1. Classification
- 분류나 예측을 진행할때 나랑 가장 가까운 이웃 k개를 고려하겠다.
- 나랑 가까운 이웃 한명이 검정색이면 검정색으로 판단
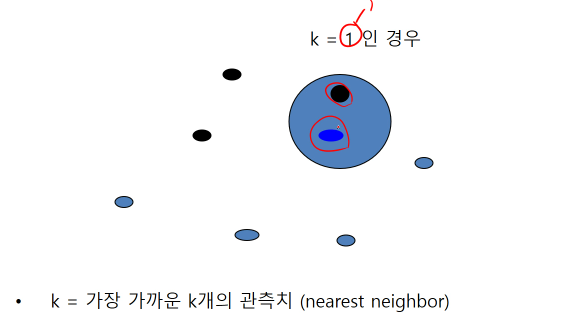
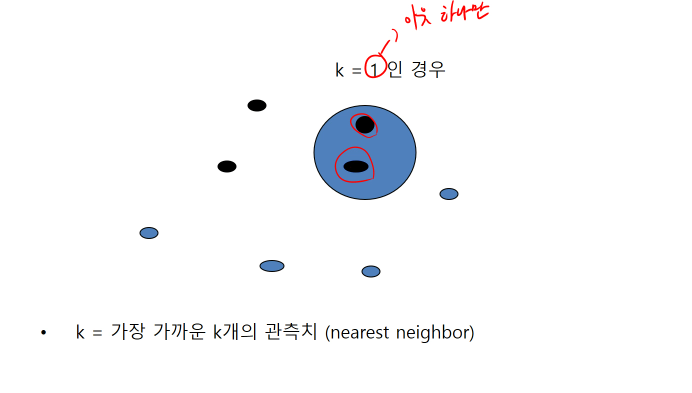
- 파란색의 가장 가까운 이웃을 확인해본 결과 검정색 이므로 파란색도 검정색으로 분류되었다
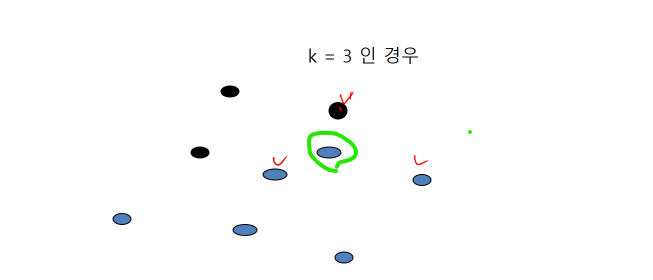
- K=3 일 경우 형광색 친구를 분류한다고 하였을때 이웃중 파란색이 2개 검정색이 한개이기 때문에 파란색으로 분류된다.
- 분류를 원하는 관측치의 주변 N개의 데이터(근접 이웃)을 골라서, 주변대세를 확인 (다수결의 원칙으로)
2. Prediction
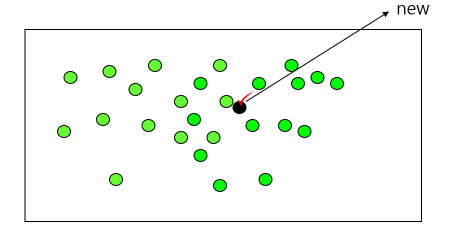
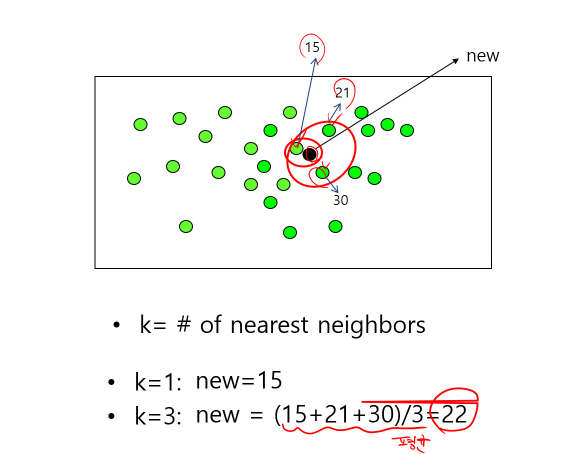
- 인접 K개의 데이터의 수치를 확인해줘서 그 데이터의 평균을 검은점의 예측치로 설정해준다.
3. How to find optimal k?
k의 결정
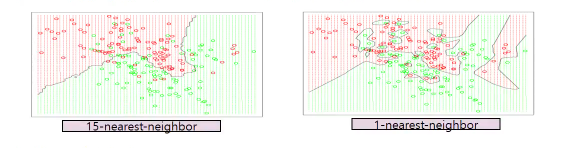
- k가 너무 큰 경우, KNN모델이 지나치게 일반화됨
- K가 너무 작은 경우,KNN 모델의 예측 결과의 분산이 큼
- 주로 이것저것 해보고 error이 가장 작은 k를 설정하여준다.
거리 척도의 결정
- 상황에 맞는 거리척도를 사용하여야 한다.
- 거리척도의 종류:Minkowski distance , Euclidean distance, Citi block distance, Mahalanobis distance, Correlation distance 등
- Reference: 한국공학대학교 강지훈교수님 강의