Transformer란?
트랜스포머(Transformer)는 구글에서 발표한 논문 “Attention is all you need”에 나오는 모델이다. 아래 글은 이 논문 abstract의 일부분이다.
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 Englishto-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU …
여기서도 알 수 있듯이, 트랜스포머는 어텐션(Attention) mechanism을 기반으로 여러개의 인코더와 디코더를 연결한 구조를 갖고 있다. 또한 CNN, RNN, LSTM 등의 구조를 사용하지 않았기 때문에 학습 시간이 훨씬 감소된 성능을 내었다고 한다. 그렇다면 그 구조가 무엇인지 더 알아보도록 하자.
(1) 트랜스포머의 입력
먼저 트랜스포머의 입력부터 알아보자, 단어 벡터 데이터가 트랜스포머의 입력으로 들어가지게 되는데 이 때 각 단어의 위치 정보를 알려주어야 한다. 왜냐하면 트랜스포머에 단어가 입력될 때 순차적으로 받아지지 않기 때문이다. 따라서 순서 정보를 더해주어야 하기 때문에 위치 정보를 각 단어 벡터마다 더해주어야 하는데, 이 과정을 포지셔널 인코딩(positional encoding)이라고 한다.
포지셔널 인코딩 값을 더해주기 위해서는 사인함수와 코사인함수를 사용한 아래 두 함수를 사용한다.
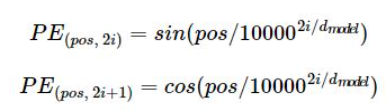
위 식에서 pos는 입력된 데이터의 임베딩 벡터(몇번째 단어인지)를, i는 임베딩 벡터내의 차원의 인덱스(0~512)를 뜻한다. 임베딩 벡터내의 차원이란 트랜스포머 모델의 인코더와 디코더에서 정해진 입력과 출력의 크기를 말한다. 논문상에서 이 차원을 512로 설정했으면 이 차원은 인코더의 값을 디코더로 보낼때 값을 유지하도록 한다.
다시 돌아와서, 위 함수에서 차원이 2i(짝수)인지 2i+1(홀수)인지에 따라서 사용하는 함수가 다르다. 짝수 차원의 경우 사인함수, 홀수차원의 경우 코사인 함수를 사용하게된다.
(2)인코더(Encoder)의 구조
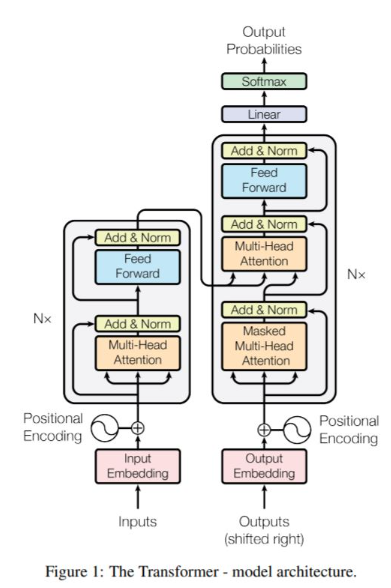
위 이미지는 트랜스포머 논문에 함께 실려 있는 이미지로, 트랜스포머의 구조를 나타낸다.
여기서 왼쪽 부분이 트랜스포머의 인코더 부분인데, 인코더의 구조는 어떻게 이루어졌을까?
먼저 이미지 왼쪽 아래를 보자. Input data가 들어가게 되면 Input Embedding을 거치게 되는데, 여기서는 문자열인 단어 데이터를 벡터형태로 변환해 준다(단어 길이 X 벡터차원의 행렬). 그리고 나서 위에서 설명한 포지셔널 인코딩을 수행해주게 된다.
그러고 나서 박스로 표현된 인코더에 들어가게 된다. 인코더 안에서는 크게 Multi-Head Attention과 Feed Forward과정이 수행되는데, Multi-Head Attention은 셀프 어텐션이 병렬적으로 사용된 것을 말하며, Feed Forward란 피드포워드 신경망 구조를 의미한다.
한편, 위에서 잠깐 언급했지만 트랜스포머에서는 여러 개의 인코더와 디코더를 쌓은 구조를 갖고 있다. 즉, 인코더가 1개가 아니라는 뜻인데, 논문에서는 6개의 인코더 층을 사용했다고 하니, 6개라고 설정하도록 하겠다. 아무튼, 인코더 과정을 총 6번 반복한다고 생각하면 된다.
*셀프 어텐션이란?
셀프 어텐션이란 자기 자신에게 어텐션 함수를 수행하는 것을 말하는데, 그렇다면 어텐션이란 무엇일까?
어텐션에서도 다양한 종류가 있는데 간단히 말하자면, 쿼리(Query)가 주어졌을 때, 이 쿼리와 여러개의 키(Key)와의 유사도를 각각 구하고, 구한 유사도를 가중치로 설정하여 각각의 값(value)을 구한 뒤, 이 값(유사도가 반영된 값)들을 모두 가중합하여 반환하는 함수를 말한다.
예를 들어, 한 텍스트 문장이 쿼리로 입력될 때, 각 단어 벡터들과의 유사도를 계산해 이 유사도를 가중합하여 반환된 값이 그 문장의 어텐션 값이 된다.
그렇다면 셀프 어텐션 값을 구하기 위해서 입력된 문장의 단어 벡터(쿼리)에 대해 쿼리(query),키(key), 값(value) 벡터가 정의되어야 할 것이다. 그 과정은 아래 이미지를 통해 쉽게 이해할 수 있다.
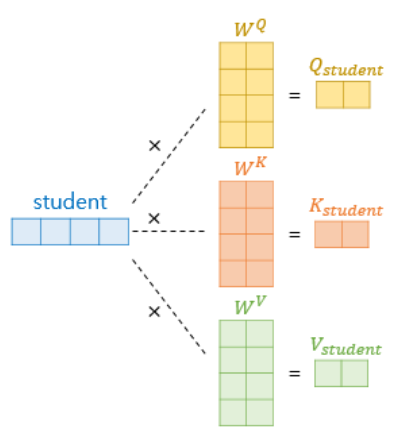
‘student’라는 단어 벡터가 입력되었을 때, 각각 쿼리, 키 값의 가중치 행렬을 곱해주어 쿼리, 키, 값 벡터를 얻어낸다. 이렇게 쿼리 벡터, 키 벡터, 값 벡터를 얻어냈다면 쿼리 벡터는 모든 키 벡터에 대해 어텐션 스코어(attention score)를 구하게 되고, 이를 이용하여 모든 값 벡터를 가중합 하여 어텐션 값을 구하게 된다.
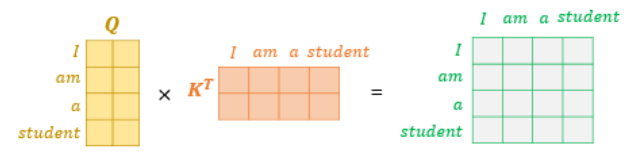
한편, 이러한 연산은 각 단어마다가 아닌 문장 전체에 대해서 행렬 연산으로도 일괄적으로 연산이 가능한데, 위와 같이 문장에 대한 쿼리 벡터, 키 벡터의 연산을 통해 값 벡터 행렬을 구할 수 있게 된다.
마지막으로 쿼리벡터와 키 벡터가 연산되어 나온 행렬에 전체적으로 특정 값(key벡터 차원의 제곱근 값)을 나누어 준 뒤, 소프트맥스 함수를 적용해주고, 가중치가 계산된 값 벡터를 곱하게 되면 최종적으로 각 단어의 어텐션 값을 가지는 어텐션 값 행렬이 도출된다.
즉, 요약하자면 어텐션 함수는 쿼리(Query)가 주어졌을 때, 이 쿼리와 여러개의 키(key)와의 유사도를 각각 구하고, 구한 유사도를 가중치로 설정하여 각각의 값(value)을 구한 뒤, 유사도가 반영된 값들을 모두 가중합 하여 반환하는 함수를 말한다.
*멀티 헤드 어텐션(Multi-Head Attention)이란?
앞에서 트랜스포머의 인코더에서는 어텐션이 병렬적으로 수행되는 멀티 헤드 어텐션이 수행된다고 했다. 논문에서는 512차원의 벡터를 8로 나누어 54차원의 Query, Key, Value 벡터로 바꾸어서 어텐션 함수를 병렬적으로 수행한 것인데, 그렇다면 왜 이렇게 수행한 것일까?
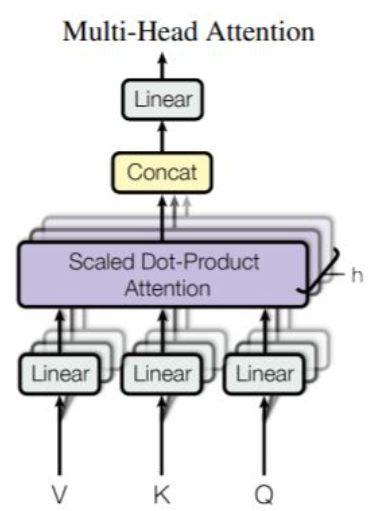
즉, 차원을 나누어서 어텐션 함수를 수행한 뒤, 가중치 행렬을 곱해주고 이를 다시 합치게 되는건데, 논문에 따르면 single attention function을 하는 것보다 병렬적으로 수행하는 것이 모델이 학습하는 데에는 더 효과적이었으며, 모델이 다른 영역(과거시점과 미래시점)에 있는 정보들을 참조할 수 있다고한다. 따라서 출력된 값들은 인코더의 입력 값의 차원과 동일하게 유지된다.
*피드 포워드 신경망이란?
인코더 안에서 Multi-Head Attention이 수행되고 나면 Feed Forward가 수행된다고 했었는데, Feed Forward는 무엇일까?
Feed Forward는 일종의 신경망으로 Feed Forward Neural Network를 줄여서 FFNN이라고 한다. FFNN의 종류도 여러가지가 있는데, 트랜스 포머의 인코더 층에는 포지션 와이즈(Position-wise) FFNN을 사용한다. 포지션 와이즈 FFNN은 Fully-connected FFNN과 같은 기능을 하는데, 아래와 같은 연산을 수행한다.
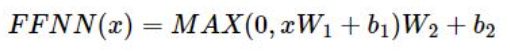
위 식에서 x의 값은 Multi-Head Attention에서 출력된 행렬 값이다. 반면, 가중치를 의미하는 W1, W2, b1, b2는 가중치 값으로 인코더 마다 다른 값을 가지지만 하나의 인코더 층 안에서는 문장과 단어들마다 동일하게 사용된다고 한다. 이렇게 피드 포워드 신경망까지 거치게 되면 한 인코더의 출력값이 도출 되고, 이 값은 다시 두번째 인코더 입력으로 들어가게 되며 이 과정이 반복된다.
*Add & Norm
한편 인코더의 구조를 보여준 이밎를 다시 보고 오면 2개의 서브층인 Multi-Head Attention과 Feed Forward가 각각 끝나고 나면 Add & Norm 이라는 단계가 수행된다. 이것은 또 무엇일까?
논문의 일부분을 읽어보면 Add & Norm이란 바로 두개의 서브층을 residual connection 해주고 layer normalization을 해주는 것을 의미한다.
We employ a residual connection [11] around each of the two sub-layers, followed by layer normalization [1]. That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself.
Residual connection과 layer normalization에 대해 짧게 요약하자면, residual connection은 서브층의 입력과 출력을 더 하는 것이다. 이러한 알고리즘은 RNN, VGG 구조에서도 볼 수 있고, 이러한 연산이 가능한 것은 입력 데이터와 출력 데이터가 동일한 차원을 갖고 있기 때문이라고 한다.
반면, layer normalization은 정규화를 하는 과정으로 출력된 값들에 대해서 평균과 분산을 구해서 정규화를 하는 것을 말한다. 앞에서 입력데이터인 512차원의 벡터를 8로 나누어 어텐션 함수를 병렬적으로 수행하였다고 했는데, 그렇게 출력된 8개의 값들로 layer normalization을 하는 것이다.
(3)디코더(Decoder)의 구조
다시 트랜스포머의 구조를 살펴보자. 지금까지 왼쪽에 있는 인코더에 대해 살펴 보았고, 이제 오른쪽에 있는 디코더에 대해 살펴보도록 하겠다.
디코더는 인코더에서 넘겨받은 값에 대해 Multi-Head Attention과 Feed Forward를 수행하기 전 output data에 대해 임베딩과 포지셔널 인코딩을 한 값을 입력 받는다. 그리고 인코더와는 다르게 Masked Multi-Head Attention이라는 것을 해주게 된다.
*Masked Multi-Head Attention이란?
Masked Multi-Head Attention은 말그대로 Multi-Head Attention에서 Mask기능이 들어간 것이다. 앞에서 Multi-Head Attention은 셀프어텐션을 병렬적으로 수행한 것을 의미했었다. 따라서 다른 영역에 있는, 즉 미래의 시점에 있는 단어의 정보도 알 수 있게 된다고 했었다. 이러한 이유로 트랜스포머의 디코더에는 현재시점보다 미래에 있는 단어를 참고해 예측하지 못하고 이전시점들에 있는 단어들만 참고할 수 있도록 마스킹해줘야 한다. 아마 미래에 있는 단어를 참고해 예측하도록 한다면 학습하는데 도움이 되지 않는가 보다. 답지보고 베끼는 느낌이랄까?
아무튼 마스킹을 하기 위해 lood-ahead mask라는 것을 해주는데, Multi-Head Attention을 통해 나온 행렬 값에 대해 마스킹을 하고자 하는 값에는 1, 마스킹을 하지 않는 값에는 0을 리턴하도록 한다. 그리고 나서 Add & Norm 과정을 수행해준뒤 도출된 결과를 다음 결과로 보내준다.
*디코더의 Multi-Head Attention과 Feed Forward
디코더에서 Masked Multi-Head Attention이 수행되고 나면 그 다음부터는 인코더와 마찬가지로 Multi-Head Attention과 Feed Forward가 수행된다. 근데 이때 Multi-Head Attention에 입력으로 들어가는 값들을 잘 살펴 봐야 한다. 인코더에서 출력된 값과 디코더 첫번째 서브층에서 출력된 값이 인풋으로 들어가기 때문이다.
두번째 서브층인 Multi-Head Attention에서는 마찬가지로 셀프어텐션 함수를 수행하기 위해 Query, Key, Value 벡터가 입력되어야 한다. 이때 Query는 디코더 첫번째 서브층에서 출력된 값이 해당되고, Key 벡터와 Value 벡터는 마지막 인코더에서 출력된 값으로 입력된다. 그리고 똑같이 Multi-Head Attention을 수행해주게 된다. 이렇게 6개의 디코더마다 Multi-Head Attention의 Query 벡터는 디코더 첫번째 서브층의 output, Key벡터와 Value벡터는 인코더의 output이 입력으로 들어가게 된다.