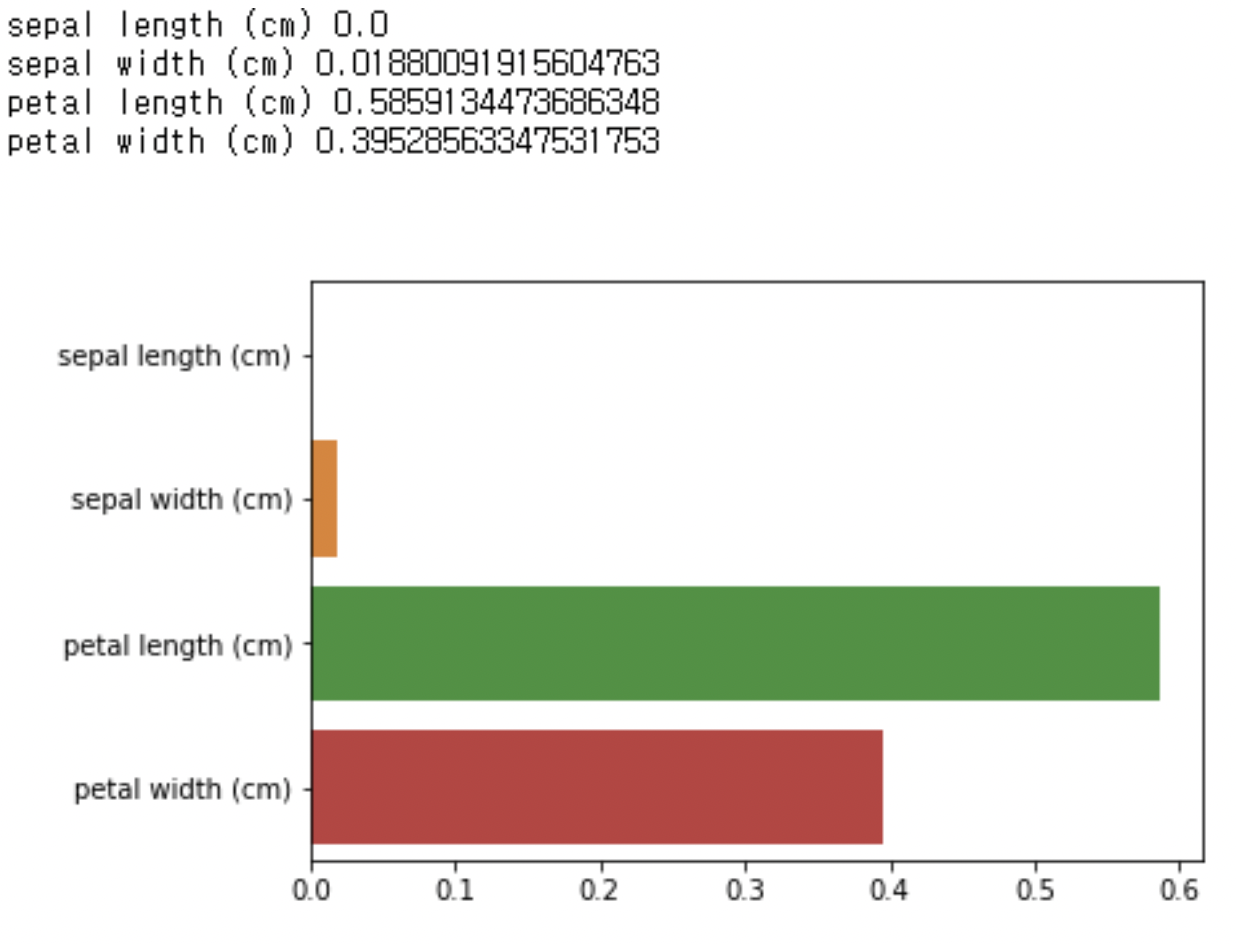
1. 의사결정트리
- 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 알고리즘입니다.
- 조금 더 쉽게 하자면 if else를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘입니다.
- 하지만 Decision Tree에서 많은 규칙이 있다는 것은 분류 방식이 복잡해진다는 것이고이는 과적합(Overfitting)으로 이어지기 쉽습니다.
- 트리의 깊이(depth)가 깊어질수록 결정트리는 과적합되기 쉬워 예측 성능이 저하될 수 있습니다.
- 가능한 적은 규칙노드로 높은 성능을 가지려면 데이터 분류를 할 때 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 규칙 노드의 규칙이 정해져야 합니다.
- 이를 위해 최대한 균일한 데이터 세트가 구성되도록 분할(Split)하는 것이 필요합니다.(분할된 데이터가 특정 속성을 잘 나타내야 한다는 것입니다.)
- 규칙 노드는 정보균일도가 높은 데이터 세트로 쪼개지도록 조건을 찾아 서브 데이터 세트를 만들고, 이 서브 데이터에서 이런 작업을 반복하며 최종 클래스를 예측하게 됩니다.
- 사이킷런에서는 기본적으로 지니계수를 이용하여 데이터를 분할합니다.
지니계수 : 경제학에서 불평등지수를 나타낼 때 사용하는 것으로 0일 때 완전 평등, 1일 때 완전 불평등을 의미합니다.
- 머신러닝에서는 데이터가 다양한 값을 가질수록 평등하며 특정 값으로 쏠릴 때 불평등한 값이 됩니다.
- 즉, 다양성이 낮을수록 균일도가 높다는 의미로 1로 갈수록 균일도가 높아 지니계수가 높은 속성을 기준으로 분할된다.
2. 파라미터
정보 균일도 측정 방법
- 정보 이득 방식: 엔트로피는 데이터의 혼잡도를 의미한다. 엔트로피가 놓다는 것은 혼잡도가 높다는 것
- 지니계수: 불평등지수/ 이 값이 0이면 평등하다는 것을(분류가 잘됐다) 뜻한다. 이 값이 리프노드가 된다
min_samples_split
- 노드를 분할하기 위한 최소한의 샘플 데이터수 → 과적합을 제어하는데 사용
- Default = 2 → 작게 설정할 수록 분할 노드가 많아져 과적합 가능성 증가
min_samples_leaf
- 리프노드가 되기 위해 필요한 최소한의 샘플 데이터수
- min_samples_split과 함께 과적합 제어 용도
- 불균형 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 작게 설정 필요
max_features
- 주요 파라미터
- 최적의 분할을 위해 고려할 최대 feature 개수
- Default = None → 데이터 세트의 모든 피처를 사용
- int형으로 지정 →피처 갯수 / float형으로 지정 →비중
- sqrt 또는 auto : 전체 피처 중 √(피처개수) 만큼 선정
- log : 전체 피처 중 log2(전체 피처 개수) 만큼 선정
max_depth
- 트리의 최대 깊이
- default = None → 완벽하게 클래스 값이 결정될 때 까지 분할 또는 데이터 개수가 min_samples_split보다 작아질 때까지 분할
- 깊이가 깊어지면 과적합될 수 있으므로 적절히 제어 필요
max_leaf_nodes
- 리프노드의 최대 개수
random_state
- 주로 검색해서 나오는 소스코드에 random_state = 42 라고 되어있어서 엄청난 의미를 가진 것 같지만 사실 42라는 random_state에 할당된 숫자 자체에 큰 의미는 없습니다.
- 중요한건 이 random_state를 None으로 두냐 정수를 넣느냐더라구요.
- random_status가 None인 경우 한번 Decision tree를 생성할 때 1,3,47,5…번 데이터를 이용했다고 해서 다시 이 Decision tree를 생성할 때 1,3,47…번째 데이터를 이용하지는 않습니다. 또 다른 어떤 난수번째의 데이터를 이용하게 되는거죠.
- 만약 random_state가 None이면 정말 규칙없는 어떤 데이터를 뽑아서 Decision tree를 생성하게 되지만 random_state에 어떤 값이 있다면 난수 생성에 어떠한 규칙(이건 만든사람 말고는 알 수 없음)을 넣어서 동일한 결과가 나오게 합니다.
- 예를 들어 1이라는 값을 넣어서 1,3,47,5…번째 데이터를 이용했다면 또다시 1을 넣으면 1,3,47,5…번째 데이터를 사용하게 되는거죠.
- 이걸 일반적으로는 random seed라고 합니다.
random seed
- 일반적으로 시스템이 난수를 만들 때 말이 난수지 일정한 패턴의 수를 생성합니다.
- 여기서 인자로 random seed라는걸 넣어서 어떠한 규칙을 만들어주는건데 C에서는 기본적으로 random seed가 정해져있어서 일반적으로 시간을 random seed로 쓰는 반면 파이썬에서는 기본적으로 이 random seed가 없는 경우 완전 랜덤이 되더라구요.
- 그래서 이 Random Seed라는건 불규칙속에 규칙을 만들어주는 매개변수라고 생각해주시면 됩니다.
random_state를 사용하는 이유
- 만약 Random_state를 None으로 두는 경우 Decisiontreeclassifier 함수를 이용해 Decision tree를 생성하면 그때그때 다른 데이터를 이용하기 때문에 결과가 바뀝니다.
- 그러나 Random_state에 변수를 입력할 경우 특정한 규칙을 갖게 되고 A라는 사람이 random_state=1로 Decision tree를 생성할 때와 B라는 사람이 random_state=1로 Decision tree를 생성할 때의 결과가 동일해지도록 하는거죠.
- 그러니까 random_state가 0인지 1인지 42인지보다는 같은 변수를 이용해 같은 결과를 도출해내는 데에 큰 의미가 있습니다.
3. 장,단점
장점
- 쉽고 직관적입니다.
- 각 피처의 스케일링과 정규화 같은 전처리 작업의 영향도가 크지 않습니다.
단점
- 규칙을 추가하며 서브트리를 만들어 나갈수록 모델이 복잡해지고, 과적합에 빠지기 쉽습니다 → 트리의 크기를 사전에 제한하는 튜닝이 필요합니다.
4. 쿼리 구현
1 | from sklearn.tree import DecisionTreeClassifier |
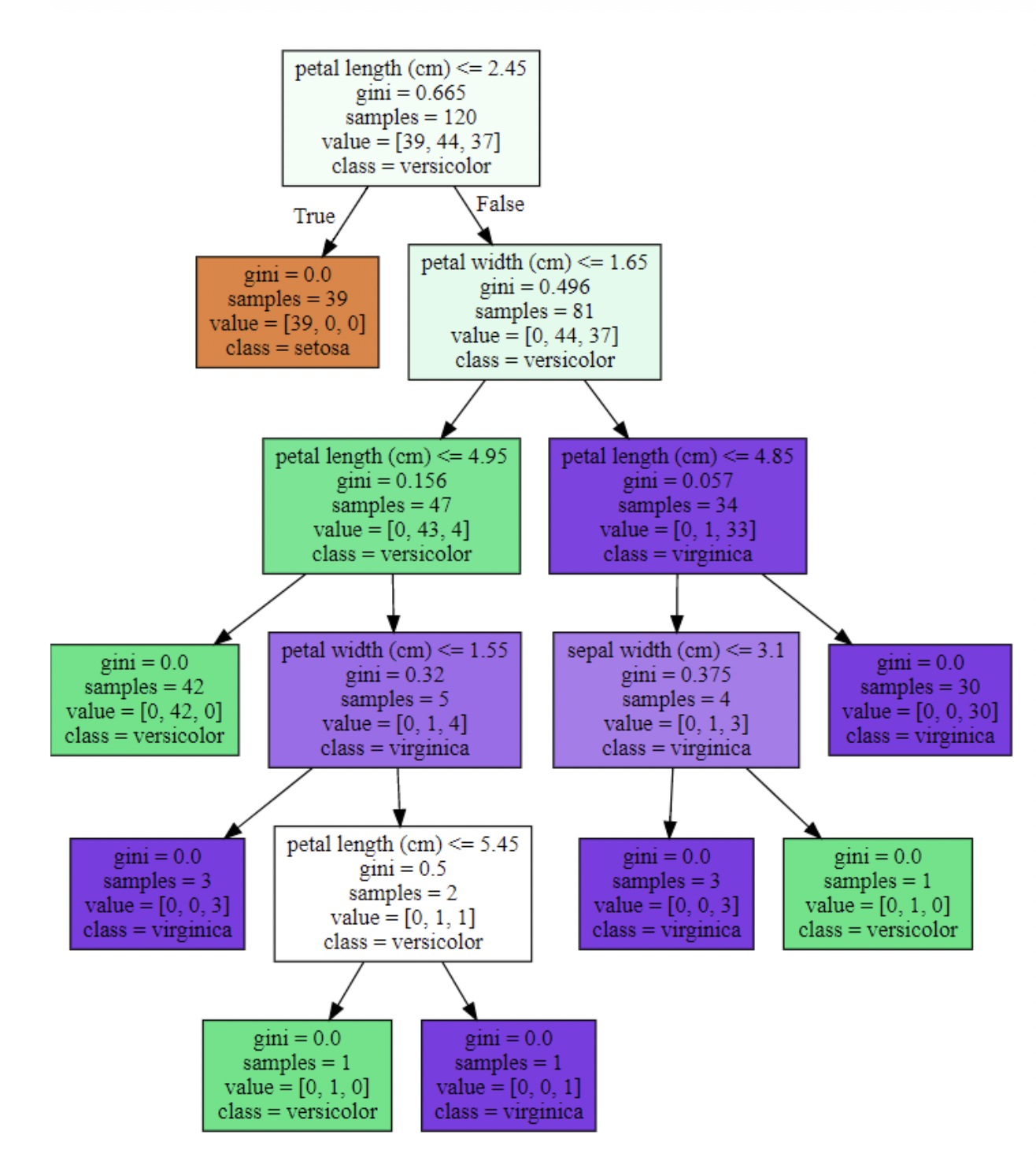
1 | import seaborn as sns |