1. 쿼리 실행순서
FROM → WHERE → GROUP BY, Aggregation → HAVING → WINDOW → QUALIFY → DISTINCT → ORDER BY → LIMIT
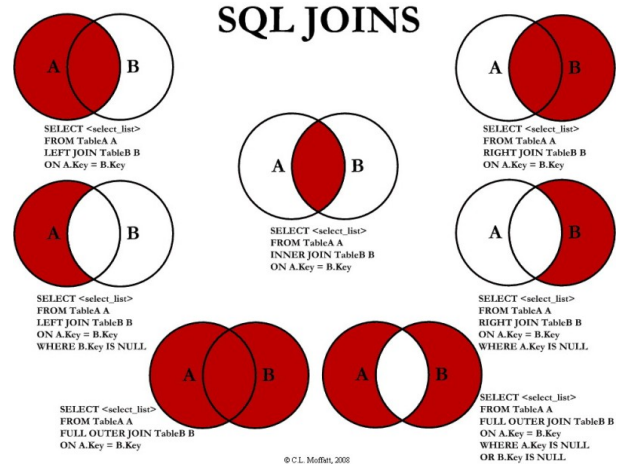
2. JOIN
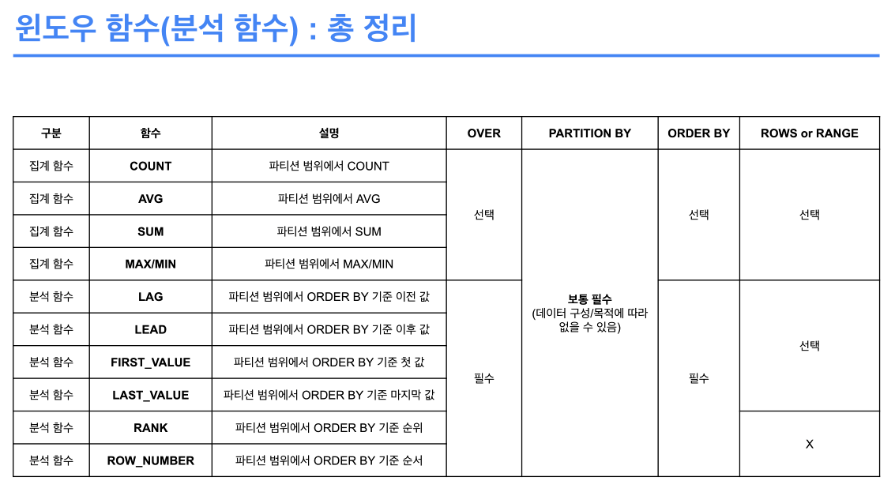
3. WINDOW 함수
4. DECLARE
변수를 선언 혹은 초기화할 때 사용
DECLARE variable_name[, ...] [variable_type] [ DEFAULT expression];1
2
3
4
5
6
7-- 아래 쿼리를 실행하면 값이 모두 1로 나오는걸 확인 할 수 있음
-- DEFAULT를 안주면 NULL로 지정 됨
DECLARE x, y, z INT64 DEFAULT 1;
SELECT x,y,z
-- 현재 날짜로 d할당
DECLARE d DATE DEFAULT CURRENT_DATE();위 예시 말고 쿼리의 결과를 사용해 변수를 초기화 할 수도 있음
5. SET
- DECLARE와 같이 사용 되어짐.
- DECLARE에서 변수 타입을 지정하고 SET으로 값 할당이 가능,
- DECLARE에서 두 과정 모두 할 수 있지만 SET은 쿼리 내 어느 위치에서나 사용 가능 함
6. UDF - User Define Function
영구 UDF는 여러 쿼리에서 재사용 할 수 있음
CREATE TEMP FUNCTION→ 임시 UDF 생성CREATE FUNCTION→ 영구 UDF 생성CREATE OR REPLACE FUNCTION→ 영구 UDF 생성 및 수정1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16CREATE OR REPLACE FUNCTION ps-datateam.cbt_global_ceo.함수명(변수명 변수타입)
RETURNS INT64 --리턴 타입
LANGUAGE js -- 작성 언어(임시는 SQL로도 가능한 듯)
AS """
if (mode == 'solo') {
return 1;
} else if (mode == 'duo') {
return 2;
} else if (mode == 'trio'){
return 3;
} else if (mode == 'squad'){
return 4;
} else {
return 0;
}
"""; -- 함수
7. 파이썬에서 빅쿼리 데이터 사용
1 | from google.cloud import bigquery |