Journal/Conference : ICASSP IEEE
Year(published year): 2020
Author: Siddharth Sigtia, Erik Marchi, Sachin Kajarekar, Devang Naik, John Bridle
Subject: Multi-Task Learning
Multi-Task Learning for Speaker Verification and Voice Trigger Detection
Summary
- In this study, we investigate training a single network to perform automatic speech transcription and speaker recognition, both tasks jointly.
- 본 연구에서는 단일 네트워크를 훈련하여 automatic speech transcription와 speaker recognition의 두 가지 작업을 공동으로 수행하는 방법을 연구합니다.
- We train the network in a supervised multi-task learning setup, where the speech transcription branch of the network is trained to minimise a phonetic connectionist temporal classification (CTC) loss while the speaker recognition branch of the network is trained to label the input sequence with the correct label for the speaker.
- 우리는 네트워크의 speech transcription 브랜치가 음성 CTC 손실을 최소화하도록 훈련되는 감독 된 멀티 태스킹 학습 설정에서 네트워크를 훈련시키는 반면, 네트워크의 화자 인식 브랜치는 입력 시퀀스를 화자에 대한 올바른 라벨로 라벨링하도록 훈련된다.
- Results demonstrate that the network is able to encode both phonetic and speaker information in its learnt representations while yielding accuracies at least as good as the baseline models for each task, with the same number of parameters as the independent models.
- 결과는 네트워크가 학습된 표현에서 음성 및 화자 정보를 모두 인코딩할 수 있으며 독립 모델과 동일한 수의 매개 변수를 사용하여 각 작업의 기본 모델만큼 정확도를 산출할 수 있음을 보여줍니다.
Introduction
Voice trigger detection, which is interchangeably known as keyword spotting [4], wake-up word detection [5], or hotword detection [6], is treated as an acoustic modeling problem.
keyword spotting [4], wake-up word detection [5] 또는 hotword detection [6]로 상호 교환 가능하게 알려진 음성 트리거 검출은 음향 모델링 문제에 속한다
Their primary aim is to recognise the phonetic content (or the trigger phrase directly) in the input audio, with no regard for the identity of the speaker.
그들의 주된 목표는 화자의 신원을 고려하지 않고 입력 오디오의 음성 내용(또는 트리거 문구)을 인식하는 것이다.
On the other hand, speaker verification systems aim to confirm the identity of the speaker by comparing an input utterance with a set of enrolment utterances which are collected when a user sets up their device.
한편, 스피커 검증 시스템은 사용자가 장치를 설정할 때 수집되는 등록 발화 집합과 입력 발화를 비교하여 화자의 신원을 확인하는 것을 목표로 한다.
Speaker verification algorithms can be characterised based on whether the phonetic content in the inputs is limited, which is known as text-dependent speaker verification [9].
화자 검증 알고리즘은 입력의 음성 콘텐츠가 제한되어 있는지 여부에 따라 특성화할 수 있는데, 이를 text-dependent speaker verification[9]이라고 한다.
We believe that knowledge of the speaker would help determine the phonetic content in the acoustic signal and vice versa, therefore estimating both properties is similar to solving simultaneous equations.
우리는 화자에 대한 지식이 음향 신호의 음성 내용을 결정하는 데 도움이 되고 그 반대의 경우도 마찬가지라고 생각합니다. 따라서 두 속성을 모두 추정하는 것은 연립 방정식을 푸는 것과 유사합니다.
In this study, the main research question we try to answer is “can a single network efficiently represent both phonetic and speaker specific information?”.
이 연구에서 우리가 대답하려고하는 주요 연구 질문은 “하나의 네트워크가 음성 및 화자 특정 정보를 효율적으로 표현할 수 있습니까?”입니다.
From a practical standpoint, being able to share computation between the two tasks can save on-device memory, computation time or latency and the amount of power/battery consumed.
실용적인 관점에서 두 작업간에 계산을 공유할 수 있으면 장치 메모리, 계산 시간 또는 대기 시간 및 소비되는 전력 / 배터리 양을 절약할 수 있습니다.
More generally, we are interested in studying whether a single model can perform multiple speech understanding tasks rather than designing a separate model for each task.
보다 일반적으로, 우리는 각 작업에 대해 별도의 모델을 설계하기보다는 단일 모델이 여러 개의 음성 이해 작업을 수행할 수 있는지 연구하는 데 관심이 있습니다.
We train a joint network to perform a phonetic labelling task and a speaker recognition task.
우리는 음성 라벨링 작업과 화자 인식 작업을 수행하기 위해 공동 네트워크를 훈련시켰습니다.
We evaluate the 2 branches of the model on a voice trigger detection task and a speaker verification task, respectively.
우리는 음성 트리거 검출 작업과 화자 검증 작업에서 모델의 두 가지를 각각 평가합니다.
It is possible for a single network to encode both speaker and phonetic information and yield similar accuracies as the baseline models without requiring any additional parameters.
단일 네트워크가 스피커 및 음성 정보를 모두 인코딩하고 추가 매개 변수를 필요로하지 않고 기준 모델과 유사한 정확도를 산출할 수 있습니다.
Voice Trigger Detection Baseline
We extract 40-dimensional log-filterbanks from the audio at 100 frame-per-second (FPS). At every step, 7 frames are spliced together to form symmetric windows and finally this sequence of windows is sub-sampled by a factor of 3, yielding a 280-dimensional input vector to the model at a rate of 33 FPS.
The features are input to a stack of 4 bidirectional LSTM layers with 256 units in each layer (Figure 1). This is followed by a fully connected layer and an output softmax layer over context-independent phonemes and additional sentence and word boundary symbols, resulting in a total of 53 output symbols and 6 million model parameters. This model is then trained by minimising the CTC loss function [16].
The training data for this model is 5000 hours of anonymised audio data that is manually transcribed, where all of the recordings are sampled from intentional voice assistant invocations and are assumed to be near-field.
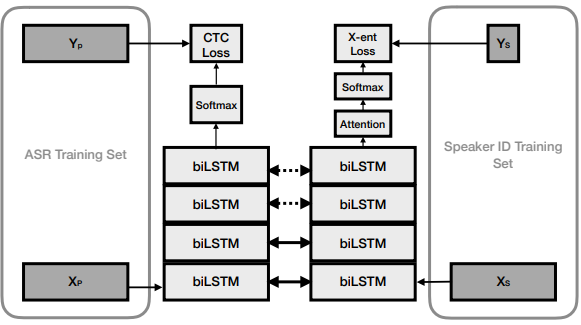
Fig. 1. The left branch of the model represents the voice trigger detector, the right branch is the speaker verification model. Solid horizontal arrows represent layers with tied weights, dashed arrows represent layers with weights that may or may not be tied.
모델의 왼쪽 분기는 음성 트리거 검출기를 나타내고, 오른쪽 분기는 화자 검증 모델이다. 실선 화살표는 묶인 가중치가 있는 레이어를 나타내고 점선 화살표는 묶일 수도 있고 묶이지 않을 수도 있는 가중치가 있는 레이어를 나타냅니다.
Speaker Verification Baseline
We use a simple location-based attention mechanism [18] to summarise the encoder activations as a fixed-dimensional vector.
우리는 인코더 활성화를 고정 차원 벡터로 요약하기 위해 간단한 위치 기반주의 메커니즘 [18]을 사용합니다.
We found the attention mechanism to be particularly effective in the text-independent setting.
우리는 attention 메커니즘이 텍스트 독립적인 환경에서 특히 효과적이라는 것을 발견했다.
During inference, given a test utterance x, the speaker embedding is obtained by removing the final softmax layer and using the 128-dimensional activations of the previous layer.
추론 중에 테스트 발화 x가 주어지면 스피커 삽입은 최종 소프트 맥스 레이어를 제거하고 이전 레이어의 128 차원 활성화를 사용하여 얻어집니다.
Each training utterance is of the form “Trigger phrase, payload” for e.g.“Hey Siri (HS), play me something I’d like”. For every training example, we generate 3 segments: the trigger phrase, the payload and the whole utterance. We found that breaking the utterances up this way results in models that generalise significantly better.
Evaluation
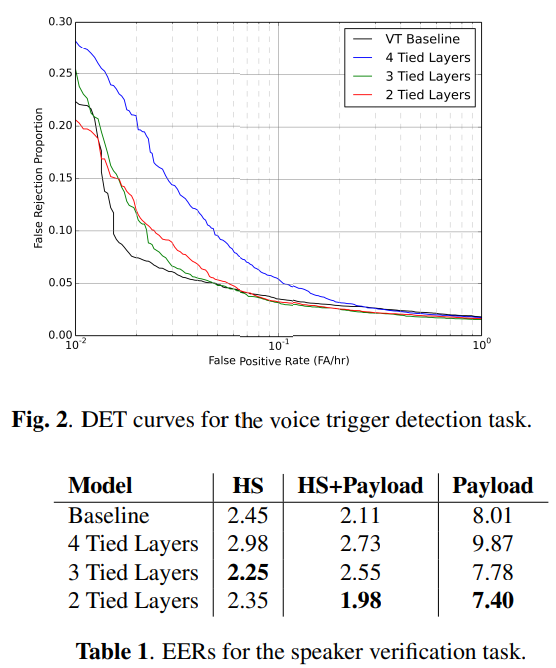
Conclustions
Our results demonstrate that sharing the first two layers of the model between the speaker and phonetic tasks gives accuracies that are as good as the individual baselines.
우리의 결과는 화자와 음성 작업 사이에 모델의 처음 두 레이어를 공유하면 개별 기준선만큼 정확도가 높다는 것을 보여줍니다.
This result indicates that it is possible to share some of the lowlevel computation between speech processing tasks without hurting accuracies.
이 결과는 정확도를 해치지 않으면 서 음성 처리 작업간에 저수준 계산의 일부를 공유할 수 있음을 나타냅니다.