Journal/Conference : ICASSP IEEE
Year(published year): 2020
Author: Siddharth Sigtia, Pascal Clark, Rob Haynes, Hywel Richards, John Bridle
Subject: Multi-Task Learning
Summary
- We start by training a general acoustic model that produces phonetic transcriptions given a large labelled training dataset.
- 우리는 레이블이 지정된 대규모 훈련 데이터 세트가 주어지면 phonetic transcriptions를 생성하는 일반적인 음향 모델을 훈련하는 것으로 시작한다.
- Next, we collect a much smaller dataset of examples that are challenging for the baseline system.
- 다음으로, 우리는 기준 시스템에 도전하는 훨씬 더 작은 예제의 데이터 세트를 수집한다.
- We then use multi-task learning to train a model to simultaneously produce accurate phonetic transcriptions on the larger dataset and discriminate between true and easily confusable examples using the smaller dataset.
- 그런 다음 다중 작업 학습을 사용하여 모델을 훈련시켜 더 큰 데이터 세트에서 정확한 phonetic transcriptions를 생성하고 더 작은 데이터 세트를 사용하여 실제 예제와 쉽게 혼동할 수 있는 예제를 구별한다.
Introduction
Significant challenge is that unlike automatic speech recognition (ASR) systems, collecting training examples for a specific keyword or phrase in a variety of conditions is a difficult problem.
중요한 과제는 자동 음성 인식(ASR) 시스템과 달리 다양한 조건에서 특정 키워드 또는 구문에 대한 훈련 예제를 수집하는 것은 어려운 문제라는 것이다.
In the literature, the problem of detecting a speech trigger phrase is interchangeably referred to as voice trigger detection [3], keyword spotting [4], wake-up word detection [5] or hotword detection [6]. In the rest of this paper, we refer to this problem as voice trigger detection.
문헌에서 음성 트리거 구문을 검출하는 문제는 voice trigger detection [3], keyword spotting [4], wake-up word detection [5] 또는 hotword detection [6]으로 상호 교환적으로 언급된다.
이 논문의 나머지 부분에서는 이 문제를 voice trigger detection라고 합니다.
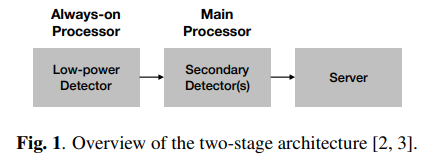
In the multi-stage approach (Figure 1), the first stage comprises a low-power DNN-HMM system that is always on [3].
그림1에 보면, 첫 번째 단계는 항상 [3]에 있는 저전력 DNN-HMM 시스템을 포함한다.
In this design, it is the second stage that determines the final accuracy of the system and the models used in this stage are the subject of this paper.
이 설계에서 시스템의 최종 정확도를 결정하는 것은 두 번째 단계이며, 이 단계에서 사용되는 모델이 이 논문의 주제이다.
Our main contribution is to propose a multi-task learning strategy where a single model is trained to optimise 2 objectives simultaneously.
우리의 주요 기여는 단일 모델이 두 가지 목표를 동시에 최적화하도록 훈련되는 다중 작업 학습 전략을 제안하는 것이다.
The first objective is to assign the highest score to the correct sequence of phonetic labels given a speech recording.
첫 번째 목표는 주어진 음성 녹음의 음성 레이블이 올바른 순서로 되어 있다면 가장 높은 점수를 할당하는 것이다.
This objective is optimised on a large labelled training dataset which is also used for training the main speech recogniser and is therefore easy to obtain.
이 목표는 주요 음성 인식기를 훈련시키는 데 사용되므로 쉽게 얻을 수 있는 대규모 레이블링된 훈련 데이터 세트에 최적화된다.
The second objective is to discriminate between utterances that contain the trigger phrase and those that are phonetically similar and easily confusable.
두 번째 목표는 trigger phrase를 포함하는 발화와 음성학적으로 유사하고 쉽게 혼동되는 발화를 구별하는 것이다.
Baseline
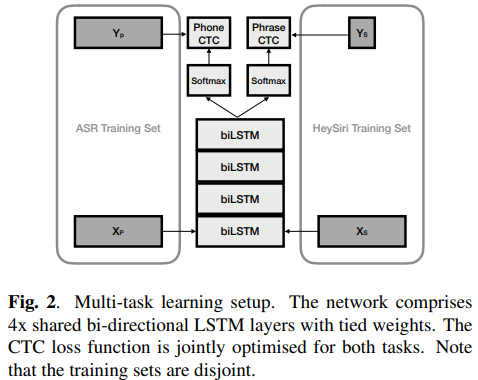
The baseline model architecture comprises an acoustic model (AM) with four bidirectional LSTM layers with 256 units each, followed by an output affine transformation + softmax layer over context independent (CI) phonemes, word and sentence boundaries, resulting in 53 output symbols (Figure 2).
Firstly, the fact that the second-pass model is used for re-scoring and not in a continuous streaming setting allows us to use bidirectional LSTM layers.
첫째, 2차 통과 모델이 연속 스트리밍 설정이 아닌 재 득점에 사용된다는 사실은 양방향 LSTM 레이어를 사용할 수 있게 합니다.
Secondly, using context-independent phones as targets allows us to share training data with the main ASR.
둘째, context-independent phones 를 target으로 사용하면 주요 ASR과 training 데이터를 공유할수 있습니다.
This is particularly important since in many cases it is not possible to obtain a large number of training utterances with the trigger phrase, for example when developing a trigger detector for a new language.
이는 특히 중요하다. 많은 경우에 가령 새로운 언어로 트리거 감지를 개발할때 training 발화를 trigger phrase로 다량의 데이터를 얻는것이 불가능하기 때문이다.
Furthermore, having CI phones as targets results in a flexible model that can be used for detecting any keyword.
더 나아가서 유연한 모델에서 CI 음소들을 타겟 결과로 갖는 것은 어느 키워드를 감지하는데 사용될수 있다.
Given an audio segment x from the first pass, we are interested in calculating the probability of the phone sequence in the trigger phrase, $P(TriggerPhrasePhoneSeq|x)$.
segment x 음성이 1차에서 주어졌을때, 우리는 trigger phrase의 음성 시퀀스, $P(TriggerPhrasePhoneSeq|x)$,의 확률을 계산하는 것에 관심이 있다.
Multi-Task Learning
The question we really want to answer is, “given an audio segment from the first pass, does it contain the trigger phrase or not?”
우리가 실제로 답하고 싶은 질문은 “1차에서 통과된 주어진 음성 segment가 trigger phrase를 포함하고 있는가 아닌가?” 이다.
We would like the second-pass model to be a binary classifier which determines the presence or absence of the trigger phrase.
우리는 2차 모델이 trigger phrase를 포함하는지 하지 않는지를 결정하는 이진 분류기였으면 한다.
However the issue with this design is that collecting a large number of training examples that result in false detections by the baseline system is a difficult problem (c.f. Section 4).
그러나, 이 디자인의 이슈는 baseline 시스템에 의해 다량의 training 예시를 수집하는 것이 어려운 문제라는 것이다.
Furthermore, the second pass models have millions of parameters, so they can easily overfit a small training set resulting in poor generalisation.
더 나아가 2차 모델은 수백만개의 파라미터가 있다. 그래서 그들은 작은 training set에도 쉽게 과적합 되며 안좋은 일반화를 결과로 낸다.
Therefore, we are faced with the choice between a more general phonetic AM that can be trained on a large, readily available dataset but is optimised for the wrong criterion or a trigger phrase specific detector that is trained on the correct criterion but with a significantly smaller training dataset.
따라서, 우리는 크고 손쉽게 사용 가능한 데이터셋으로 train된 하지만 잘못된 기준으로 최적화된 일반화된 음성 AM과 올바른 기준으로 train됐지만 매우 적은 training 데이터로 학습된 특정 trigger phrase 감지기, 둘 중 하나를 선택해야 했다.
One solution to this problem is to use multi-task learning (MTL) [19]
우리의 해결책은 multi-task learning을 사용하는 것이었다.
Note that predicting the sequence of phonetic labels in an utterance and deciding whether an utterance contains a specific trigger phrase or not, are related tasks.
발화 속에서 phonetic label의 시퀀스를 예측하는 것 그리고 발화가 trigger phrase를 포함하고 있는지 아닌지 결정하는 것은 서로 연관성이 있는 일이다.
We train a single network with a stack of shared/tied biLSTM layers with two seperate output layers (one for each task) and train the network jointly on both sets of training data (Figure 2).
우리는 두개의 출력 레이어(각각 하나의 task씩)를 갖고 있고 공유하는/묶인 biLSTM 레이어들의 묶음으로 이루어진 하나의 네트워크를 훈련했고 두 세트의 training data(Figure 2)에 합동으로 엮인 네트워크를 훈련했다.
We hypothesise that the joint network is able to learn useful features from both tasks: a) the network can be trained to predict phone labels on a large labelled dataset of general speech which covers a wide distribution of complex acoustic conditions, b) the same network can also learn to discriminate between examples of true triggers and confusable examples on a relatively smaller dataset.
우리는 합동 네트워크가 두 task의 유용한 feature들을 학습이 가능하다고 가정했다: a) 네트워크는 복잡한 음향 조건의 광범위한 분포를 다루는 일반적인 음성의 큰 labelled된 데이터 셋을 기반으로 phone label들을 예측하게끔 훈련될수 있다. b) 같은 네트워크는 또한 상대적으로 적은 데이터 양으로 실제의 trigger phrase와 헷갈리는 예시들을 구분하는 법을 배울수 있다.
An alternative view of this process is that the phonetic transcription task with a significantly larger training set acts as a regulariser for the trigger phrase discrimination task with a much smaller dataset.
이 process에 대한 다른 시각은 엄청나게 많은 training set를 사용하는 phonetic transcription task가 regulariser로 훨씬 적은 데이터를 가지고 trigger pharse를 구분할때 사용된다.
The objective function for the phrase specific/discriminative output layer is defined as follows: the softmax output layer contains two output units, one for the trigger phrase and the other one for the blank symbol used by the CTC loss function [8, 16]
phrase를 특정화/차별화 하는 output layer의 목적함수는 다음과 같이 정의된다: softmax output layer은 두개의 output unit을 포함하는데 하나는 trigger phrase를 위함이고 또 다른 하나는 CTC loss function에서 사용되는 blanck symbol을 위함이다.
Evaluation
There were 100 subjects, approximately balanced between male and female adults. Distances from the device were controlled, ranging from 8 to 15 feet away.
대략적으로 반반의 성비로 100명의 참가자들이 참여했다. 기기와의 거리도 8-15피트 정도로 통제되었다.
There are over 13K utterances overall, evenly divided between four acoustic conditions: (a) quiet room, (b) external noise from a TV or kitchen appliance in the room, (c) music playback from the recording device at medium volume, and (d) music playback from the recording device at loud volume.
전반적으로 만 3천개의 발화들이 있는데 네가지 컨디션으로 동일하게 나누어졌다: (a) 조용한 방, (b) 방의 TV 또는 주방기기의 외부 소음. (c) 중간 볼륨의 녹음 장치에서 음악 재생, (d) 큰 볼륨의 녹음 장치에서 음악 재생
These examples are used to measure the proportion of false rejections (FRs).
이 예시들은 FR 비율을 측정하기 위해 사용되었다.
In addition to these recordings, this test set also consists of almost 2,000 hours of continuous audio recordings from TV, radio, and podcasts. This allows the measurement of the false-alarm (FA) rate in terms of FAs per hour of active external audio.
그 녹음들에 관해 덧붙이자면, 이 test set 또한 TV, 라디오, 팟캐스트로부터 2천 시간의 연속적인 음성 녹음을 포함하고 있다. 이를 통해 active한 외부 음성의 시간당 FA, FA비율을 측정할 수 있다.
The second test set is an unstructured data collection at home by our employees, designed to be more representative of realistic, spontaneous usage of the smart speaker.
두번째 test set은 사원들의 집에서 나는 정제되지 않은 데이터 모음이다. 이는 조금더 현실적이고 즉흥적인 스마트폰 스피커의 사용을 대표한다.
With this data, it is possible to measure nearly unbiased false-reject and false-alarm rates for realistic in-home scenarios similar to customer usage.
이 데이터로 현실적인 집 내부의 시나리오들(소비자의 사용과 비슷한)을 위한 편향되지 않은 FA와 FA 비율 측정이 가능하다.
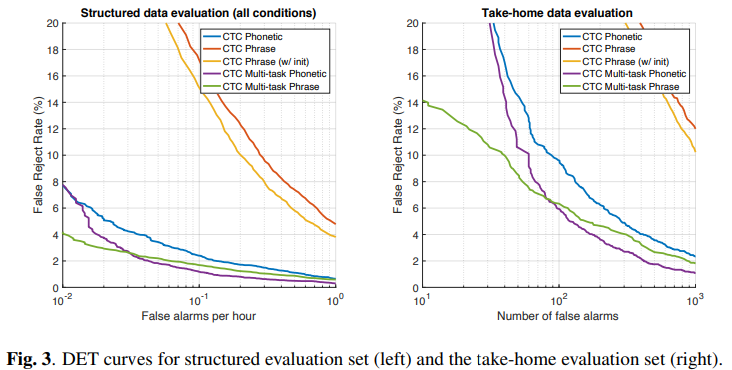
We use detection error trade-off (DET) curves to compare the accuracy between models. Each curve displays the FA rate and the proportion of FRs associated with sweeping the trigger threshold for a
particular model.
우리는 DET 곡선을 두 모델의 정확성을 비교하기 위해 사용한다. 각 곡선은 특정 모델에 대한 트리거 임계값을 스윕하는 것과 연관된 FA 비율 및 FR 비율을 표시한다.
In practice, we compare the shapes of the DET curves for different models in the vicinity of viable operating points.
실제로 우리는 실행가능한 작동지점 근처에서 서로 다른 모델들의 DET 곡선의 모양을 비교했다.
We compare five models: the baseline phonetic CTC model trained on the ASR dataset (blue), the baseline phrase specific model trained on the much smaller training set with randomly initialised weights (red), the same phrase specific model but with weights initialised with the learned weights from the baseline phonetic CTC model (yellow), the phonetic (purple) and phrase specific (green) branches of the proposed MTL model.
우리는 다섯개의 모델을 비교했다
- 파랑: ASR 데이터로 훈련한 baseline phonetic CTC 모델
- 빨강: 무작위로 초기화된 가중치를 갖는 훨씬 더 작은 training 세트 상에서 훈련된 baseline phrase 특정 모델
- 노랑: 동일한 phrase의 특정 모델이지만 기본 음성 CTC 모델의 학습된 가중치를 초기화된 가중치를 갖는 모델
- 보라: 제안된 MTL모델 중 phonetic branches
- 초록: 제안된 MTL 모델 중 phrase specific 모델
Note that the phrase specific model with weight initialisation from the baseline phonetic model (yellow) is effectively trained using both datasets.
baseline phonetic model의 초기화된 가중치를 가지는 phrase specific 모델은 효과적으로 두 dataset을 사용하면서 훈련되었다.
In both test sets, the MTL phonetic (purple) and phrase-specific (green) models outperform the baseline phonetic CTC (blue), reducing the FR rate by almost half at many points along the curve.
양쪽 test set에서 보라색 그리고 초록색 모델을은 파란색보다 FR비율을 다른 곡선에 비해 반절이나 감소시키면서 결과가 좋았다.
The non-MTL phrase specific models (red and yellow) yield significantly worse accuracies in comparison, which is unsurprising given that the training dataset is two orders of magnitude smaller compared to the phonetic baseline (blue).
MTL을 사용하지 않은 specific 모델(빨강, 노랑) 부분은 심각하게 안좋은 정확성을 상대적으로 보였으며 이것은 training dataset이 phonetic baseline(파랑)에 비해 두자릿수 더 작다는 점을 감안했을때 당연하다.
Comparing the structured data evaluation (left) and the take-home data evaluation (right), it is also striking how the error rates are generally much higher for the latter.
구조화된 데이터 evaluation(왼쪽)과 take-home data evaluation(오른쪽)을 비교해보면 일반적으로 후자의 경우 오류율이 더 높은것도 눈에 띈다.
Conclusions
We trained the model to simultaneously produce phonetic transcriptions on a large ASR dataset and to discriminate between difficult examples on a much smaller trigger phrase specific training set.
우리는 큰 ASR dataset에서 phonetic transcription을 제공하고 동시에 훨씬 더 작은 trigger phrase training set에서 어려운 샘플들을 구별하는 모델을 훈련했다.
We evaluate the proposed model on two challenging test sets and find the proposed method is able to almost halve errors and does not require any extra model parameters.
우리는 제안된 모델의 두 test set을 평가했고 제안된 방법이 오류를 반감하기 위해 더 많은 파라미터를 필요로 하지 않은다는 것을 발견했다.