Journal/Conference : Neurocomputing
Year(published year): 2020
Author: Liyang Chen, Yifeng Liu , Wendong Xiao, Yingxue Wang, Haiyong Xie
Subject: Speaker GAN, Generative Adversarial Network
SpeakerGAN: Speaker identification with conditional generative adversarial network
Summary
- This paper proposes a novel approach, SpeakerGAN, for speaker identification with the conditional generative adversarial network (CGAN).
- We configure the generator and the discriminator in SpeakerGAN with the gated convolutional neural network (CNN) and the modified residual network (ResNet) to obtain generated samples of high diversity as well as increase the network capacity.
- Under the scenario of limited training data, SpeakerGAN obtains significant improvement over the baselines.
Introduction
The x-vector in [13,14] is proposed as a strong contender for the speaker representation and is considered to supplant the i-vector system by many researchers.
We evaluate our approach on the dataset of Librispeech-100 for the text-independent SI task. The baselines include i-vector, xvector, CNN and LSTM.
Generative Adversarial Networks
Conditional GAN
The CGAN is a variant of GAN, which aims to let the generator $G$ produce $G(c,z)$ from the condition $c$ and random noise $z$.
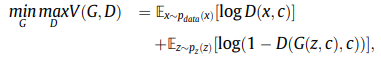
In this paper, the real samples x are directly utilized as the condition c and the random noise z is abandoned for showing no effectiveness in the experiments.
SpeakerGAN for speaker identification
Basic principle of SpeakerGAN
We investigate the CGAN as a classifier by enabling the network to learn on additional unlabeled examples.
The SpeakerGAN combines the discriminator and classifier by letting the classifier take samples from the generator as inputs and have $N+1$ output units, where $l_{N+1}$corresponds to the probability $P_{model}(y=N+1|x)$ that the inputs are real.
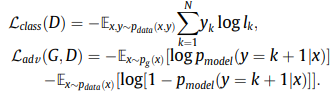
To stabilize the training and overcome the problem of vanishing gradients, the least square GAN (LSGAN) [40] is adopted. $L_{adv}$ is then split into the losses for the discriminator and generator.
Network architecture of SpeakerGAN
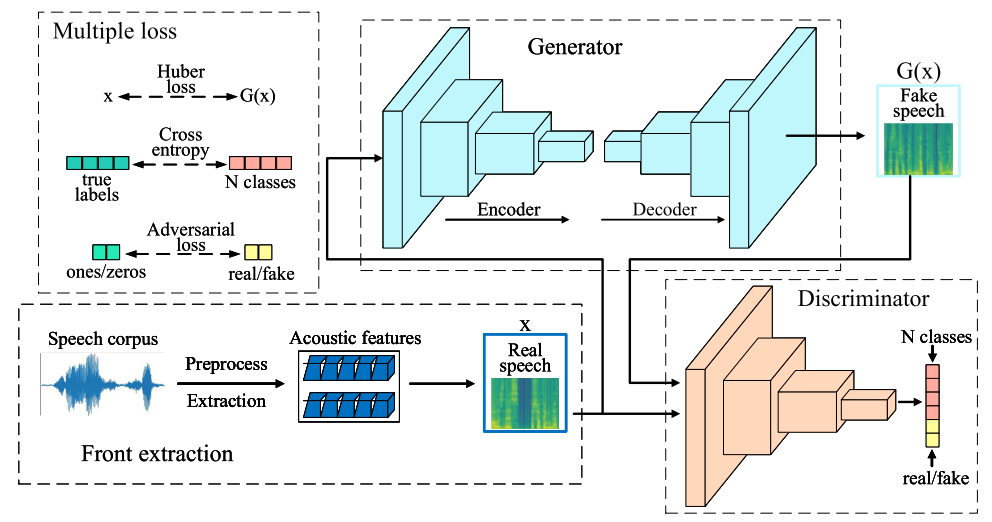
Fig. 1. Framework of SpeakerGAN. The front extraction part extracts FBanks $x$ from the real speech samples. The generator takes the real FBanks x as inputs and produces fake samples $G(x)$. The discriminator is then fed with the real and generated FBanks to predict class labels and distinguish between the real and fake samples. The adversarial loss in Multiple loss actually denotes the formulation of LSGAN [40]. The dashed lines with arrows denote calculating loss between two objects, and the solid lines denote the flow of information.
The generator takes real sequences as the condition for inputs, and produces the fake samples of the same size after passing through a series of convolutional and shuffler layers that progressively downsample and upsample. The discriminator takes the generated samples and real acoustic features from the corpus as inputs, and outputs the discrimination of real/fake along with the $N$ classes.
Generator design
These generators only capture relationships among feature dimension and the generated samples are in lack of consistency. An effective way to solve this problem would be to introduce the RNN, but it is timeconsuming due to the difficulty of parallel computing. For these reasons, we configure the generator using gated CNNs [43], which allow for both sequential structure and faster convergence. This idea was previously explored in [25], and achieved competitive performance.
Discriminator design
As for the discriminator, we prefer deeper networks to classify speakers. However, training deep neural networks is computationally expensive and difficult. This paper modifies the ResNet [45] to
accelerate the training. ResNets have been applied in many SI systems [16,17] and are known for good classification performance on image data.
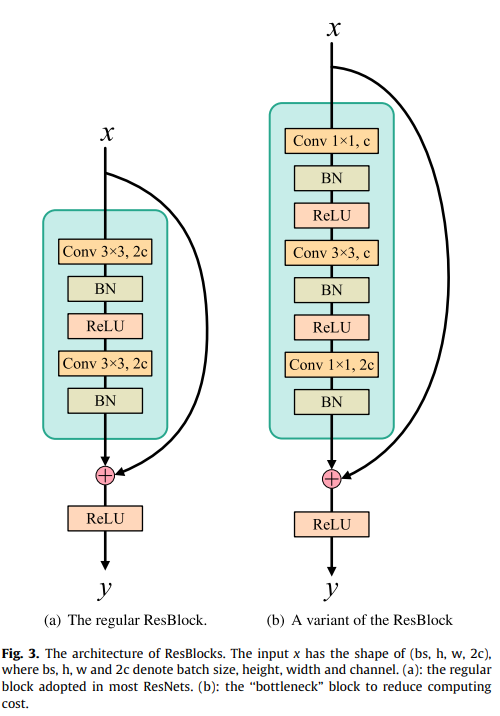
To reduce parameters and improve calculation efficiency, the variant ResBlock is adopted, which comprises a stack of three convolutional layers.
Four ResBlocks are stacked and a softmax classifier is used to predict the speaker identity in the final layer.
Experiments
Dataset and basic setup
To evaluate the performance of the proposed approach, we conduct experiments on the Librispeech [46] dataset.
We use the train-clean-100 subset in it that contains 251 speakers of 125 females and 126
males. Each speaker is provided with an average of 113 utterances lasting 1–15 s.
The same acoustic features are used for the baselines of CNN, LSTM and GAN classifier.
Speech samples are shuffled before training. Sixty percentage of all utterances are randomly selected as training data and the rest are used as test data.
Conclustions and future work
It directly utilizes the discriminator as a classifier using the fake samples produced by the generator as the additional class. The Hybrid loss function includes the adversarial loss of the regular GAN, the
cross-entropy loss of the labeled data and the Huber loss between the real samples and generation.
Experimental results demonstrate that SpeakerGAN can achieve higher identification accuracy than other state-of-the-art DL based methods and the traditional i-vector and x-vector systems.