Journal/Conference: NIPS
Year(published year): 2017
Author: Ishaan Gulrajani, Faruk Ahmed, Martín Arjovsky, Vincent Dumoulin, Aaron C. Courville
Subject: DCGAN, Generative Model
Improved Training of Wasserstein GANs
Summary
- 기존의 Wasserstein-GAN 모델의 weight clipping 을 대체할 수 있는 gradient penalty 방법을 제시
- hyperparameter tuning 없이도 안정적인 학습이 가능해졌음을 제시
Introduction
GAN 모델을 안정적으로 학습하기 위한 많은 방법들이 존재해왔습니다.
특히, 가치함수가 수렴하는 성질을 분석하여 Discriminator(이후 Critic)가 1-Lipschitz function 공간에 있도록 하는 Wasserstein GAN(WGAN) 이 제시된 바 있습니다.
논문은 WGAN 의 단점을 개선한 WGAN-GP 모델을 제시합니다.
- Toy datasets에 대해 critic의 weight clipping이 undesired behavior를 유발할 수 있음을 증명
- “Gradient penalty”(WGAN-GP) 기법으로 제안
- 다양한 GAN 구조에대해 안정적인 학습을 수행할 수 있고, 고품질 이미지 생성을 수행하며, 개별 샘플링이 필필요하지 않는 문자수준 언어 모델을 제시
Background
Generative adversarial networks
일반적인 GAN 구조에 대해 다시 한번 개념을 되짚습니다.

Wasserstein GANs
WGAN 은 GAN 의 목적함수인 JSD 가 parameter 에 연속적이지 않에 학습에 문제가 발생함을 지적하였습니다. 이에, Earth-Mover distance 로 모든 구간에서 연속적이고 대부분의 구간에서 미분 가능하게 하여 문제를 해결하였습니다.

이외에도 WGAN 의 특징에 대해 서술하며, 가장 중요한 특징으로 Lipschitz 조건을 만족하기 위해 시행하는 weight clipping 을 언급합니다.
Properties of the optimal WGAN critic
최적의 WGAN critic 을 가정했을 때, ****weight clipping이 WGAN critic에서 문제를 발생시킴을 언급하고 증명한 결과를 제시합니다.

Difficulties with weight constraints
WGAN의 weight clipping이 최적화에 문제를 발생시킬 수 있고, 최적화가 잘 되더라도 critic이 pathological value surface 을 가질 수 있음을 증명하였던 내용을 확인하기 위한 실험을 진행합니다.
논문은 기존 WGAN 이 제시하였던 hard clipping 방식 이외에도, L2 norm clipping/weight normalization/L1 and L2 weight decay 등의 weight constraint 를 가정하였을 때 모두 비슷한 문제가 발생하였음을 언급합니다.
Capacity underuse & Exploding and vanishing gradients
k-Lipshitz 조건을 달성하기 위해 weight clipping 을 수행하였을 때, critic은 더욱 단순한 형태의 함수를 취하게 됩니다.
논문은 이를 증명하기 위해 Generator 의 분포를 toy distribution + unit-variance 가우시안-노이즈에 고정한뒤, weight clipping 과 함께 WGAN critic 을 학습한 결과를 제시합니다.
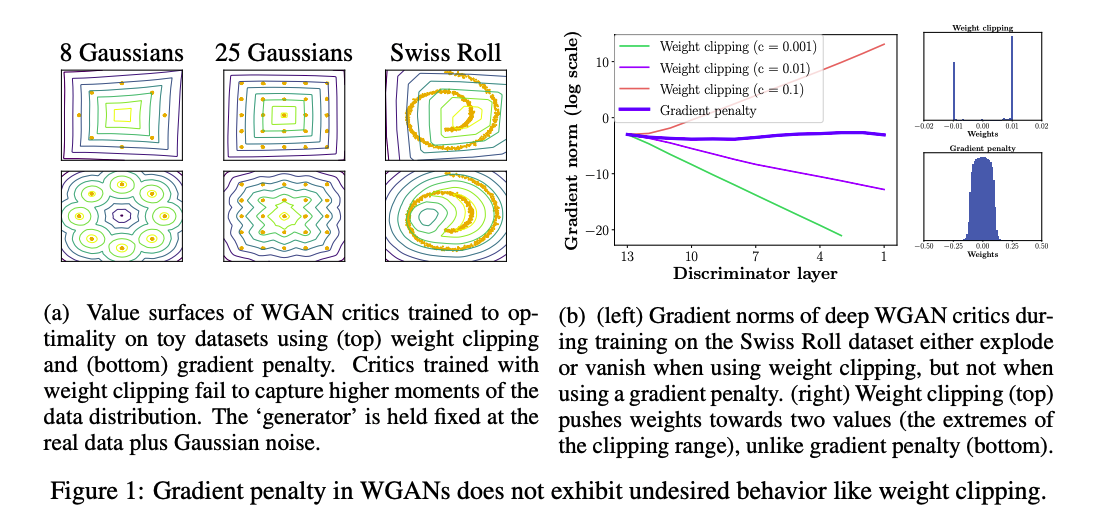
왼쪽 그림에서 Weight clipping 수행한 경우의 value surface 모양이 단순해졌음을 확인할 수 있습니다. 또한, 우측 그림과 같이, Gradient penalty 를 수행한 경우에 gradient vanishing 이나 exploding 이 발생하지 않았음을 제시합니다.
Gradient penalty
Weight Clipping 을 사용하지 않고 Lipschitz constraint 를 유지할 수 있는 방법을 설명합니다.
입력에 대한 Critic 출력 gradient 의 크기를 직접 제약합니다. 이 때, tractability issue 를 피하기 위해 무작위로 추출한 샘플 $\hat{x}$ 의 gradient norm 을 사용해 soft 한 제약을 줍니다.
이렇게 새롭게 정의되는 목적함수는 아래와 같습니다.
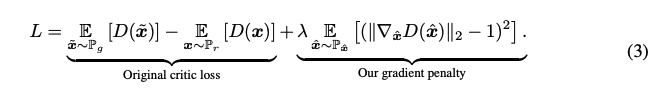
Sampling distribution
논문은 데이터 분포와 generator 분포에서 샘플링한 점의 쌍을 이은 뒤, 점을 잇는 선분을 따라 $\hat{x}$ 를 샘플링하였고, 실험적으로 좋은 성능을 얻었음을 언급합니다.
Penalty coefficient
gradient penalty 를 가하는 정도를 경정하는 계수로, 논문에서는 모두 $\lambda=10$ 을 사용했음을 언급합니다.
No critic batch normalization
기존 GAN 모델은 batch normalization 을 모든 곳에서 사용했지만, 이는 discriminator의 단일 입력을 단일 출력으로 매핑하는 문제에서, 입력의 전체 배치로부터 출력의 배치로 매핑하는 문제로 변화시킵니다. 이 때문에 gradient penalty 를 수행하면 batch normalization 이 유효하지 않은 결과가 발생한다고 합니다. 따라서 논문은 critic 에 batch normalization 을 제거하였고 그럼에도 적절한 성능을 보였음을 언급합니다.
Two-sided penalty
gradient penalty 는 norm이 1 아래에 머무르지 않고(one-sided penalty), 1로 향하기(two-sided penalty)는 것을 촉진한다는 점을 제시합니다.
Experiments
Training random architectures within a set
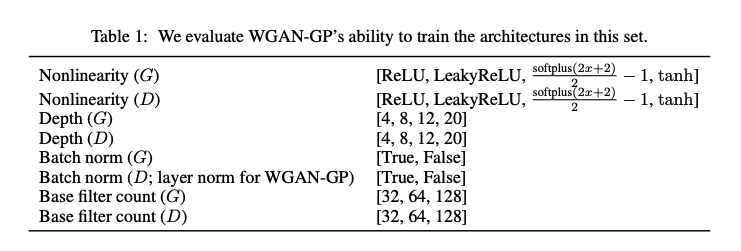
일반적인 DCGAN 구조에서 위의 표의 설정을 랜덤하게 설정하여 모델을 구성합니다. 이렇게 무작위로 200개의 모델을 구성한뒤, 32x32 ImageNet 에 대해 WGAN-GP, standard GAN을 합니다.

구성한 모델의 inception_score 가 min_score 보다 큰 경우 성공으로 분류합니다. WGAN-GP 는 많은 구조를 학습하는데 성공했다는 결과를 제시합니다.
Training varied architectures on LSUN bedrooms
아래와 같이 6개의 모델을 기본 모델로 사용합니다.

여기에 DCGAN, LSGAN, WGAN, WGAN-GP 를 각각 적용하였을 때의 성능을 비교합니다. 단, WGAN-GP는 discriminator 에서 Batch normalization 을 사용할 수 없기에 layer normalization 을 사용합니다.

WGAN-GP 를 제외한 모든 모델에서 불안정하거나 mode collapse 에 빠진 모습을 보입니다.
Improved performance over weight clipping
WGAN-GP 가 weight clipping 에 비해 더 빠른 학습 속도와 샘플 효율을 보인다는 점을 증명하기 위한 실험 결과를 제시합니다. 이를 위해, WGAN 과 WGAN-GP 모델을 CIFAR-10 으로 학습하여 Inception Score 를 계산합니다.
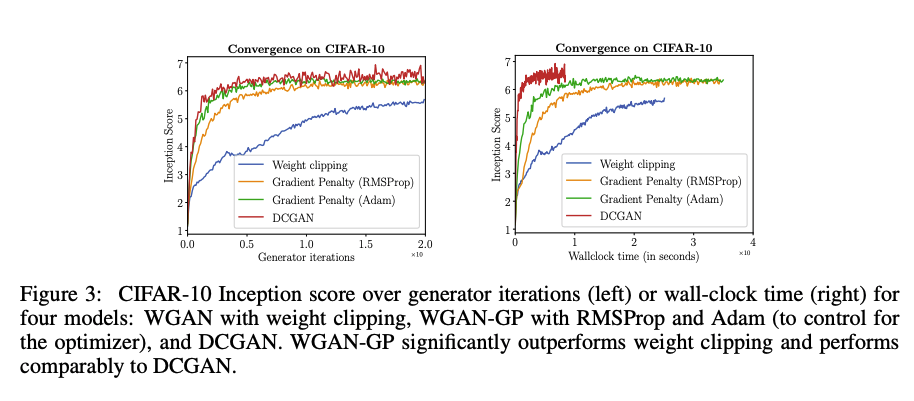
왼쪽은 iteration에 따른 Inception Score이며, 오른쪽은 시간에 따른 Inception Score입니다.
WGAN-GP는 weight clipping 보다 항상 더 좋은 성능을 보입니다. 이는 같은 optimizer 를 사용했을 때도 마찬가지이며, 비록 DCGAN 보다는 느리지만 수렴에 있어서 안정적인 점수를 보일 수 있음을 제시합니다.
Sample quality on CIFAR-10 and LSUN bedrooms
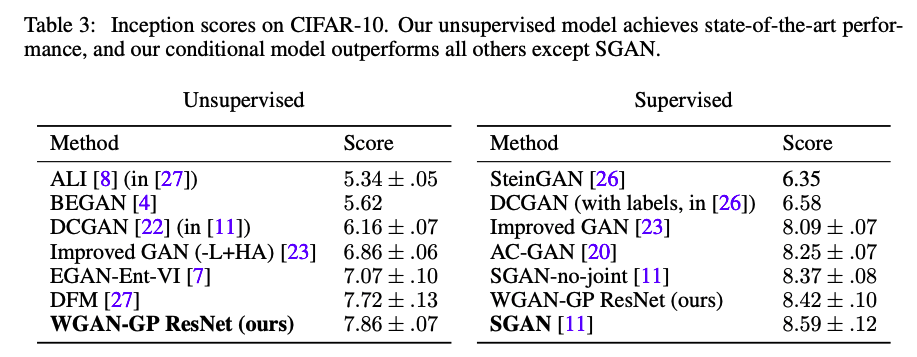
CIFAR-10으로 학습한 모델의 Inception score 를 계산하여 다양한 구조의 GAN을 비교한 표를 제시합니다. WGAN-GP 는 Supervised 의 경우 SGAN 을 제외했을 때 가장 좋은 성능을 보입니다.

또한, WGAN-GP 로 deep ResNet 모델을 사용하여 128X128 LSUN 침대 이미지를 생성하여 위와같은 결과를 제시합니다.
Modeling discrete data with a continuous generator

Generator 는 연속적인 분포의 함수를 가정합니다. 따라서언어 모델은 비연속적인 분포를 모델링 해야하므로 GAN 으로 학습하기에 부적절할 수 있습니다.
위는 Google Billion Word 데이터셋을 사용해 문자 수준 언어 모델을 WGAN-GP 로 학습한 결과입니다. 모델이 빈번하게 철자를 틀리지만, 언어의 통계에 대해서는 어느정도 학습을 수행하였음을 볼 수 있습니다.
Meaningful loss curves and detecting overfitting
기존의 weight clipping 은 loss 가 sample quality 와 연관되어 최소값으로 수렴할 수 있다는 점입니다. WGAN-GP 가 해당 특성을 유지하는지 확인하기 위한 테스크를 진행한 결과를 제시합니다.
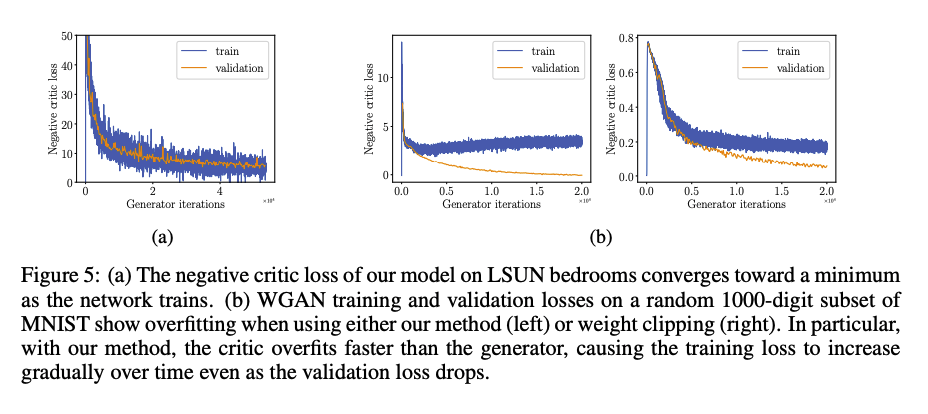
(a)에서 LSUN 침대 데이터셋을 학습하고 critic 의 negative loss 를 그렸을 때, Gnerator 가 학습됨에 따라 값이 줄어드는 것을 확인할 수 있습니다. 이 경우, WGAN-GP가 critic에서의 과적합을 완화했다고 볼 수 있습니다.
또한, MNIST 무작위 숫자 1000개로 학습한 결과는, 적은 데이터셋을 사용한 만큼 과적합이 발생하기 쉽습니다. 때문에, critic이 generator보다 더 빨리 과적합되어 training loss를 점차 증가시키고 validation loss를 감소시켰음을 확인할 수 있습니다.
Conclusion
WGAN에 Gradient penalty를 적용하여 기존의 weight clipping 을 적용함으로 인해 발생하는 문제를 해결할 수 있음을 제시하였습니다.
Summarize
- GAN의 가장 큰 문제는 학습환경이 매우 불안정하다는 것이다. 생성자와 구분자 둘 중에 하나가 실력이 월등이 좋아진다면 밸런스가 붕괴되고 모델이 정확히 학습되지 않고 학습이 완료된 후에도 mode dropping 이 생기는데 이는 구분자가 그 역할을 충분히 하지 못해 모델이 최적점까지 학습이 안 된 것이다.
- 따라서 이 문제를 해결하기 위해 본 논문에서는 WGAN 방법을 도입했다.
- 간단히 설명하면 GAN의 discriminator보다 선생님 역할을 잘 할 수 있는 critic을 사용함으로써 gradient를 잘 전달시키고 critic과 generator를 최적점까지 학습할 수 있다는 것이다. 그렇다면 이를 적용하면 학습시킬 때 생성자와 구분자의 밸런스가 잘 맞는지 주의깊게 보지 않아도 되고 학습한 이후에 발생하는 mode droppin이 해결 가능하다.
- 식을 해석해보면 생성자가 Lipschitz 함수 조건을 만족하는가 하지않는가에 대한 기준이 하나 더 생기는것 이다.