Journal/Conference: ICASSP IEEE
Year(published year): 2019
Author: Zhong Meng, Yong Zhao, Jinyu Li, Yifan Gong
Subject: Speaker Verification
Adversarial Speaker Verification
Goal
With ASV, our goal is to learn a condition-invariant and speaker-discriminative deep hidden feature in the background DNN through adversarial multi-task learning such that a noise-robust deep embedding can be obtained from these deep features for an enrolled speaker or a test utterance.
Data
“Hey Cortana” from the Windows 10 desktop Cortana service logs.
CHiME-3: buses (BUS), in cafes (CAF), in pedestrian areas (PED), at street junctions (STR))
From the clean Cortana data, we select 6 utterances from each of the 3k speakers as the enrollment data (called “Enroll A”). We select 60k utterances from 3k target speakers and 3k impostors in Cortana dataset and mix them with CHiME-3 real noise to generate the noisy evaluation set.
Result
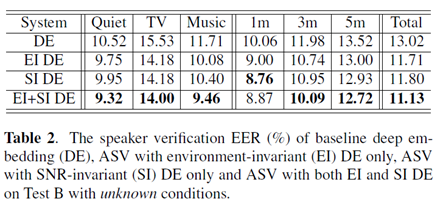
Why?
In ASV, a speaker classification network and a condition identification network are jointly trained to minimize the speaker classification loss and to mini-maximize the condition loss through adversarial multitask learning.
The target labels of the condition network can be categorical (environment types) and continuous (SNR values). With ASV, speaker-discriminative and condition-invariant deep embeddings can be extracted for both enrollment and test speech.
적대적 학습은 [22] 논문에서 먼저 적용되었는데 이 논문과의 차이점은, 두가지 소음 컨디션을 서로 다른 방법으로 막은 것(22 논문에서는 환경 개선 보다는 unlabeled 타겟 도메인 데이터를 훈련하여 적응 시키는 걸 목표로 함), 그리고 본 논문은 네트워크에 직접적으로 음성 피처를 인풋으로 넣어 훈련하는 반면, 22 논문은 i-벡터를 인풋으로 넣었고 이는 computational한 시간과 자원이 더 들어감.
** Train ASV model to adapt to noise **
Experiment
Embeddings : 인공신경망에서 원래 차원보다 저차원의 벡터로 만드는 것을 의미
원래 차원은 매우 많은 범주형 변수들로 구성되어 있고 이것들이 학습방식을 통해 저차원으로 대응됨. 수천 수만개의 고차원 변수들을 몇백개의 저차원 변수로 만들어 주고, 또한 변형된 저차원 공간에서도 충분히 카테고리형 의미를 내재함.
출처: 인공신경망(딥러닝)의 Embedding 이란 무엇일까? - 임베딩의 의미(1/3)
훈련단계에서 background DNN을 화자들을 구별하기 위해 훈련 시킴.
F = {f1 ,…, fT }, ft ∈ Rrf : deep hidden features
X = {x1 ,…, xT}, xt ∈ Rrx , t = {1 ,…, T} : input speech frames from training set to intermediate deep hidden features
Θf: parameters maps input speech frames
Mf: the hidden layers of the background DNN as a feature extractor network with parameters Θf
P(a|ft;Θy), a ∈ A : Speaker posteriors, where A is the set of all speakers in the training set
Θy: maps the deep features F to the speaker posteriors.
My: the upper layers of the background DNN as a speaker classifier network with parameters Θy
Θf and Θy are optimized by Minimizing cross entropy loss of speaker classification.
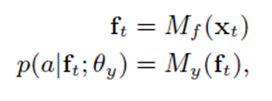
Y = {y1 ,…, yT }, yt ∈A : sequence of speaker labels aligned with X
1[.]: indicator function equals to 1 if the condition in the bracket is satisfied and 0 other wise.
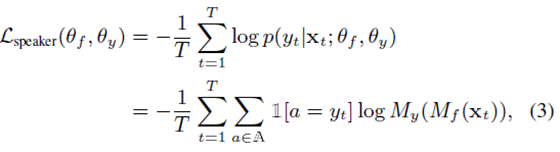
- Categorical Condition Classification Loss: to address the conditions that are characterized as a categorical variable
additional condition classification network Mc:
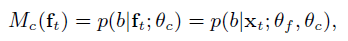
which predicts the condition posteriors p(b| ft;Θf ); b ∈ B given the deep features F from the training set
B : the set of all conditions in the training set
With a sequence of condition labels C = {c1 ,…, cT} that is aligned with X, compute the condition classification loss through cross-entropy
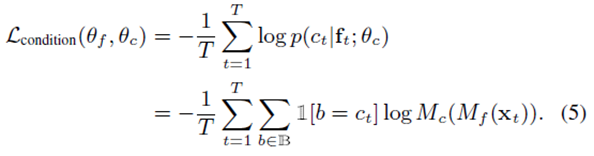
- Continuous Condition Regression Loss: an additional condition regression network Mc to predict the frame-level condition value (SNR value)
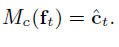
compute the condition regression loss through mean-square error
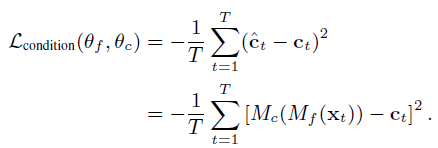
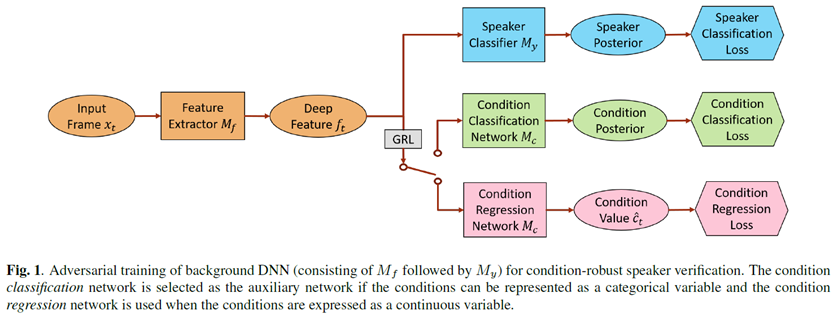
Deep feature F 를 condition invariant 하게 만들려면, 소음들 각각의 환경에서 나오는 피처들의 차이가 최대한 적어야 함.
따라서 Mf 와 Mc 는 같이 적대적으로 train 하게 되고, Θf 가 frame-level condition loss, Lcondition 을 최대화 시키고 Θc가 Lcondition을 최소화 시키는 방향으로 감.
이 둘의 경쟁은 처음에 Mc에 대한 차별성을 높여주고, speaker invariance 의 deep feature 가 Mf에 의해 만들어짐.
결국 Mf가 극단적으로 Mc가 구별하지 못하는 피처를 만드는 지점에 수렴.
그와 동시에 논문에서는 화자 차별적인 deep feature 들을 Lspeaker(Eq3)의 speaker classification 손실함수를 최소화 하면서 만듦.
최적의 파라미터를 찾는 식:
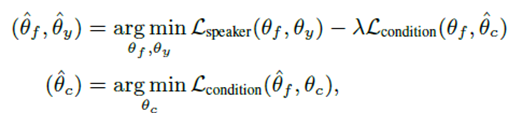
여기서 λ가 speaker classification 손실함수와 condition 함수 사이의 균형을 통제.
GRL은 forward propagation 에서 identity transform 역할을 하며 back propagation 에서 경사도를 – λ로 곱함.