Journal/Conference: Interspeech
Year(published year): 2020
Author: Peng Zhang, Peng Hu, Xueliang Zhang
Subject: Speaker Verification
Deep Embedding Learning for Text-Dependent Speaker Verification
Summary
이 논문은 화자 검증 작업을 위한 효과적인 딥 임베딩 학습 아키텍처를 제시한다.
널리 사용되는 잔류 신경망(ResNet) 및 시간 지연 신경망(TDNN) 기반 아키텍처와 비교하여, 두 가지 주요 개선이 제안된다.
우리는 화자의 단기 컨텍스트 정보를 인코딩하기 위해 조밀하게 연결된 컨볼루션 네트워크(DenseNet)를 사용한다.
양방향 주의 풀링 전략이 제안된다. 장기적인 시간적 맥락을 모델링하고 화자 정체성을 반영하는 중요한 프레임을 집계한다.
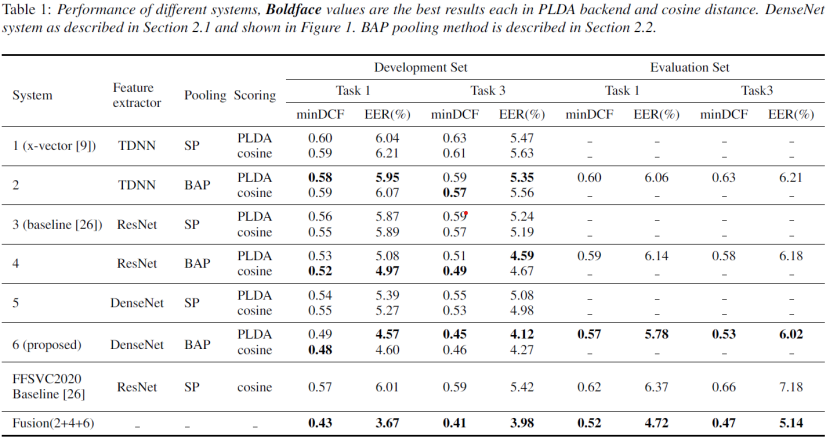
결과는 제안된 알고리듬이 과제 1과 과제 3의 평가 세트에서 각각 8.06%, 19.70% minDCF 및 9.26%, 16.16% EERs 상대적 감소로 FFSVC2020의 공식 기준선을 능가한다는 것을 보여준다.
Introduction
딥 러닝 기반 방법은 화자 간 차별에 필수적인 정보를 포함하는 딥 스피커 임베딩 또는 짧게 임베딩과 같은 발화 수준 표현을 얻기 위해 지배적이었다.
본 논문에서는 화자 검증을 위한 효과적인 딥 임베딩 학습 아키텍처를 제안한다. 최근 조밀하게 연결된 컨볼루션 네트워크의 성공에 자극받아
(DenseNet) 이미지 분류 [15], 음악 소스 분리 [16], 화자 분리 [17] 및 화자인식 [18]에서, 우리는 DenseNet을 프레임 레벨 피처 추출기로 채택하여 후속 레이어의 입력의 변화와 훈련 효율성을 증가시킨다.
개념적으로 각 밀도 블록은 작은 CNN 시스템 역할을 한다. 차이점은 레이어의 출력이 채널 차원의 출력 연결에 의해 구현되는 피드 포워드 방식으로 조밀하게 연결된다는 것이다.
또한, 우리는 발화 수준 기능의 표현력을 향상시키기 위해 시간 컨텍스트를 추가로 모델링하기 위한 양방향 주의 풀링 계층을 설계한다.
Model Architecture
DenseNet(프레임 레벨 기능 추출기): 각각 5개의 CNN 레이어가 있는 4개의 밀도 블록(DenseBlock)으로 구성.
프레임 레벨 피처 추출 후, 양방향 주의 풀링 레이어는 프레임 레벨 피처를 고정 차원 벡터로 변환하는 데 사용되며, 이어서 완전히 연결된 두 개의 숨겨진 레이어가 발화 레벨 피처를 형성한다. 출력은 소프트맥스 분류기 계층이며, 각 노드는 화자ID에 대응합니다.
Frame level의 특징 추출을 하고, Input과 다음 레이어의 변화에 최적화 시키고, 훈련 효율을 높이기
위해서 사용함.
개념적으로 각각의 dense block들 이 작은 CNN의 역할을 수행하고 있는 것.
각각의 레이어들이 바로 전에 있는 모든 레이어들과 feature map(CNN에서의 합성곱과 같은 원리)을 통해서 연결이 되어있는 방식.
이러한 연결 패턴은 훈련 중 레이어들 사이에서 더 나은 기울기 flow와 각 레이어들에 대한 접근을 모든 feature에게 전달함으로써 일시적인 문맥 정보를 capture 가능.
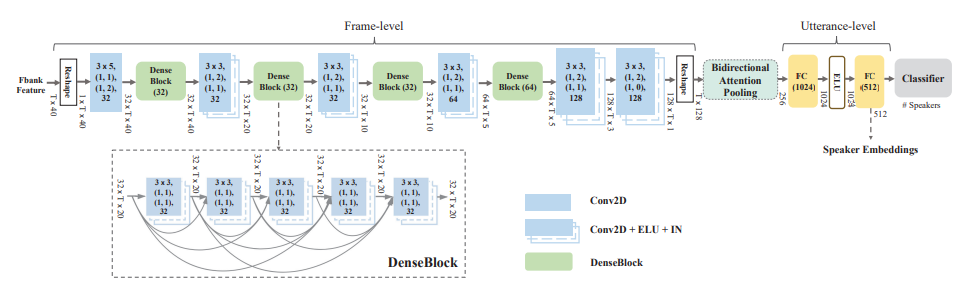
프레임 레벨 단계의 경우 각 DenseBlock은 5개의 컨볼루션 레이어(Conv2D), 지수 선형 단위(ELU) 및 인스턴스 정규화(IN)로 구성된다.
각 밀도 블록 뒤의 텐서 모양은 featureMaps × timeSteps × 주파수 채널 형식이다. 각 Conv2D 및 Conv2D+IN+ELU는 kernelSize 형식으로 지정됩니다. 시간 × kernelSizeFreq, (보행)시간, 보폭Freq), (패딩시간, 패딩Freq), 맵을 특징으로 한다.
각 밀도 블록(g)은 5개의 Conv2D+증가율이 g인 IN+ELU 블록을 포함합니다.
발화 수준 단계의 경우 숫자는 우리의 구현에서 출력 기능 맵 또는 임베딩 차원의 채널을 나타낸다.
DenseBlock
[15]에서 처음 제시된 DenseBlock 아키텍처의 주요 아이디어는 CNN의 네트워크 구축 블록에서 각 계층에서 모든 후속 계층에 직접 연결을 도입하는 것이다.
시간 빈도가 긴 컨텍스트 정보를 효율적으로 캡처하도록 설계되었다.
각 계층은 피쳐 맵 연결을 통해 모든 다음 계층에 직접 연결됩니다. 이러한 연결 패턴은 훈련 중에 계층 간에 더 나은 그레이디언트 흐름을 생성하고 각 계층이 이전 계층의 모든 특징 표현에 액세스할 수 있도록 하여 시간적 컨텍스트 정보를 캡처하도록 설계되었다.
Bidirectional Attentive Pooling
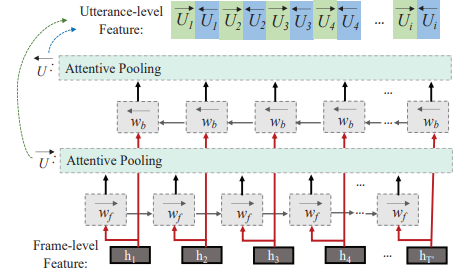
양방향 주의 풀링(bidirectional attentive pooling, BAP)의 도식입니다. hi는 BAP 입력의 i번째 벡터를 나타내며 wf와 wb는 각각 BGRU의 전방과 후방 숨겨진 상태를 나타낸다. →U 및 ←U는 BGRU 레이어의 양방향 출력입니다.
bidirectional gated recurrent unit (BGRU) layer + attentive pooling : utterance level feature
일반적인 average pooling을 사용하지 않은 이유: 평균화 대신 주의 메커니즘[10, 12]은 숨겨진 표현을 적극적으로 선택하고 화자 차별 정보를 강조하기 위한 더 나은 대안이다.
보다 차별적인 고정 차원 발화 수준 표현을 얻고 장기 시퀀스 정보를 캡처하기 위해 [19]는 CNN-BLSTM 모델과 주의 깊은 풀링 레이어를 함께 결합하는 주의 기반 CNN-BLSTM 프레임워크를 제안하였다. BLSTM을 주의 깊은 풀링 계층에 직접 연결하는 [19]와는 달리 주의 깊은 풀링을 사용하여 양방향 반복 신경망에 의해 출력되는 양방향 시간 정보를 캡처한 다음, 양방향 발화 수준 기능을 연결한다.
제안된 풀링 방법인 양방향 주의 풀링(BAP)은 다음과 같이 표현될 수 있다.
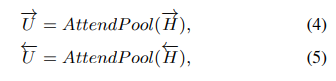
BAP 계층은 양방향 순차 모델링과 주의 메커니즘을 모두 활용하여 장기적인 시간적 컨텍스트 정보를 캡처한다.
Result
Dataset: FFSVC2020
The first 30 utterances are of fixed content: ‘ni hao mi ya’ in Mandarin Chinese for TD-SV tasks.
The remaining utterances are text-independent.
In total, training data sets have nearly 1,139,671 utterances and the total duration approximately 950 hours with 374 speakers
Conclusion
- 텍스트 의존적 스피커 검증을 위한 딥 임베딩 학습 아키텍처를 제안
- 아키텍처는 프레임 수준에서 스피커 ID를 캡처하기 위한 DenseBlock의 스택과 발화 수준에서 스피커 임베딩을 형성하기 위한 양방향 주의 풀링 구조로 구성됨
- 컨볼루션 레이어의 출력을 조밀하게 연결함으로써, 시간 주파수 컨텍스트 정보의 다양한 측면을 가진 보다 의미 있는 프레임 레벨 표현이 생성됨
- 양방향 주의 풀링 계층은 BGRU 계층과 주의 풀링의 조합으로 양방향에서 시간 컨텍스트 정보를 추가로 캡처
- FFSVC2020에서 점수 제출의 경우, 우리가 제안한 방법은 평가 세트의 과제 1과 과제 3에 대한 최소 DCF와 EER에서 각각 0.52와 4.72%, 0.14%를 달성. 또한 이 결과는 x-벡터 및 ResNet 기준선 시스템에 비해 상당한 성능 향상을 보여줌