Preparation
- installing spark
- need python3
- if you are first using python, install anaconda
Installing JAVA
Installing file: Java SE 8 Archive Downloads (JDK 8u211 and later)
Need to login Oracle
Run the download file as admin → Click Next button → Changing the path on file (Space between words like
Program Filescan be problem during installation)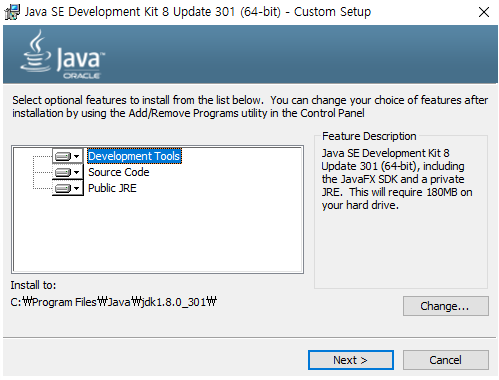
Changing Path
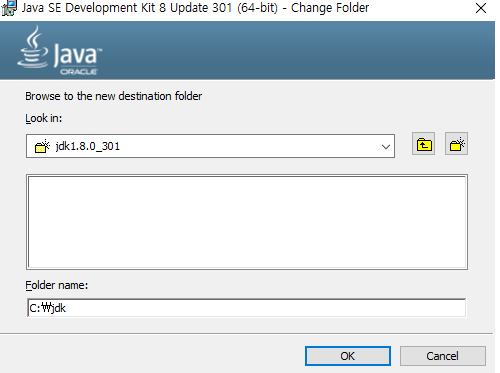
Same changes to folders in the JAVA runtime environment folder (Click ‘Change’ and modify)
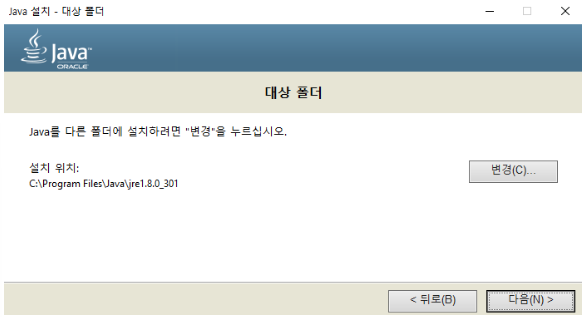
Create and save
jrefolder in the path right after the C dirve
Installing Spark
Installing site: https://spark.apache.org/downloads.html
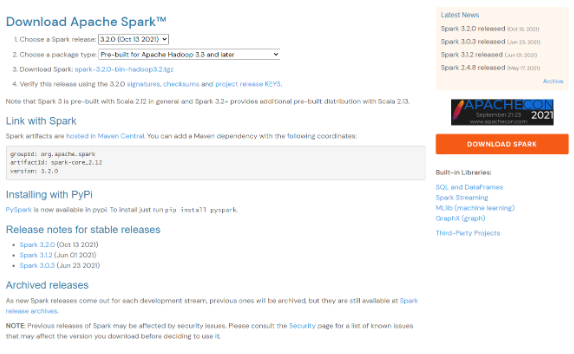
Download installation file
After clicking
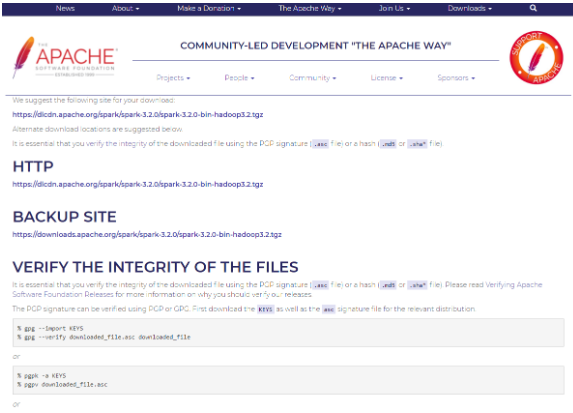
Download Spark: [spark-3.2.0-bin-hadoop3.2.tgz](https://www.apache.org/dyn/closer.lua/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz), you can download it by clicking theHTTP 하단page like picture below- Installation URL: https://www.apache.org/dyn/closer.lua/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz (2022.01)
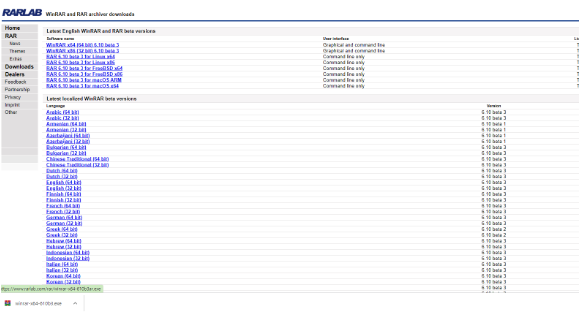
Download WinRAR Program
- You need to install
WinRAR, to unzip.tgzfile. - Installation file: https://www.rarlab.com/download.htm
- Install what fits your computer
- You need to install
Create Spark folder and move files
- Moving files
- Copy all the file in spark-3.2.0-bin-hadoop3.2 folder
- After that, create spark folder below C drive and move all of them to it.
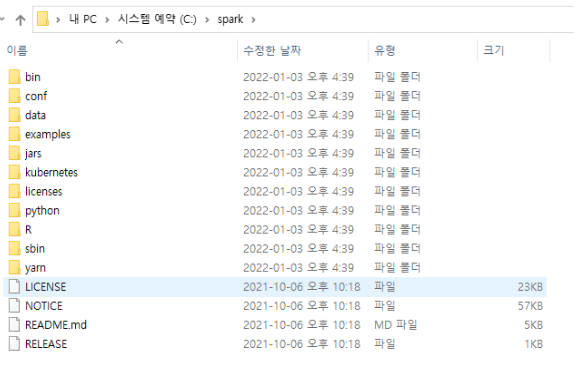
- Moving files
Modify log4j.properties file
• Open the file
conf-[log4j.properties](http://log4j.properties)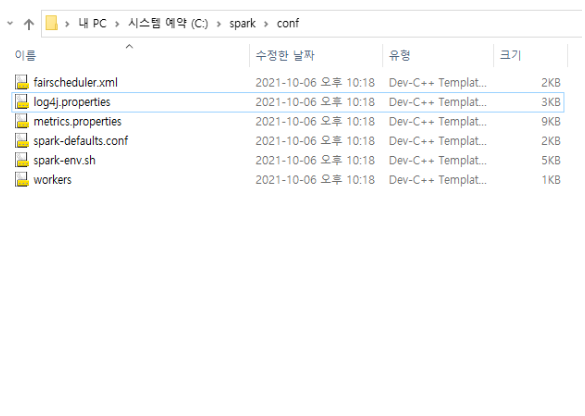
Open the log file as notebook and change
INFO→ERRORjust like example below.- During the process, all the output values can be removed.
1
2
3
4
5
6
7# Set everything to be logged to the console
# log4j.rootCategory=INFO, console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
Installing winutils
- This time, we need program that makes local computer mistakes Sparks for Hadoop.
- Installing file: https://github.com/cdarlint/winutils
- Download winutils programs that fit installation version.
- I downloaded version 3.2.0
- Installing file: https://github.com/cdarlint/winutils
- Create winutils/bin folder on C drive and save the downloaded file.
- Ensure this file is authorized to be used so that it can be executed without errors whne running Spark
- This time, open CMD as admin and run the file
- If ChangeFileModeByMask error (3) occurs, create
tmp\hivefolder below C drive.
1 | C:\Windows\system32>cd c:\winutils\bin |
Setting environment variables
Set the system environment variable
- Click the
사용자 변수 - 새로 만들기button on each user account
- Click the
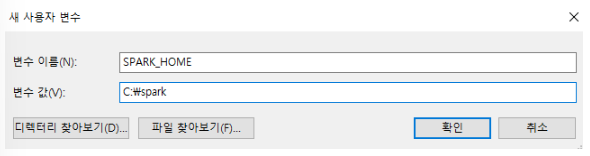
Set SPARK_HOME variable
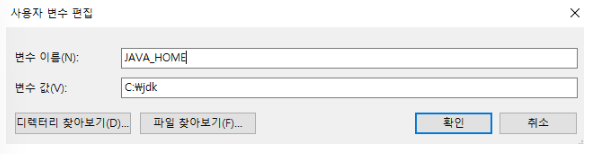
Set JAVA_HOME variable
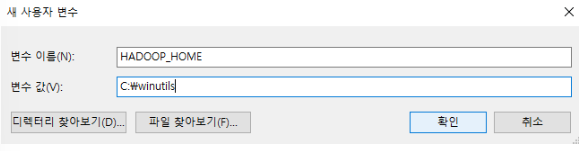
Set HADOOP_HOME variable
Edit
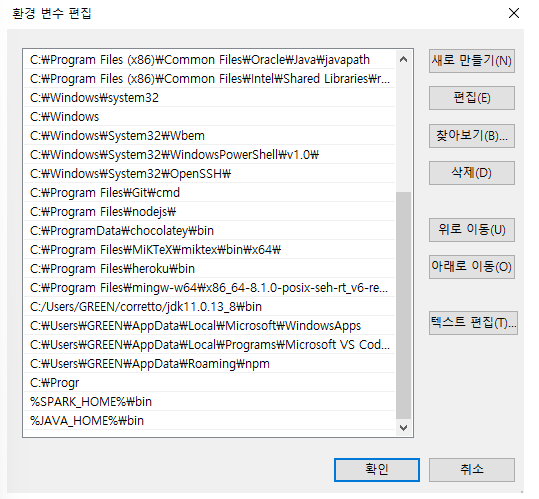
PATHvariable. Add the code below.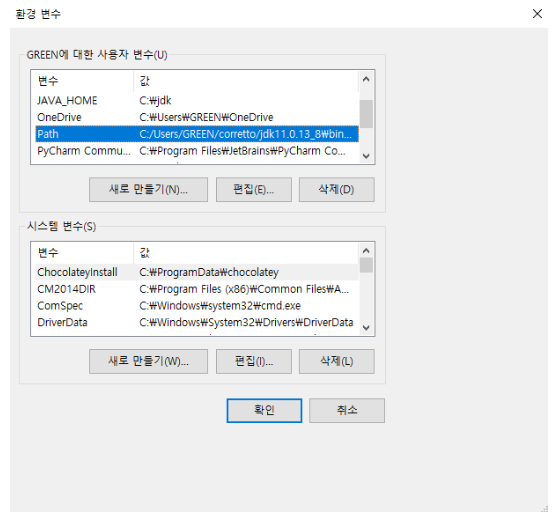
Add code below
- %SPARK_HOME%\bin
- %JAVA_HOME%\bin
Testing Spark
Open CMD file, set the path as
c:\sparkfolder- if the logo appears when input ‘spark’, success
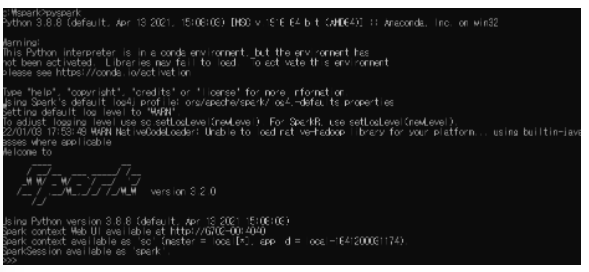
Check whether the code below works
1
2
3
4>>> rd = sc.textFile("README.md")
>>> rd.count()
109
>>>