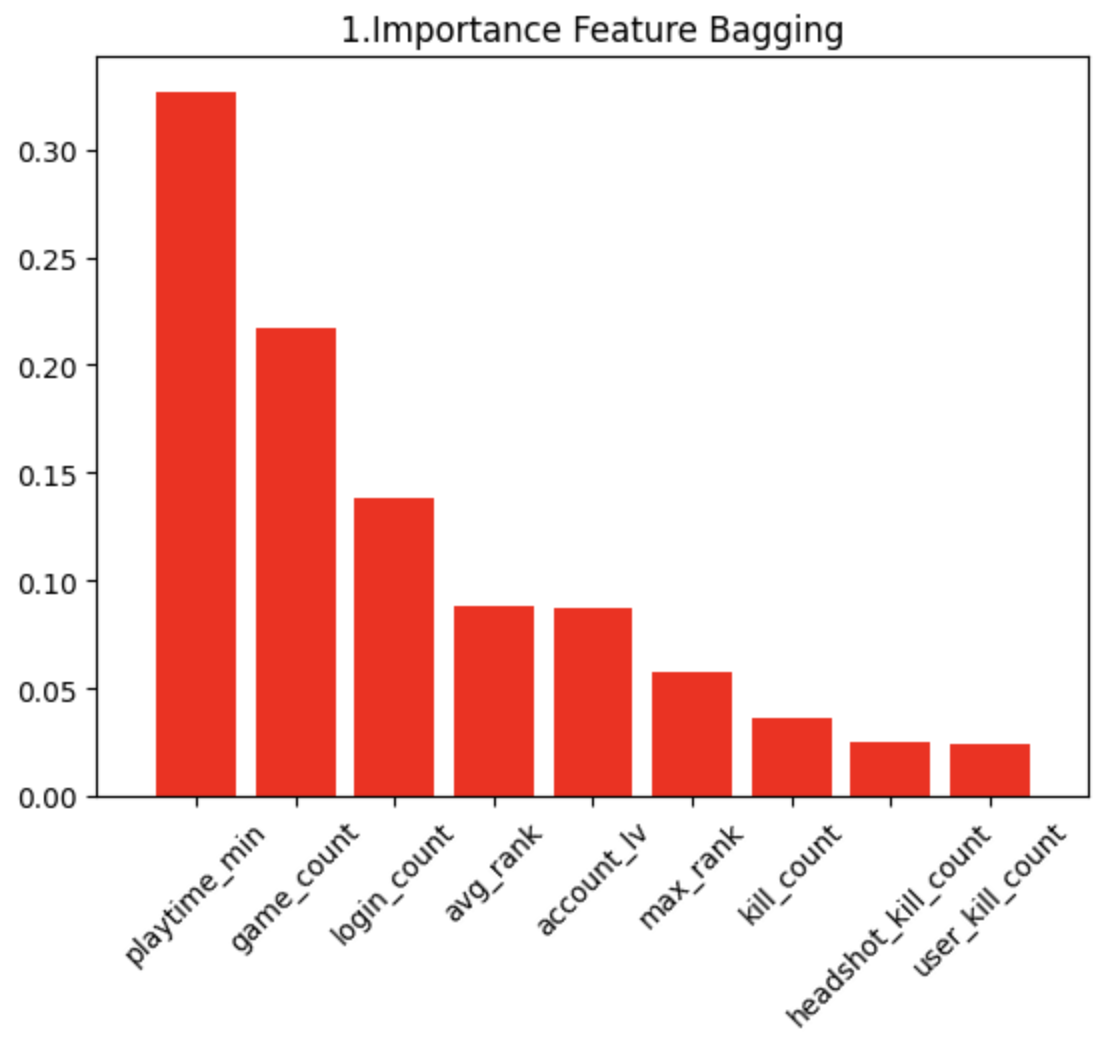
학습 시 train 데이터를 validation set을 떼어두고 학습 해야 모델 검증이 가능 함.
모델 검증 → 모델과 데이터 간의 적합도 확인 하는 과정
- f1 score, $r^2$ score, confusion matrix 등등
- 예측하기 및 결과 확인
- 모델 저장 후 test 데이터로 실행해봄
- 결과의 신뢰성이 어느정도 인지 확인하는 방법 → 미래의 사건이라서 100프로 확인은 안되지만 오류에 대한 부분을 확인하면 유추 가능