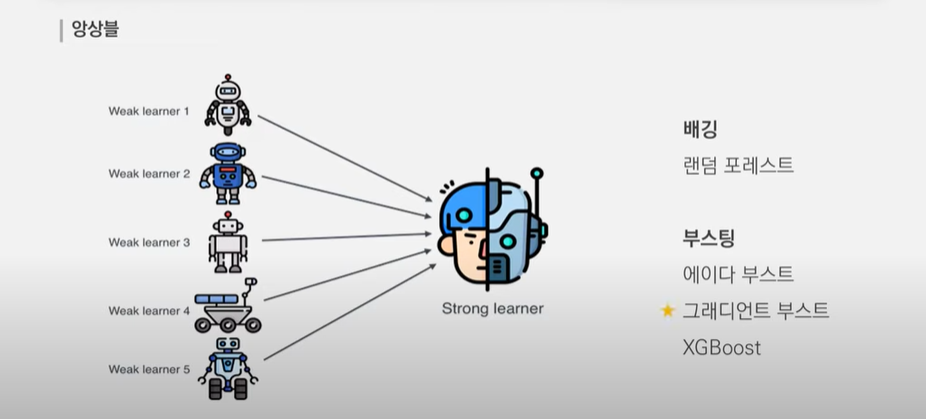
1. Definition
Ensemble
→ 여러 예측기를 수집해서 단일 예측기 보다 더 좋은 예측기를 만드는 것.
- 일반적으로 앙상블 기법을 사용하면 , 예측기 하나로 훈련하였을때 보다 , 편향은 비슷하지만 분산이 줄어든다고 알려져 있다.
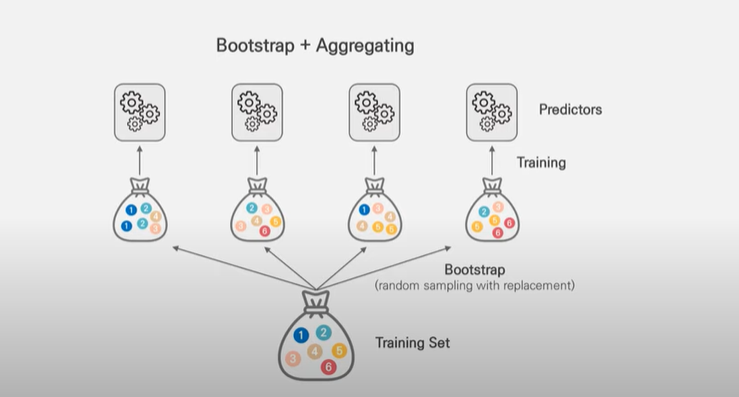
배깅(bagging)
- 원데이터 집합으로부터 크기가 같은 표본을 여러 번 단순임의 복원추출하여 각 표본(붓스트랩 표본) 에 대해 분류기를 생성한 후 그 결과를 앙상블하는 방법
- 반복추출 방법을 사용하기 때문에 같은 데이터가 한 표본에 여러 번 추출될 수도 있고, 어떤 데이터는 추출되지 않을수도 있다.
부스팅(boosting)
- 배깅의 과정과 유사하나 붓스트랩 표본을 구성하는 sampling 과정에서 각 자료에 동일한 확율을 부여하는 것이 아니라, 분류가 잘못된 데이터에- 더 큰 가중을 주어 표본을 추출한다.
Bagging 과 Boosting 의 차이
- Bagging 은 독립된 예측기를 통해 더 나은 예측기를 얻는다
- Boosting 은 앞의 예측기를 보완해 나가면서 더 나은 예측기를 얻는다
랜덤포레스트(random forest)
- 배깅에 랜덤 과정을 추가한 방법이다. 각 노드마다 모든 예측변수 안에서 최적의 분할을 선택하는 방법 대신 예측변수들을 임의로 추출하고, 추출된 변수 내에서 최적의 분할을 만들어 나가는 방법을 사용한다.
부트스트랩(Bootstrap)
- 부트스트랩은 평가를 반복한다는 측면에서 교차검증과 유사하나, 훈련용 자료를 반복 재선정한다는 점에서 차이가 있다.
- 즉 부트스트랩은 관측치를 한번 이상 훈련용 자료로 사용하는 복원추출법에 기반한다.
- 부트스트랩은 전체 데이터의 양이 크지않은 경우의 모형평가에 가장 적합하다.
2. GBM
- Gradient Boosting Machine(GBM)은 Ensemble Learning의 일환
- Gradient Boosting=Gradient Descent+Boosting
- Gradient Descent
- 첫번째 데이터에서 잘 못 맞춘 데이터들에 가중치를 주어, 두번째 모델 에서는 더 많은양을 만들어 준다.
- 또, 두번째 모델에서 잘못 매칭한 데이터들 에게 가중치를 주어서, 세번째 모델을 만들어주는 그러한 방식으로 모델을 반복한다.
- Fit an addictive model(ensemble) in a foward stage-wise manner
- bagging 처럼 한번에 딱 학습을 시키는게 아니고 위에 언급한 것 처럼 하나씩 하나씩 더해가면서 모델을 학습 시켜나가는 모델
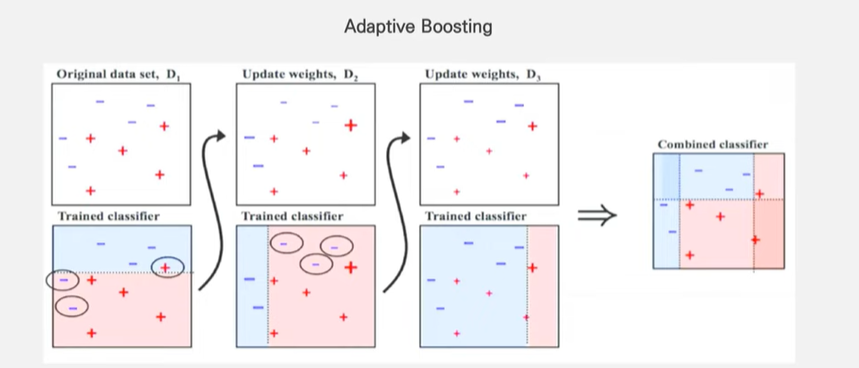
Adaptive boosting
- 모델을 거듭할수록, weak leaner가 만들어 지면서 이전에 가졌던 오류에 대해 해결할 수 있는 능력을 만듦
- 이러한 weak learner 를 만들기 위해 , 앞서 보였던 모델의 shortcoming 을 더 많이 샘플링 하라는 뜻
Gradient Boosting
- 그라디언트 부스팅은, Regression,Classification,Ranking 을 다 할 수 있다. 이 셋의 다르기는 loss function 에서 차이가 날 뿐, concept 은 동일
- 얘는 adaptive boosting 과는 달리, 샘플링을 따로 시행하지는 않는다.
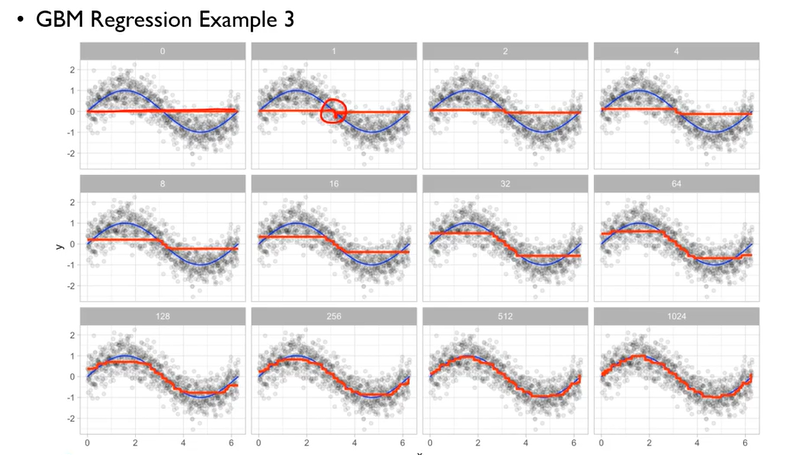
- 잔차를 목푯값 (y) 으로 놓고 계속해서 반복하면서 잔차에 대한 식을 만들어 낸다.
- 잔차를 목표값으로 잡아두면, 앞선 모델이 맞추지 못한 만큼만 맞추려고 노력을 하기때문에, 앞선 모델의 결과물과 뒷 모델의 결과물을 더하면 정답이 나온다.
- 경사도를 통해서 Weak learner 를 boosting 시킴
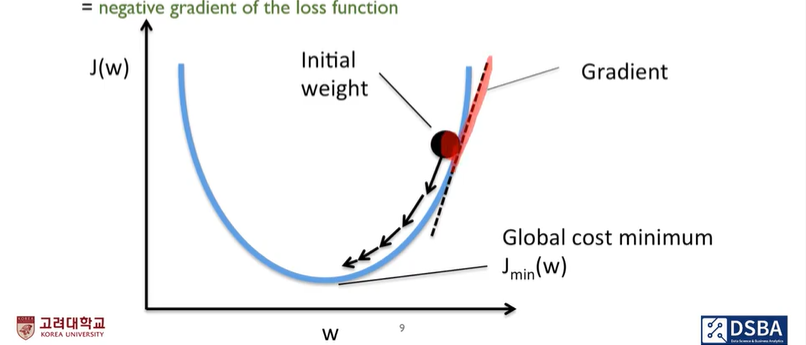
- 손실함수의 gradient(경사도) 가 0 에 가까울때 까지 미분을 해준다.
- Gradient 가 0이 아니라면 weight 를 gradinet 의 반대방향으로 움직이되 얼마만큼 움직이냐에 따라서 달라지니 조금씩 움직인다.
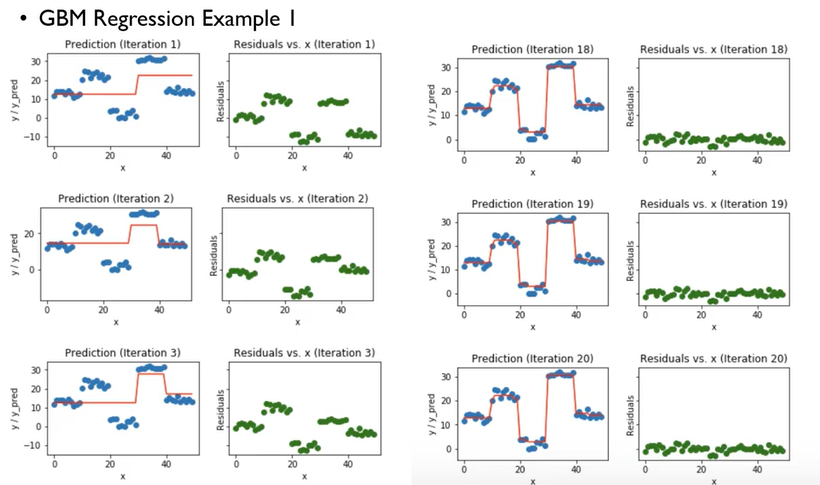
- 처음, decision tree 로 split point 를 잡아, regression 해준 부분의 잔차를 보면 높은것을 알 수 있다. GBM에서는 이 잔차를 기준으로 또 Split point 를 잡아주면서(이러한 과정에서 손실함수가 들어가며 손실함수의 gradient 를 줄여나가는 과정에서 gradient descent 개념이 들어가는 것) 점점 잔차를 줄여 나가는 것을 볼 수 있다.

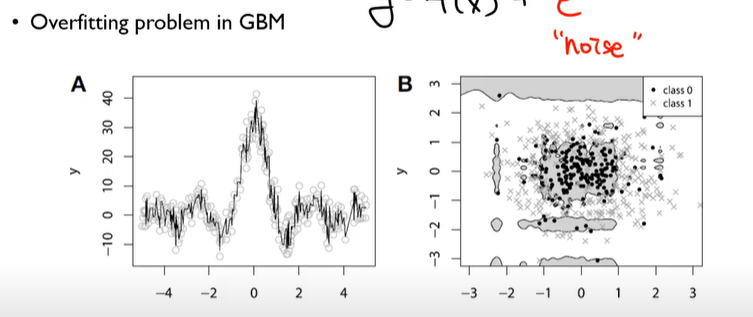
Overfitting problem in GBM
- GBM 의 가장큰 문제점은 오차를 기반으로 모델을 형성 하기때문에(애초에 모델 자체가 반복을 거듭 할수록, 전 모델의 오차를 줄여나가는 모델이기 때문에 오버피팅 문제는 필연적) 우리가 어찌 할수 없는 오차까지도 모델에 학습시키어서 오버피팅 문제를 불러 일으킨다
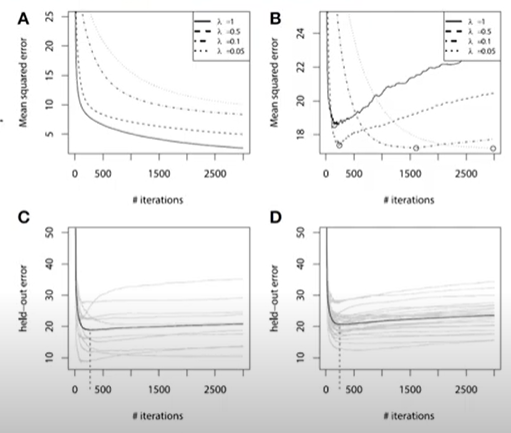
과적합 해결법
- Subsampling→각각의 모델을 만들때 샘플링을 랜덤으로 80% 만해서 모델을 만들어준다
- Shrinkage- original 알고리즘들은 전에 만들어진 모델들과 뒤로 갈수록 만들어지는 모델들에, 영향력이 동등했는데 , shrinkage 를 쓰면 , 뒤에 만들어지는 모델들에 대해서 , 가중치를 적게 두어 만들어준다.
- Early Stopping- validation error 가 증가 할 것 같으면 미리 중지를 시키는것
- Information Gain:Split point를 통해서 얼마나 혼잡도,불순도가 낮아지는가.
- Information Gain 을 통해 그 변수의 영향도를 체크 할 수 있다.

3. LightGBM
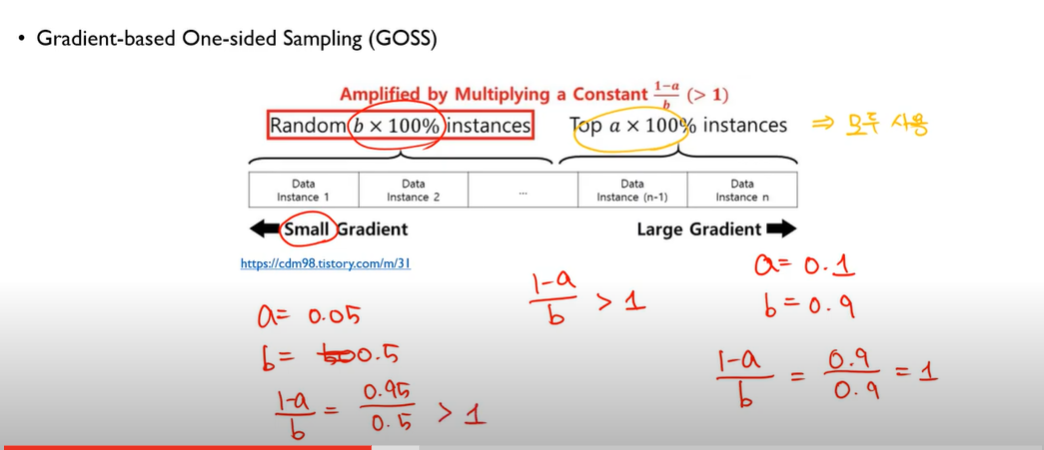
GOSS
- 모든 피쳐들을 검사하면 시간이 많이 걸리기 때문에 이를 막기위해서, Gradient-based One-side Sampling (GOSS) 를 사용→ Large gradient 는 keep 하고 small gradient 는 드랍 하는 방식으로, 1000개 데이터를 모두 탐색하는 것이 아니라 gradient 가 큰 것 위주로 탐색하는 방식 → 탐색횟수를 줄이는 것
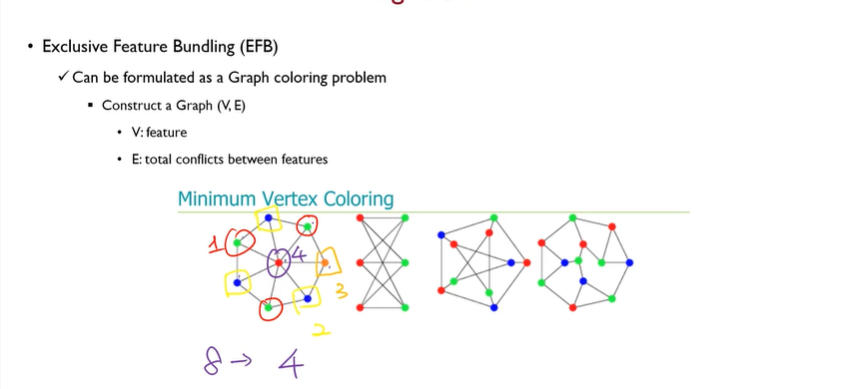
EFB (Exclusive Feature Bundleing)
- 모든피쳐를 탐색할 필요를 없애는 것

- Bundle 을 찾는 방법
- Graph coloring problem 으로 해결가능
- 각각의 노드는 피쳐이고, edge 는 피쳐들간의 conflict → conflict 가 많은 애들은 중복이 많이 들어가서 bundling 이 되면 안됨
- conflict 가 없는 애들 끼리는 bundling 을 해도 됨
Greed bundling 계산법
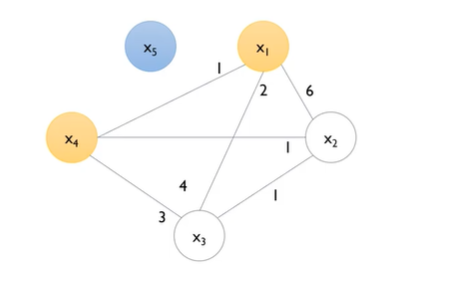
- edge 의 강도: 두 변수의 conflict 강도
- edge: 동시에 0이아닌 객체의 수.
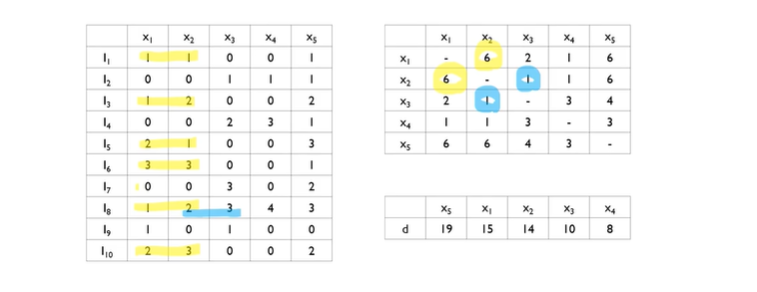
- Degree

- 시작점을 degree의 내림차순으로 정리 해준 다음, degree가 높은것 부터 시작한다.
- cutoff 는 hyperparameter 인데, cut-off가 0.2라는 말은, N=10 이기 때문에 2회 이상 Nonzero value 가 겹치게 되면, bundleing이 안되는 것.
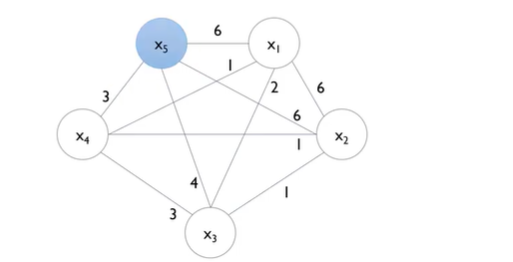
- cut-off 기준에 맞지 않기 때문에 x5는 고립이 된다.
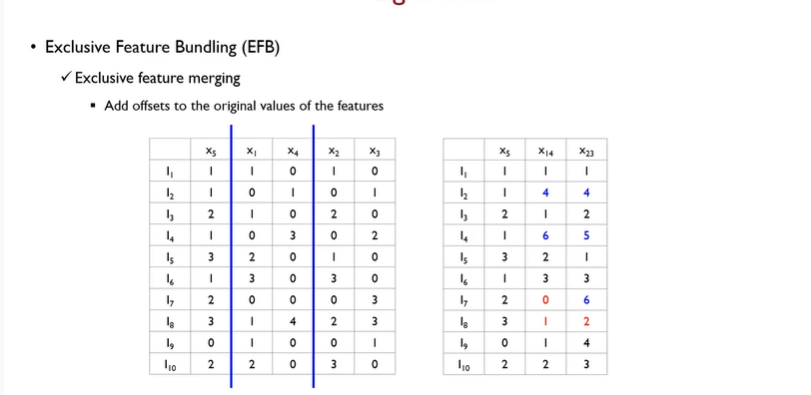
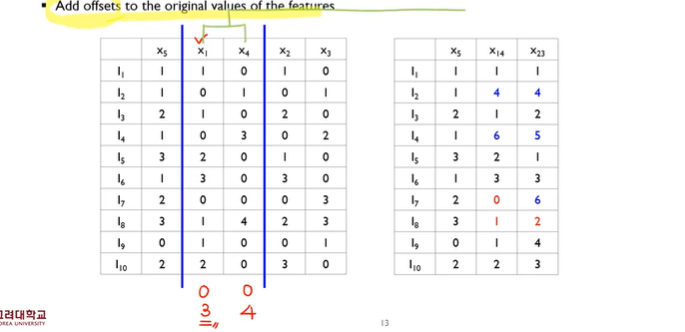
- feature merge 를 쉽게 해주기 위해 feature의 위치를 살짝 조정 하여준다.
- feature 를 merge 하는방법. Add. offset
- add offset→bundling 을 하기위한 대상이 되는 변수에다가 기준이 되는 변수가 가질 수 있는 최대 값을 더해준다.
- conflict 가 일어난 부분은 그대로 기준 변수가 가지는 값을 더해준다.
- Reference: 고려대학교 산업경영공학부 DSBA 연구실