확률 분포 함수와 확률 밀도 함수
확률 분포 함수(probability distribution function)와 확률 밀도 함수(probability density function)는 확률 변수의 분포 즉, 확률 분포를 수학적으로 정의하기 위한 수식이다.
연속 확률 분포
우선 확률 밀도 함수에 대해 먼저 알아보자. 확률 밀도 함수를 이해하면 확률 분포 함수를 이해하는 것은 쉽다. 확률 밀도 함수는 연속 확률 변수(continuous random variable)를 정의하는데 필요하다. 연속 확률 변수의 값은 실수(real number) 집합처럼 연속적이고 무한개의 경우의 수를 가진다. 연속 확률 변수의 분포를 연속 확률 분포라고 한다.
시계 바늘을 예로 들어보자. 다음과 같은 아날로그 시계의 시계 바늘을 눈을 감고 임의로 돌렸다고 하면 시계 바늘이 정각 12시(각도 0도)를 가리킬 확률은 얼마일까?
만약 이 확률 변수의 확률 분포가 0 이상 360 미만의 구간내에서 균일 분포(uniform distribution) 모형을 가진다고 가정하면 답은 0(zero)이다.시계 바늘이 가리키는 각도의 값은 0도 이상 360도 미만의 모든 실수 값을 가질 수 있는데, 이 경우 수가 무한대이므로 각각의 경우에 대한 확률은 0이 되어야 하기 때문이다.사실 각도가 0도가 아니라 어떤 특정한 각도를 지정하더라도 같은 이유로 그 각도를 가리킬 확률은 0이다. 그럼 도대체 어떤 방법으로 확률 분포를 설명해야 할까?
이렇게 경우의 수가 무한대인 연속 확률 변수의 분포를 설명하려면 특정한 값이 아니라 구간을 지정하여 확률을 설명해야 한다. 예를 들어 위와 같은 시계바늘의 예에서는 다음과 같은 분포의 묘사가 가능하다.
- 시계 바늘이 12시와 1시 사이에 있을 확률은 1/12
- 시계 바늘이 1시와 3시 사이에 있을 확률은 2/12 = 1/6
- 시계 바늘이 6시와 9시 사이에 있을 확률은 3/12 = 1/4
이 방법의 단점 중 하나는 분포를 설명하는데 범위를 지정하는 두 개의 숫자가 필요하다는 점이다. 예를 들어 ‘1시와 3시 사이’ 라는 범위를 지정하는데는 1과 3이라는 숫자가 필요하다.그럼 하나의 숫자로 확률 변수의 범위를 지정하는 방법은 없을까? 가능한 방법 중의 하나는 범위를 지정하는 두 개의 숫자 중 작은 숫자 즉, 범위가 시작하는 숫자를 미리 가장 작은 숫자로 고정하는 방법이다. 이 방법을 쓰면 다음과 같이 하나의 숫자로 랜덤 변수의 범위와 해당 확률을 서술할 수 있다.
- 숫자=1 -> 범위=12시부터 1시까지 -> 확률 1/12
- 숫자=2 -> 범위=12시부터 2시까지 -> 확률 2/12
- 숫자=5 -> 범위=12시부터 5시까지 -> 확률 5/12
누적 확률 분포
위와 같은 방법으로 서술된 확률 분포를 누적 확률 밀도 함수 (cumulative probability density function) 또는 누적 확률 분포라고 하고 약자로 cdf라고 쓴다. 일반적으로 cdf는 대문자를 사용하여 F(x)와 같은 기호로 표시하며 이 때 독립 변수 x는 범위의 끝을 뜻한다. 범위의 시작은 일반적으로 음의 무한대(negative infinity, -∞)값을 사용한다.몇가지 누적 확률 분포 표시의 예를 들면 다음과 같다.
- F(-1) : 확률 변수가 -∞ 이상 -1 미만인 구간 내에 존재할 확률
- F(10) : 확률 변수가 -∞ 이상 10 미만인 구간 내에 존재할 확률
확률 변수 X에 대한 누적 확률 분포 F(x)의 수학적 정의는 다음과 같다.
$$
F(x) = P(X < x) = P(X<x)
$$
일례로 표준 정규 분포의 누적 확률을 그리면 아래와 같다.
1 | x = np.linspace(-4,4) |
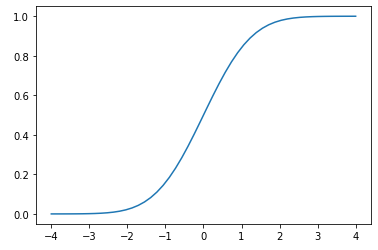
누적 밀도 함수 즉, cdf는 다음과 같은 특징을 가진다.
- F(-∞) = 0
- F(∞) = 1
- F(x) ≥ F(y) if x > y
확률 밀도 함수
누적 밀도 함수의 단점 중의 하나는 어떤 값이 더 자주 나오든가 혹은 더 가능성이 높은지에 대한 정보를 알기 힘들다는 점이다. 이를 알기 위해서는 확률 변수가 나올 수 있는 전체 구간 (-∞ ~ ∞)을 아주 작은 폭을 가지는 구간들로 나눈 다음 각 구간의 확률을 살펴보는 것이 편리하다. 다만 이렇게 되면 구간의 폭을 얼마로 정해야 하는지에 대한 의문이 생긴다.
1 | x = np.linspace(-4,4,20) |
1 | w = (4-(-4))/20 |
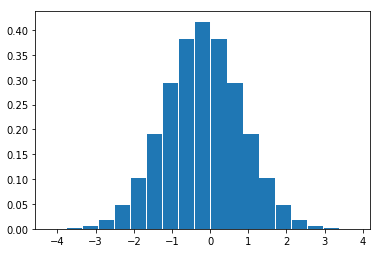
이 때 사용할 수 있는 수학적 방법이 바로 미분(differentiation)이다. 미분은 함수의 구간을 무한대 갯수로 쪼개어 각 구간 변화의 정도 즉, 기울기를 계산하는 방법이다.
누적 밀도 함수를 미분하여 나온 도함수(derivative)를 확률 밀도 함수(probability density function)라고 한다. 누적 밀도 함수는 보통 f(x)와 같이 소문자 함수 기호를 사용하여 표기한다.
$$
f(x)=\frac{dF(x)}{dx} \text 또는 F(x) = \int_{-\infty}^{x}f(u)du
$$
확률 밀도 함수는 다음과 같은 특징을 가진다.
- -∞ 부터 ∞까지 적분하면 그 값은 1이 된다.